Developer Reference for Intel® oneAPI Math Kernel Library for C
A newer version of this document is available. Customers should click here to go to the newest version.
Compact BLAS and LAPACK Functions
Overview
Many HPC applications rely on the application of BLAS and LAPACK operations on groups of very small matrices. While existing batch Intel® oneAPI Math Kernel Library (oneMKL) BLAS routines already provide meaningful speedup over OpenMP* loops around BLAS operations for these sizes, another customization offers potential speedup by allocating matrices in aSIMD-friendly format, thus allowing for cross-matrix vectorization in the BLAS and LAPACK routines of the Intel® oneAPI Math Kernel Library (oneMKL) calledCompact BLAS and LAPACK.
The main idea behind these compact methods is to create true SIMD computations in which subgroups of matrices are operated on with kernels that abstractly appear as scalar kernels, while registers are filled by cross-matrix vectorization.
These are the BLAS/LAPACK compact functions:
- mkl_?gemm_compact
- mkl_?trsm_compact
- mkl_?potrf_compact
- mkl_?getrfnp_compact
- mkl_?geqrf_compact
- mkl_?getrinp_compact
The compact API provides additional service functions to refactor data. Because this capability is not specific to any particular BLAS or LAPACK operation, this data manipulation can be executed once for an application's data, allowing the entire program -- consisting of any number of BLAS and LAPACK operations for which compact kernels have been written -- to be performed on the compact data without any refactoring. For applications working on data in compact format, the packing function need not be used.
See "About the Compact Format" below for more details.
Along with this new data format, the API consists of two components:
- BLAS and LAPACK Compact Kernels: The first component of the API is a compact kernel that works on matrices stored in compact format.
- Service Functions for the Compact Format: The second component of the API is a compact service function allowing for data to be factored into and out of compact format. These are:
Note that there are some Numerical Limitations for the routines mentioned above.
About the Compact Format
In compact format, for calculations involving real precision, matrices are organized in packs of size V, where V is the SIMD vector length of the underlying architecture. Each pack is a 3D-tensor with the matrix index incrementing the fastest. These packs are then loaded into registers and operated on using SIMD instructions.
The figure below demonstrates the packing of a set of four 3 x 3 real-precision matrices into compact format. The pack length for this example is V = 2, resulting in 2 compact packs.
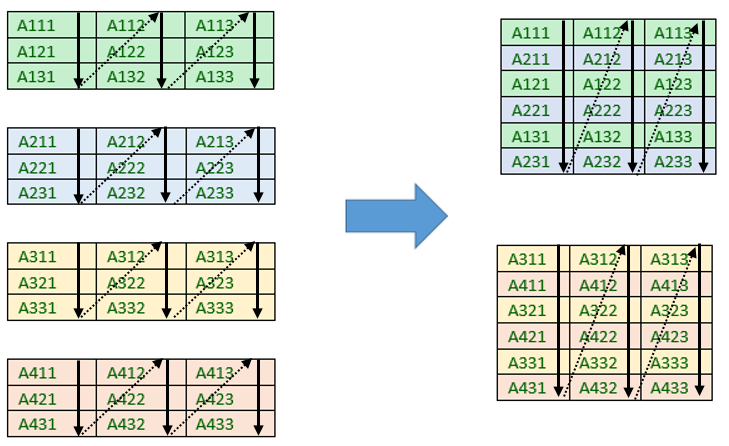
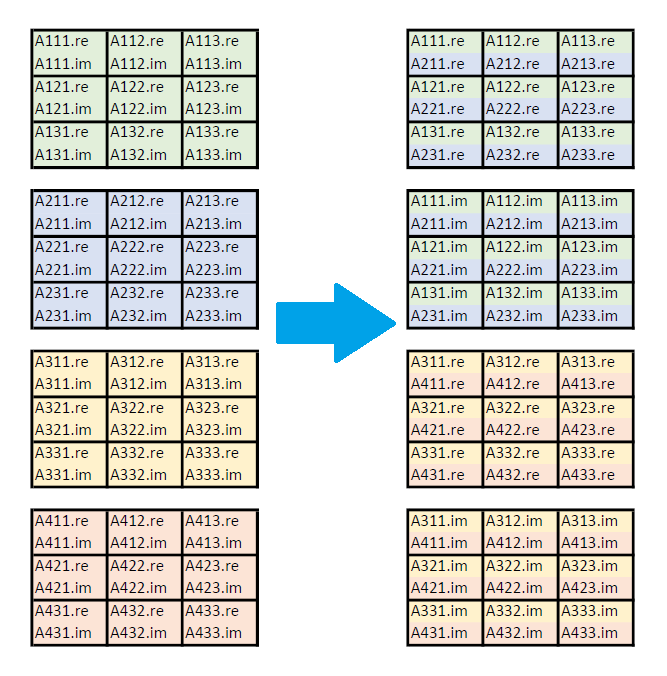
For calculations involving complex precision, the real and imaginary parts of each matrix are packed separately. In the figure below, the group of four 3 x 3 complex matrices is packed into compact format with pack length V = 2. The first pack consists of the real parts of the first two matrices, and the second pack consists of the imaginary parts of the first two matrices. Real and imaginary packs alternate in memory. This storage format means that all compact arrays can be handled as a real type.
The particular specifications (size and number) of the compact packs for the architecture and problem-precision definition are specified by an MKL_COMPACT_PACK enum type. For example: given a double-precision problem involving a group of 128 matrices working on an architecture with a 256-bit SIMD vector length, the optimal pack length is V = 4, and the number of packs is 32.
The initially-permitted values for the enum are:
- MKL_COMPACT_SSE - pack length 2 for double precision, pack length 4 for single precision.
- MKL_COMPACT_AVX - pack length 4 for double precision, pack length 8 for single precision.
- MKL_COMPACT_AVX512 - pack length 8 for double precision, pack length 16 for single precision.
For calculations involving complex precision, the pack length is the same; however, half of the packs store the real parts of matrices, and half store the imaginary parts. The means that it takes double the number of packs to store the same number of matrices.
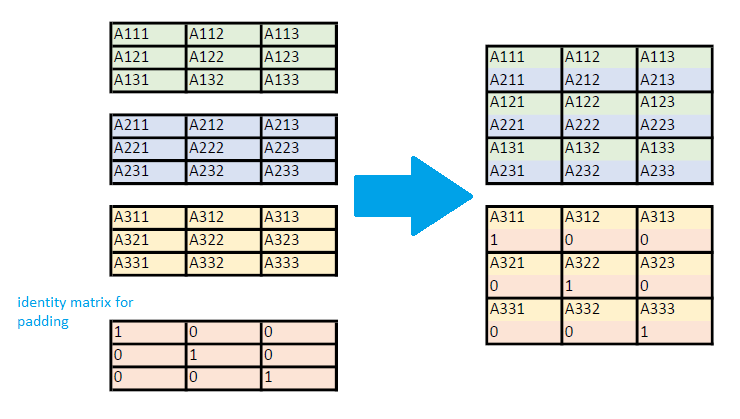
The above examples illustrate the case when the number of matrices is evenly-divisible by the pack length. When this is not the case, there will be partially-unfilled packs at the end of the memory segment, and the compact-packing routine will pad these partially unfilled packs with identity matrices, so that compact routines use only the completely-filled registers in their calculations. The next figure illustrates this padding for a group of three 3 x 3 real-precision matrices with a pack length of 2.
Before calling a BLAS or LAPACK compact function, the input data must be packed in compact format. After execution, the output data should be unpacked from this compact format, unless another compact routine will be called immediately following the first. Two service functions, mkl_?gepack_compact, and mkl_?geunpack_compact, facilitate the process of storing matrices in compact format. It is recommended that the user call the function mkl_get_format_compact before calling the mkl_?gepack_compactroutine to obtain the optimal format for performance. Advanced users can pack and unpack the matrices themselves and still use Intel® oneAPI Math Kernel Library (oneMKL) compact functions on the packed set.
Compact routines can only be called for groups of matrices that have the same dimensions, leading dimension, and storage format. For example, the routine mkl_?getrfnp_compact, which calculates the LU factorization of a group of m x n matrices without pivoting, can only be called for a group of matrices with the same number of rows (m) and the same number of columns (n). All of the matrices must also be stored in arrays with the same leading dimension, and all must be stored in the same storage format (column-major or row-major).
- mkl_?gemm_compact
Computes a matrix-matrix product of a set of compact format general matrices. - mkl_?trsm_compact
Solves a triangular matrix equation for a set of general, m x n matrices that have been stored in Compact format. - mkl_?potrf_compact
Computes the Cholesky factorization of a set of symmetric (Hermitian), positive-definite matrices, stored in Compact format (see Compact Format for details). - mkl_?getrfnp_compact
The routine computes the LU factorization, without pivoting, of a set of general, m x n matrices that have been stored in Compact format (see Compact Format). - mkl_?geqrf_compact
Computes the QR factorization of a set of general m x n, matrices, stored in Compact format (see Compact Format for details). - mkl_?getrinp_compact
Computes the inverse of a set of LU-factorized general matrices, without pivoting, stored in the compact format (see Compact Format for details). - Numerical Limitations for Compact BLAS and Compact LAPACK Routines
- mkl_?get_size_compact
Returns the buffer size, in bytes, needed to pack data in Compact format. - mkl_get_format_compact
Returns the optimal compact packing format for the architecture, needed for all compact routines. - mkl_?gepack_compact
Packs matrices from standard (row or column-major) format to Compact format. - mkl_?geunpack_compact
Unpacks matrices from Compact format to standard (row- or column-major, pointer-to-pointer) format.