Visible to Intel only — GUID: GUID-85ED609F-CA8C-4413-BE56-C71E1305CA4A
Tracing Conventional MPI Applications
Tracing Failing MPI Applications
Tracing OpenSHMEM* Applications
Tracing MPI File IO
Handling of Communicator Names
Tracing MPI Load Imbalance
Tracing User Defined Events
Configuring the Collector
Filtering Trace Data
Recording OpenMP* Regions Information
Tracing System Calls (Linux* OS)
Collecting Lightweight Statistics
Recording Source Location Information
Recording Hardware Performance Information (Linux* OS)
Recording Operating System Counters
Tracing Library Calls
Correctness Checking
Tracing Distributed Non-MPI Applications
ACTIVITY
ALTSTACK
AUTOFLUSH
CHECK
CHECK-LEAK-REPORT-SIZE
CHECK-MAX-DATATYPES
CHECK-MAX-ERRORS
CHECK-MAX-PENDING
CHECK-MAX-REPORTS
CHECK-MAX-REQUESTS
CHECK-SUPPRESSION-LIMIT
CHECK-TIMEOUT
CHECK-TRACING
CLUSTER
COMPRESS-RAW-DATA
COUNTER
CURRENT-DIR
DEADLOCK-TIMEOUT
DEADLOCK-WARNING
DEMANGLE
DETAILED-STATES
ENTER-USERCODE
ENVIRONMENT
EXTENDED-VTF
FLUSH-PID
FLUSH-PREFIX
GROUP
HANDLE-SIGNALS
INTERNAL-MPI
KEEP-RAW-EVENTS
LOGFILE-FORMAT
LOGFILE-NAME
LOGFILE-PREFIX
LOGFILE-RANK
MEM-BLOCKSIZE
MEM-FLUSHBLOCKS
MEM-INFO
MEM-MAXBLOCKS
MEM-MINBLOCKS
MEM-OVERWRITE
NMCMD
OS-COUNTER-DELAY
PCTRACE
PCTRACE-CACHE
PCTRACE-FAST
PLUGIN
PROCESS
PROGNAME
PROTOFILE-NAME
STATISTICS
STATE
STF-PROCS-PER-FILE
STF-USE-HW-STRUCTURE
STOPFILE-NAME
SYMBOL
SYNC-MAX-DURATION
SYNC-MAX-MESSAGES
SYNC-PERIOD
SYNCED-CLUSTER
SYNCED-HOST
TIME-WINDOWS (Experimental)
TIMER
TIMER-SKIP
UNIFY-COUNTERS
UNIFY-GROUPS
UNIFY-SCLS
UNIFY-SYMBOLS
VERBOSE
VT_START_PAUSED
VT_COMPRESS_TRACE
Parameter Checking
Premature Exit
Overlapping Memory
Detecting Illegal Buffer Modifications
Buffer Given to MPI Cannot Be Read or Written
Distributed Memory Checking
Illegal Memory Access
Request Handling
Datatype Handling
Buffered Sends
Deadlocks
Checking Message Transmission
Datatype Mismatches
Data Modified during Transmission
Checking Collective Operations
Freeing Communicators
Process Aggregation
Function Aggregation
Function Group Color Editor
Filtering Dialog Box
Tagging Dialog Box
Idealization Dialog Box
Imbalance Diagram Dialog Box
Trace Merge Dialog Box
Details Dialog Box
Source View Dialog
Time Interval Selection
Configuration Dialogs
Find Dialog Box
Command line for Intel® VTune™ Profiler and Intel® Advisor Dialog Box
OTF2 to STF Conversion Dialog Box
Configuration Assistant
Visible to Intel only — GUID: GUID-85ED609F-CA8C-4413-BE56-C71E1305CA4A
Choosing a Timer
A good timer has the following properties:
- High resolution (one order of magnitude higher than the resolution of the events that are to be traced)
- Low overhead
- Linearly increasing values for a long period of time (at least for the duration of a program run); in particular it should not jump forwards or backwards
Intel® Trace Collector supports several different timers. Because the quality of these timers depends on factors which are hard to predict (like specific OS bugs, available hardware and so on), you can run a test program if you want to find answers to the following questions:
What is the resolution of a timer?
What is its overhead?
How well does clock synchronization work with the default linear transformation?
If it does not work well, how often does the application have to synchronize to achieve good non-linear interpolation?
To test the quality of each timer, link the timerperformance.c sample program. The makefile already has a target vttimertest (linked against libVT and MPI) and for timertestcs (linked against libVTcs and no MPI). Use the MPI version if you have MPI, because libVT supports all the normal timers from libVTcs plus MPI_Wtime and because only the MPI version can test whether the clock increases linearly by time-stamping message exchanges.
To get a list of supported timers, run with the configuration option TIMER set to LIST. This can be done easily by setting the VT_TIMER environment variable. The subsections below have more information about possible choices, but not all of them may be available on each system.
To test an individual timer, run the binary with TIMER set to the name of the timer to be tested. It will repeatedly acquire time stamps and then for each process (vttimertest) or the current machine (timertestcs) print a histogram of the clock increments observed. A good timer has most increments close or equal to the minimum clock increment that it can measure. Bad clocks have a very high minimum clock increment (a bad resolution) or only occasionally increment by a smaller amount.
Here is the output of timertestcs one a machine with a good gettimeofday() clock:
bash$ VT_TIMER=gettimeofday ./timertestcs performance: 2323603 calls in 5.000s wall clock time = 2.152us/call = 464720 calls/s measured clock period/frequency vs. nominal: 1.000us/1.000MHz vs. 1.000us/1.000MHz overhead for sampling loop: 758957 clock ticks (= 758.958ms) for 10000000 iterations = 0 ticks/iteration average increase: 2 clock ticks = 2.244us = 0.446MHz median increase: 2 clock ticks = 2.000us = 0.500MHz < 0 ticks = 0.00s : 0 < 1 ticks = 1.00us: 0 >= 1 ticks = 1.00us: #################### 2261760 >= 501 ticks = 501.00us: 1 >= 1001 ticks = 1.00ms: 0 ...
The additional information at the top starts with the performance (and thus overhead) of the timer. The next line compares the measured clock period (calculated as elapsed wall clock time divided by clock ticks in the measurement interval) against the one that the timer is said to have; for gettimeofday() this is not useful, but for example CPU cycle counters (details below) there might be differences. Similarly, the overhead for an empty loop with a dummy function call is only relevant for a timer like CPU cycle counters with a very high precision. For that counter however the overhead caused by the loop is considerable, so during the measurement of the clock increments Intel® Trace Collector subtracts the loop overhead.
Here is an example with the CPU cycle counter as timer:
bash$ VT_TIMER=CPU ./timertestcs performance: 3432873 calls in 5.000s wall clock time = 1.457us/call = 686535 calls/s measured clock period/frequency vs. nominal: 0.418ns/2392.218MHz vs. 0.418ns/2392.356MHz overhead for sampling loop: 1913800372 clock ticks (= 800.011ms) for 10000000 iterations = 191 ticks/iteration average increase: 3476 clock ticks = 1.453us = 0.688MHz median increase: 3473 clock ticks = 1.452us = 0.689MHz < 0 ticks = 0.00s : 0 < 1 ticks = 0.42ns: 0 >= 1 ticks = 0.42ns: 0 >= 501 ticks = 209.43ns: 0 >= 1001 ticks = 418.44ns: 0 >= 1501 ticks = 627.45ns: 0 >= 2001 ticks = 836.46ns: 0 >= 2501 ticks = 1.05us: 0 >= 3001 ticks = 1.25us: #################### 3282286 >= 3501 ticks = 1.46us: 587 >= 4001 ticks = 1.67us: 8 >= 4501 ticks = 1.88us: 1 >= 5001 ticks = 2.09us: 869
Testing whether the timer increases linearly is more difficult. It is done by comparing the send and receive time stamps of ping-pong message exchanges between two processes after Intel® Trace Collector has applied its time synchronization algorithm to them: the algorithm will scale and shift the time stamps based on the assumption that data transfer in both directions is equally fast. So if the synchronization works, the average difference between the duration of messages in one direction minus the duration of the replies has to be zero. The visualization of the trace timertest.stf should show equilateral triangles.
If the timer increases linearly, then one set of correction parameters applies to the whole trace. If it does not, then clock synchronization might be good in one part of the trace and bad in another or even more obvious, be biased towards one process in one part with a positive difference and biased towards the other in another part with a negative difference. In either case tweaking the correction parameters would fix the time stamps of one data exchange, but just worsen the time stamps of another.
When running the MPI vttimertest with two or more processes it will do a short burst of data exchanges between each pair of processes, then sleep for 10 seconds. This cycle is repeated for a total runtime of 30 seconds. This total duration can be modified by giving the number of seconds as command line parameter. Another argument on the command line also overrides the duration of the sleep. After MPI_Finalize() the main process will read the resulting trace file and print statistics about the message exchanges: for each pair of processes and each burst of message exchanges, the average offset between the two processes is given. Ideally these offsets will be close to zero, so at the end the pair of processes with the highest absolute clock offset between sender and receiver will be printed:
maximum clock offset during run: 1 <-> 2 374.738ns (latency 6.752us) to produce graph showing trace timing, run: gnuplot timertest.gnuplot
If the value is much smaller than the message latency, then clock correction worked well throughout the whole program run and can be trusted to accurately time individual messages.
Running the test program for a short interval is useful to test whether the NTP-like message exchange works in principle, but to get realistic results you have to run the test for several minutes. If a timer is used which is synchronized within a node, then you should run with one process per node because Intel® Trace Collector would use the same clock correction for all processes on the same node anyway. Running with multiple processes per node in this case would only be useful to check whether the timer really is synchronized within the node.
To better understand the behavior of large runs, several data files and one command file for gnuplot are generated. Running gnuplot as indicated above will produce several graphs:
| Graph | Description |
|---|---|
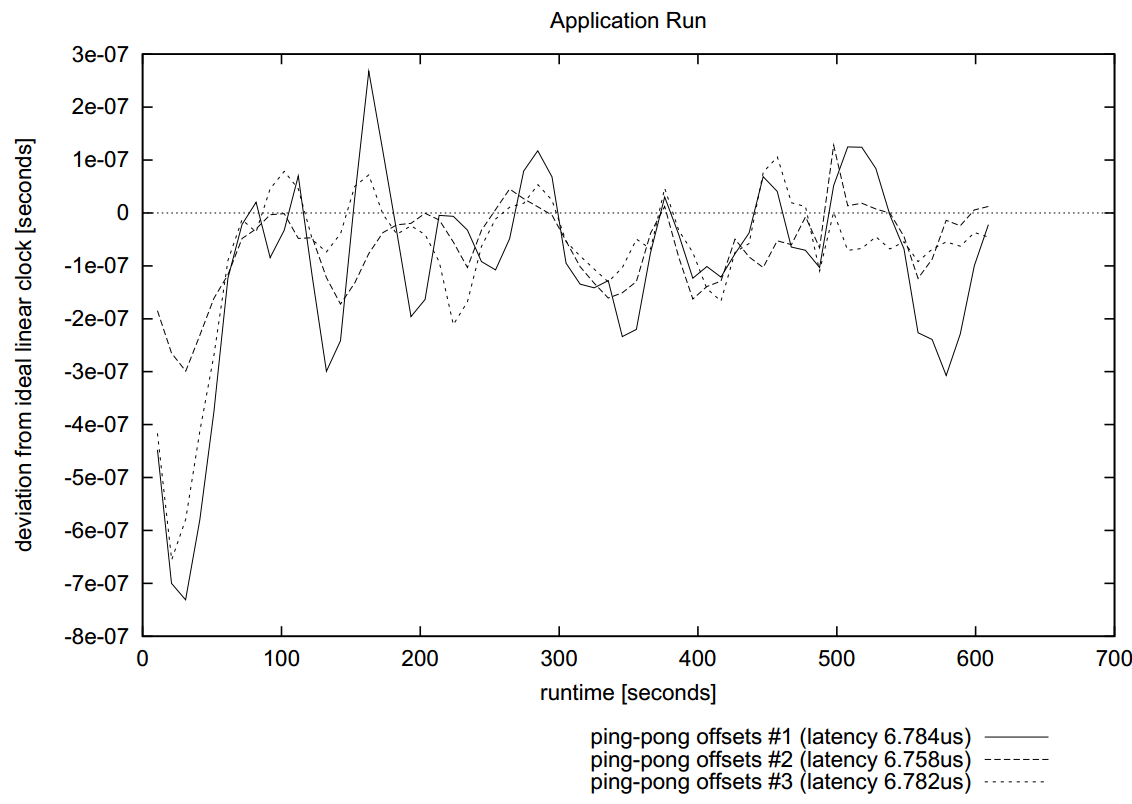
| Application Run | Connects the offsets derived from the application's message exchanges with straight lines: it shows whether the deviation from the expected zero offset is linear or not; it can be very noisy because outliers are not removed |
| Clock Transformation | Shows the clock samples that Intel® Trace Collector itself took at the application start, end and in VT_timesync() and what the transformation from local clock ticks to global clock ticks looks like |
| Interpolation Error | Compares a simple linear interpolation of Intel® Trace Collector's sample data against the non-linear constrained spline interpolation: at each sample point, the absolute delta between measured time offset and the corresponding interpolated value is shown above the x-axis (for linear interpolation) and below (for splines) |
| Raw Clock Samples | For the first three message exchanges of each process, the raw clock samples taken by Intel® Trace Collector are shown in two different ways: all samples and just those actually used by Intel® Trace Collector after removing outliers. In these displays the height of the error bars corresponds to the round-trip time of each sample measured on the master. If communication works reliably, most samples should have the same round-trip time. |
The graphs use different coordinate systems: the first one uses global time for both axis; the latter two have local time on the x-axis and a delta in global time on the y-axis. Thus although the same error will show up in all of them, in one graph it will appear as a deviation for example below the x-axis and in the other above it.
Also, the latter two graphs are only useful if Intel® Trace Collector really uses non-linear interpolation which is not the case if all intermediate clock samples are skipped: although the test program causes a clock synchronization before each message exchange by calling VT_timesync(), at the same time it tells Intel® Trace Collector to not use those results and thus simulates a default application run where synchronization is only done at the start and end.
This can be overridden by setting the TIMER-SKIP configuration option or VT_TIMER_SKIP environment variable to a small integer value: it chooses how often the result of a VT_timesync() is ignored before using a sample for non-linear clock correction. The skipped samples serve as checks that the interpolation is sound.
In the following figures the test program was run using the CPU timer source, with a total runtime of 10 minutes and skipping 5 samples:
bash$ VT_TIMER_SKIP=5 VT_TIMER=CPU mpirun -np 4 timertest 600 ... [0 (node0)] performance: 115750510 calls in 5.000s wall clock time = 43.197ns/call = 23149574 calls/s ... 0. recording messages 0 <-> 1... 0. recording messages 0 <-> 2... 0. recording messages 0 <-> 3... 0. recording messages 1 <-> 2... 0. recording messages 1 <-> 3... 0. recording messages 2 <-> 3... 1. recording messages 0 <-> 1... ... maximum clock offset during run: 0 <-> 1 -1.031us (latency 6.756us)
The application run in Figure 5.1 below shows that in general Intel® Trace Collector managed to keep the test results inside a range of plus-minus 1μs although it did not use all the information collected with VT_timesync(). The clock transformation function in Figure 5.2 is non-linear for all three child processes and interpolates the intermediate samples well. Using a linear interpolation between start and end would have led to deviations in the middle of more than 16 μs. Also, the constrained spline interpolation is superior compared to a simple linear interpolation between the sample points (Figure 5.3).
Figure 5.1 CPU Timer: Application Run with Non-linear Clock Correction