Visible to Intel only — GUID: GUID-8BA55F4A-D5AE-4E27-8C25-058B68D280A4
Use Microsoft Visual Studio* Solution Explorer
Create a New Project
Perform Common Tasks with Microsoft Visual Studio*
Select a Version of the Intel® Fortran Compiler
Use Visual Studio* IDE Automation Objects
Specify Fortran File Extensions
Understand Solutions, Projects, and Configurations
Navigate Programmatic Components in a Fortran File
Specify Path, Library, and Include Directories
Set Compiler Options in the Microsoft Visual Studio* IDE Property Pages
Supported Build Macros
Use Manifests
Use Intel® Libraries with Microsoft Visual Studio*
Use Source Editor Enhancements in Microsoft Visual Studio*
Create the Executable Program
Convert and Copy Projects
About Fortran Project Types
Dialog Box Help
Understand Project Types
Specify Project Types with ifx Command Options
Use Fortran Console Application Projects
Use Fortran Standard Graphics Application Projects
Use Fortran QuickWin Application Projects
Use Fortran Windowing Application Projects
Use Fortran Static Library Projects
Use Fortran Dynamic-Link Library Projects
Use the Console
Create Fortran Applications That Use Windows Features
Alphabetical Option List
General Rules for Compiler Options
What Appears in the Compiler Option Descriptions
Optimization Options
Advanced Optimization Options
Code Generation Options
Offload Compilation, OpenMP*, and Parallel Processing Options
Interprocedural Optimization Options
Profile Guided Optimization Options
Optimization Report Options
Floating-Point Options
Inlining Options
Output, Debug, and Precompiled Header Options
Preprocessor Options
Component Control Options
Language Options
Data Options
Compiler Diagnostic Options
Compatibility Options
Linking or Linker Options
Miscellaneous Options
Deprecated and Removed Compiler Options
Display Option Information
Alternate Compiler Options
ansi-alias, Qansi-alias
coarray, Qcoarray
coarray-config-file, Qcoarray-config-file
coarray-num-images, Qcoarray-num-images
fvec-allow-scalar-stores, Qvec-allow-scalar-stores
fvec-peel-loops, Qvec-peel-loops
fvec-remainder-loops, Qvec-remainder-loops
fvec-with-mask, Qvec-with-mask
heap-arrays
mno-gather, Qgather-
mno-scatter, Qscatter-
pad, Qpad
qmkl, Qmkl
qmkl-ilp64, Qmkl-ilp64
qmkl-sycl-impl, Qmkl-sycl-impl
qopt-dword-index-for-array-of-structs, Qopt-dword-index-for-array-of-structs
qopt-dynamic-align, Qopt-dynamic-align
qopt-for-throughput, Qopt-for-throughput
qopt-matmul, Qopt-matmul
qopt-mem-layout-trans, Qopt-mem-layout-trans
qopt-multiple-gather-scatter-by-shuffles, Qopt-multiple-gather-scatter-by-shuffles
qopt-prefetch, Qopt-prefetch
qopt-prefetch-distance, Qopt-prefetch-distance
qopt-prefetch-loads-only, Qopt-prefetch-loads-only
qopt-streaming-stores, Qopt-streaming-stores
qopt-zmm-usage, Qopt-zmm-usage
qoverride-limits, Qoverride-limits
reentrancy
safe-cray-ptr, Qsafe-cray-ptr
unroll, Qunroll
vec, Qvec
vec-threshold, Qvec-threshold
vecabi, Qvecabi
device-math-lib
fiopenmp, Qiopenmp
flink-huge-device-code
fopenmp, Qopenmp
fopenmp-concurrent-host-device-compile, Qopenmp-concurrent-host-device-compile
fopenmp-declare-target-scalar-defaultmap, Qopenmp-declare-target-scalar-defaultmap
fopenmp-default-allocator, Qopenmp-default-allocator
fopenmp-device-code-split, Qopenmp-device-code-split
fopenmp-device-lib
fopenmp-do-concurrent-maptype-modifier, Qopenmp-do-concurrent-maptype-modifier
fopenmp-max-parallel-link-jobs, Qopenmp-max-parallel-link-jobs
fopenmp-offload-mandatory, Qopenmp-offload-mandatory
fopenmp-target-buffers, Qopenmp-target-buffers
fopenmp-target-default-sub-group-size, Qopenmp-target-default-sub-group-size
fopenmp-target-do-concurrent, Qopenmp-target-do-concurrent
fopenmp-target-loopopt, Qopenmp-target-loopopt
fopenmp-target-simd, Qopenmp-target-simd
fopenmp-targets, Qopenmp-targets
fsycl
fsycl-dead-args-optimization
fsycl-device-code-split
fsycl-device-lib
fsycl-instrument-device-code
fsycl-targets
ftarget-compile-fast
ftarget-register-alloc-mode, Qtarget-register-alloc-mode
nolibsycl
parallel, Qparallel
qopenmp, Qopenmp
qopenmp-link
qopenmp-simd, Qopenmp-simd
qopenmp-stubs, Qopenmp-stubs
qopenmp-threadprivate, Qopenmp-threadprivate
Xopenmp-target
Xsycl-target
ffp-accuracy, Qfp-accuracy
fimf-absolute-error, Qimf-absolute-error
fimf-accuracy-bits, Qimf-accuracy-bits
fimf-arch-consistency, Qimf-arch-consistency
fimf-domain-exclusion, Qimf-domain-exclusion
fimf-max-error, Qimf-max-error
fimf-precision, Qimf-precision
fimf-use-svml, Qimf-use-svml
fltconsistency
fma, Qfma
fp-model, fp
fp-speculation, Qfp-speculation
fpe
fpe-all
ftz, Qftz
Ge
pc, Qpc
prec-div, Qprec-div
recursive
align
auto
auto-scalar, Qauto-scalar
convert
double-size
dyncom, Qdyncom
falign-functions, Qfnalign
fcommon
fmaintain-32-byte-stack-align, Qmaintain-32-byte-stack-align
fmath-errno
fpconstant
fpic
fpie
fstack-protector
fstack-security-check
fstrict-overflow, Qstrict-overflow
fvisibility
fzero-initialized-in-bss, Qzero-initialized-in-bss
Gs
GS
init, Qinit
intconstant
integer-size
mcmodel
real-size
save, Qsave
zero, Qzero
4Nportlib, 4Yportlib
Bdynamic
Bstatic
Bsymbolic
Bsymbolic-functions
cxxlib
dbglibs
dll
dynamic-linker
extlnk
F (Windows*)
fortlib
fuse-ld
l
L
libs
link
map
MD
MT
nodefaultlibs
nofor-main
no-intel-lib, Qno-intel-lib
nostartfiles
nostdlib
pie
pthread
shared
shared-intel
shared-libgcc
static
static-intel
static-libgcc
static-libstdc++
T
threads
v
Wa
winapp
Wl
Wp
Xlinker
Create Libraries
Call Library Routines
Comparison of Intel® Fortran Compiler and Windows API Routines
Specify Consistent Library Types on Windows
Redistribute Libraries When Deploying Applications
Resolve References to Shared Libraries
Redistributable Library Considerations
Store Object Code in Static Libraries
Store Routines in Shareable Libraries
Use Windows API Routines
Math Libraries
Logical Devices
Physical Devices on Windows
Types of I/O Statements
Forms of I/O Statements
Assign Files to Logical Units
File Organization
Internal Files and Scratch Files
File Access and File Structure
File Records
Record Types
Record Length
Record Access
Record Transfer
Specify Default Pathnames and File Names
Open Files: OPEN Statement
Obtain File Information: INQUIRE Statement
Close Files: CLOSE Statement
Record I/O Statement Specifiers
File Sharing on Linux
Specify the Initial Record Position
Advancing and Nonadvancing Record I/O
Use USEROPEN to Pass Control To a Routine
Microsoft Fortran PowerStation Compatible Files
Use Asynchronous I/O
Mixed-Language Issues
Call Subprograms from the Main Program on Windows
Pass Arguments in Mixed-Language Programming
Stack Considerations in Calling Conventions on Windows
Naming Conventions
C/C++ Naming Conventions
Compile and Link Intel® Fortran and C/C++ Programs
Build Intel® Fortran and C Mixed-Language Programs on Windows
Understand Runtime Errors
Runtime Default Error Processing
Runtime Message Display and Format
Values Returned at Program Termination
Methods of Handling Errors
Locate Runtime Errors
List of Runtime Error Messages
Signal Handling on Linux*
Override the Default Runtime Library Exception Handler
Advanced Exception and Termination Handling
New Features
Language Reference Conventions
Program Elements and Source Forms
Data Types, Constants, and Variables
Expressions and Assignment Statements
Specification Statements
Dynamic Allocation
Execution Control
Program Units and Procedures
Intrinsic Procedures
Data Transfer I/O Statements
I/O Formatting
File Operation I/O Statements
Compilation Control Lines and Statements
Directive Enhanced Compilation
Scope and Association
Deleted and Obsolescent Language Features
Additional Language Features
Additional Character Sets
Data Representation Models
Library Modules and Runtime Library Routines
Summary of Language Extensions
A to Z Reference
Glossary
Main Program
Procedure Characteristics
Modules and Module Procedures
Intrinsic Modules
Block Data Program Units Overview
Functions, Subroutines, and Statement Functions
External Procedures
Internal Procedures
Argument Association in Procedures
Procedure Interfaces
Interoperability of Procedures and Procedure Interfaces
Procedure Pointers
Optional Arguments
Array Arguments
Pointer Arguments
Passed-Object Dummy Arguments
Assumed-Length Character Arguments
Character Constant and Hollerith Arguments
Alternate Return Arguments
Dummy Procedure Arguments
Coarray Dummy Arguments
References to Generic Procedures
References to Non-Fortran Procedures
Advance Specifier (ADVANCE=)
Asynchronous Specifier (ASYNCHRONOUS=)
Blank Specifier (BLANK=)
Branch Specifiers (END=, EOR=, ERR=)
Character Count Specifier (SIZE=)
Decimal Specifier (DECIMAL=)
Delimiter Specifier (DELIM=)
Format Specifier (FMT=)
Identification Specifier (ID=)
I/O Message Specifier (IOMSG=)
I/O Status Specifier (IOSTAT=)
Namelist Specifier (NML=)
Padding Specifier (PAD=)
Position Specifier (POS=)
Record Specifier (REC=)
Rounding Specifier (ROUND=)
Sign Specifier (SIGN=)
Unit Specifier (UNIT=)
INQUIRE: ACCESS Specifier
INQUIRE: ACTION Specifier
INQUIRE: ASYNCHRONOUS Specifier
INQUIRE: BINARY Specifier
INQUIRE: BLANK Specifier
INQUIRE: BLOCKSIZE Specifier
INQUIRE: BUFFERED Specifier
INQUIRE: CARRIAGECONTROL Specifier
INQUIRE: CONVERT Specifier
INQUIRE: DECIMAL Specifier
INQUIRE: DELIM Specifier
INQUIRE: DIRECT Specifier
INQUIRE: ENCODING Specifier
INQUIRE: EXIST Specifier
INQUIRE: FORM Specifier
INQUIRE: FORMATTED Specifier
INQUIRE: ID Specifier
INQUIRE: IOFOCUS Specifier
INQUIRE: IOLENGTH Specifier
INQUIRE: IOMSG Specifier
INQUIRE: IOSTAT Specifier
INQUIRE: MODE Specifier
INQUIRE: NAME Specifier
INQUIRE: NAMED Specifier
INQUIRE: NEXTREC Specifier
INQUIRE: NUMBER Specifier
INQUIRE: OPENED Specifier
INQUIRE: ORGANIZATION Specifier
INQUIRE: PAD Specifier
INQUIRE: PENDING Specifier
INQUIRE: POS Specifier
INQUIRE: POSITION Specifier
INQUIRE: READ Specifier
INQUIRE: READWRITE Specifier
INQUIRE: RECL Specifier
INQUIRE: RECORDTYPE Specifier
INQUIRE: ROUND Specifier
INQUIRE: SEQUENTIAL Specifier
INQUIRE: SHARE Specifier
INQUIRE: SIGN Specifier
INQUIRE: SIZE Specifier
INQUIRE: STREAM Specifier
INQUIRE: UNFORMATTED Specifier
INQUIRE: WRITE Specifier
OPEN: ACCESS Specifier
OPEN: ACTION Specifier
OPEN: ASSOCIATEVARIABLE Specifier
OPEN: ASYNCHRONOUS Specifier
OPEN: BLANK Specifier
OPEN: BLOCKSIZE Specifier
OPEN: BUFFERCOUNT Specifier
OPEN: BUFFERED Specifier
OPEN: CARRIAGECONTROL Specifier
OPEN: CONVERT Specifier
OPEN: DECIMAL Specifier
OPEN: DEFAULTFILE Specifier
OPEN: DELIM Specifier
OPEN: DISPOSE Specifier
OPEN: ENCODING Specifier
OPEN: FILE Specifier
OPEN: FORM Specifier
OPEN: IOFOCUS Specifier
OPEN: MAXREC Specifier
OPEN: MODE Specifier
OPEN: NAME Specifier
OPEN: NEWUNIT Specifier
OPEN: NOSHARED Specifier
OPEN: ORGANIZATION Specifier
OPEN: PAD Specifier
OPEN: POSITION Specifier
OPEN: READONLY Specifier
OPEN: RECL Specifier
OPEN: RECORDSIZE Specifier
OPEN: RECORDTYPE Specifier
OPEN: ROUND Specifier
OPEN: SHARE Specifier
OPEN: SHARED Specifier
OPEN: SIGN Specifier
OPEN: STATUS Specifier
OPEN: TITLE Specifier
OPEN: TYPE Specifier
OPEN: USEROPEN Specifier
FORTRAN 66 Interpretation of the EXTERNAL Statement
Alternative Syntax for the PARAMETER Statement
Alternative Syntax for Binary, Octal, and Hexadecimal Constants
Alternative Syntax for a Record Specifier
Alternative Syntax for the DELETE Statement
Alternative Form for Namelist External Records
Record Structures
Language Extensions: Source Forms
Language Extensions: Names
Language Extensions: Character Sets
Language Extensions: Intrinsic Data Types
Language Extensions: Constants
Language Extensions: Expressions and Assignment
Language Extensions: Specification Statements
Language Extensions: Execution Control
Language Extensions: Compilation Control Lines and Statements
Language Extensions: Built-In Functions
Language Extensions: I/O Statements
Language Extensions: I/O Formatting
Language Extensions: File Operation Statements
Language Extensions: Compiler Directives
Language Extensions: Intrinsic Procedures
Language Extensions: Additional Language Features
Language Extensions: Runtime Library Routines
Language Summary Tables
A to B
C to D
E to F
G
H to I
J to L
M to N
O to P
Q to R
S
T to Z
POSIX* Library Routines
Automation Server and Component Object Model Library Routines
National Language Support Library Routines
QuickWin Library Routines
Graphics Library Routines
Serial Port I/O Library Routines
Dialog Library Routines
Statements for Program Unit Calls and Definitions
Statements Affecting Variables
Statements and Intrinsic Functions for Input and Output
Compiler Directives
Program Control Statements
Inquiry Intrinsic Functions
Random Number Intrinsic Procedures
Atomic Intrinsic Subroutines
Collective Intrinsic Subroutines
Date and Time Intrinsic Subroutines
Keyboard and Speaker Library Routines
Statements and Intrinsic Procedures for Memory Allocation and Deallocation
Intrinsic Functions for Arrays and Coarrays
Intrinsic Functions for Numeric and Type Conversion
Trigonometric, Bessel, Exponential, Root, and Logarithmic Intrinsic Procedures
Intrinsic Functions for Floating-Point Inquiry and Control
Character Intrinsic Functions
Intrinsic Procedures for Bit Operation and Representation
QuickWin Library Routines Summary
Graphics Library Routines Summary
Portability Library Routines
National Language Support Library Routines Summary
POSIX* Library Procedures Summary
Dialog Library Routines Summary
COM and Automation Library Routines
Miscellaneous Runtime Library Routines
ABORT
ABS
ABSTRACT INTERFACE
ACCEPT
ACCESS Function
ACHAR
ACOS
ACOSD
ACOSH
ADJUSTL
ADJUSTR
AIMAG
AINT
ALARM
ALIAS Directive
ALIGNED Clause
ALL
ALLOCATABLE
ALLOCATE Clause
ALLOCATE Directive
ALLOCATE Statement
ALLOCATED
ALLOCATORS
AND
ANINT
ANY
ASIN
ASIND
ASINH
ASSIGN - Label Assignment
Assignment(=) - Defined Assignment
Assignment - Intrinsic Computational
ASSOCIATE
ASSOCIATED
ASSUME
ASSUME_ALIGNED
ASSUMES Directive for OpenMP
ASSUMPTION Clause
ASYNCHRONOUS
ATAN
ATAN2
ATAN2D
ATAND
ATANH
ATOMIC
ATOMIC_ADD
ATOMIC_AND
ATOMIC_CAS
ATOMIC_DEFINE
ATOMIC_FETCH_ADD
ATOMIC_FETCH_AND
ATOMIC_FETCH_OR
ATOMIC_FETCH_XOR
ATOMIC_OR
ATOMIC_REF
ATOMIC_XOR
ATTRIBUTES
AUTOMATIC
BACKSPACE
BADDRESS
BARRIER
BEEPQQ
BESJ0, BESJ1, BESJN, BESY0, BESY1, BESYN
BESSEL_J0
BESSEL_J1
BESSEL_JN
BESSEL_Y0
BESSEL_Y1
BESSEL_YN
BGE
BGT
BIC, BIS
BIND
BIT
BIT_SIZE
BLE
BLOCK
BLOCK DATA
BLOCK_LOOP and NOBLOCK_LOOP
BLT
BSEARCHQQ
BTEST
BYTE
ATTRIBUTES ALIAS
ATTRIBUTES ALIGN
ATTRIBUTES ALLOCATABLE
ATTRIBUTES ALLOW_NULL
ATTRIBUTES C and STDCALL
ATTRIBUTES CODE_ALIGN
ATTRIBUTES CONCURRENCY_SAFE
ATTRIBUTES CVF
ATTRIBUTES DECORATE
ATTRIBUTES DEFAULT
ATTRIBUTES DLLEXPORT and DLLIMPORT
ATTRIBUTES EXTERN
ATTRIBUTES INLINE, NOINLINE, and FORCEINLINE
ATTRIBUTES IGNORE_LOC
ATTRIBUTES MIXED_STR_LEN_ARG and NOMIXED_STR_LEN_ARG
ATTRIBUTES NO_ARG_CHECK
ATTRIBUTES NOCLONE
ATTRIBUTES REFERENCE and VALUE
ATTRIBUTES VARYING
ATTRIBUTES VECTOR
C_ASSOCIATED
C_F_POINTER
C_F_PROCPOINTER
C_F_STRPOINTER
C_FUNLOC
C_LOC
C_SIZEOF
CACHESIZE
CALL
CANCEL
CANCELLATION POINT
CASE
CDFLOAT
CEILING
CFI_address
CFI_allocate
CFI_deallocate
CFI_establish
CFI_is_contiguous
CFI_section
CFI_select_part
CFI_setpointer
CHANGEDIRQQ
CHANGEDRIVEQQ
CHANGE TEAM and END TEAM
CHAR
CHARACTER
CHDIR
CHMOD
CLASS
CLEARSTATUSFPQQ
CLOCK
CLOCKX
CLOSE
CMPLX
CO_BROADCAST
CO_MAX
CO_MIN
CO_REDUCE
CO_SUM
CODE_ALIGN
CODIMENSION
COLLAPSE Clause
COMMAND_ARGUMENT_COUNT
COMMITQQ
COMMON
COMPILER_OPTIONS
COMPILER_VERSION
COMPLEX Statement
COMPLINT, COMPLREAL, COMPLLOG
CONJG
CONTAINS
CONTIGUOUS
CONTINUE
COPYIN Clause
COPYPRIVATE Clause
COS
COSD
COSH
COSHAPE
COTAN
COTAND
COUNT
CPU_TIME
CRITICAL Directive
CRITICAL Statement
CSHIFT
CSMG
CTIME
CYCLE
DATA
DATE Intrinsic Procedure
DATE Portability Routine
DATE4
DATE_AND_TIME
DBESJ0, DBESJ1, DBESJN, DBESY0, DBESY1, DBESYN
DBLE
DCLOCK
DCMPLX
DEALLOCATE
DECLARE and NODECLARE
DECLARE MAPPER
DECLARE REDUCTION
DECLARE SIMD
DECLARE TARGET
DECLARE VARIANT
DECODE
DEFAULT Clause
DEFINE and UNDEFINE
DEFINE FILE
DELDIRQQ
DELETE
DELFILESQQ
DEPEND Clause
DEPOBJ
DEVICE Clause
DEVICE_TYPE Clause
DFLOAT
DFLOATI, DFLOATJ, DFLOATK
DIGITS
DIM
DIMENSION
DISPATCH
DISTRIBUTE
DISTRIBUTE PARALLEL DO
DISTRIBUTE PARALLEL DO SIMD
DISTRIBUTE POINT
DISTRIBUTE SIMD
DNUM
DO Directive
DO Statement
DO CONCURRENT
DO SIMD
DO WHILE
DOT_PRODUCT
DOUBLE COMPLEX
DOUBLE PRECISION
DPROD
DRAND, DRANDM
DRANSET
DREAL
DSHIFTL
DSHIFTR
DTIME
ELEMENTAL
ELSE Directive
ELSE Statement
ELSEIF Directive
ELSE IF
ELSE WHERE
ENCODE
END
END DO
ENDIF Directive
END IF
ENDFILE
END FORALL
END INTERFACE
END TYPE
END WHERE
ENTRY
EOF
EOSHIFT
EPSILON
EQUIVALENCE
ERF
ERFC
ERFC_SCALED
ERROR Directive for OpenMP
ERRSNS
ESTABLISHQQ
ETIME
EVENT POST and EVENT WAIT
EVENT_QUERY
EXECUTE_COMMAND_LINE
EXIT Statement
EXIT Subroutine
EXP
EXP10
EXPONENT
EXTENDS_TYPE_OF
EXTERNAL
F_C_STRING
FAIL IMAGE
FAILED_IMAGES
FDATE
FGETC
FINAL Clause
FINAL Statement
FIND
FINDLOC
FINDFILEQQ
FIRSTPRIVATE
FIXEDFORMLINESIZE
FLOAT
FLOOR
FLUSH Directive
FLUSH Statement
FLUSH Subroutine
FMA and NOFMA
FOR_DESCRIPTOR_ASSIGN
FOR_GET_FPE
FOR_IFCORE_VERSION
FOR_IFPORT_VERSION
FOR_LFENCE
FOR_MFENCE
for_rtl_finish_
for_rtl_init_
FOR_SET_FPE
FOR_SET_FTN_ALLOC
FOR_SET_REENTRANCY
FOR_SFENCE
FORALL
FORMAT
FORM TEAM
FP_CLASS
FPUTC
FRACTION
FREE
FREEFORM and NOFREEFORM
FSEEK
FSTAT
FTELL, FTELLI8
FULLPATHQQ
FUNCTION
GAMMA
GENERIC
GERROR
GETARG
GETC
GETCHARQQ
GET_COMMAND
GET_COMMAND_ARGUMENT
GETCONTROLFPQQ
GETCWD
GETDAT
GETDRIVEDIRQQ
GETDRIVESIZEQQ
GETDRIVESQQ
GETENV
GET_ENVIRONMENT_VARIABLE
GETENVQQ
GETEXCEPTIONPTRSQQ
GETFILEINFOQQ
GETGID
GETLASTERROR
GETLASTERRORQQ
GETLOG
GETPID
GETPOS, GETPOSI8
GETSTATUSFPQQ
GETSTRQQ
GET_TEAM
GETTIM
GETTIMEOFDAY
GETUID
GMTIME
GOTO - Assigned
GOTO - Computed
GOTO - Unconditional
GROUPPRIVATE
HINT
HOSTNAM
HUGE
HYPOT
IACHAR
IALL
IAND
IANY
IARGC
IBCHNG
IBCLR
IBITS
IBSET
ICHAR
IDATE Intrinsic Procedure
IDATE Portability Routine
IDATE4
IDENT
IDFLOAT
IEEE_CLASS
IEEE_COPY_SIGN
IEEE_FLAGS
IEEE_FMA
IEEE_GET_FLAG
IEEE_GET_HALTING_MODE
IEEE_GET_MODES
IEEE_GET_ROUNDING_MODE
IEEE_GET_STATUS
IEEE_GET_UNDERFLOW_MODE
IEEE_HANDLER
IEEE_INT
IEEE_IS_FINITE
IEEE_IS_NAN
IEEE_IS_NEGATIVE
IEEE_IS_NORMAL
IEEE_LOGB
IEEE_MAX
IEEE_MAX_MAG
IEEE_MAX_NUM
IEEE_MAX_NUM_MAG
IEEE_MIN
IEEE_MIN_MAG
IEEE_MIN_NUM
IEEE_MIN_NUM_MAG
IEEE_NEXT_AFTER
IEEE_NEXT_DOWN
IEEE_NEXT_UP
IEEE_QUIET_EQ
IEEE_QUIET_GE
IEEE_QUIET_GT
IEEE_QUIET_LE
IEEE_QUIET_LT
IEEE_QUIET_NE
IEEE_REAL
IEEE_REM
IEEE_RINT
IEEE_SCALB
IEEE_SELECTED_REAL_KIND
IEEE_SET_FLAG
IEEE_SET_HALTING_MODE
IEEE_SET_MODES
IEEE_SET_ROUNDING_MODE
IEEE_SET_STATUS
IEEE_SET_UNDERFLOW_MODE
IEEE_SIGNALING_EQ
IEEE_SIGNALING_GE
IEEE_SIGNALING_GT
IEEE_SIGNALING_LE
IEEE_SIGNALING_LT
IEEE_SIGNALING_NE
IEEE_SIGNBIT
IEEE_SUPPORT_DATATYPE
IEEE_SUPPORT_DENORMAL
IEEE_SUPPORT_DIVIDE
IEEE_SUPPORT_FLAG
IEEE_SUPPORT_HALTING
IEEE_SUPPORT_INF
IEEE_SUPPORT_IO
IEEE_SUPPORT_NAN
IEEE_SUPPORT_ROUNDING
IEEE_SUPPORT_SQRT
IEEE_SUPPORT_STANDARD
IEEE_SUPPORT_SUBNORMAL
IEEE_SUPPORT_UNDERFLOW_CONTROL
IEEE_UNORDERED
IEEE_VALUE
IEOR
IERRNO
IF - Arithmetic
IF - Logical
IF Clause
IF Construct
IF Directive Construct
IF DEFINED Directive
IFIX
IFLOATI, IFLOATJ
ILEN
IMAGE_INDEX
IMAGE_STATUS
IMPLICIT
IMPORT
IMPURE
IN_REDUCTION
INCLUDE
INDEX
INLINE, FORCEINLINE, and NOINLINE
INMAX
INQUIRE
INT
INTC
INT_PTR_KIND
INTEGER Statement
INTEGER Directive
INTENT
INTERFACE
INTERFACE TO
INTEROP
INTRINSIC
INUM
IOR
IPARITY
IRAND, IRANDM
IRANGET
IRANSET
IS_CONTIGUOUS
IS_DEVICE_PTR Clause
IS_IOSTAT_END
IS_IOSTAT_EOR
ISATTY
ISHA
ISHC
ISHFT
ISHFTC
ISHL
ISNAN
ITERATOR Clause Modifier
ITIME
IVDEP
IXOR
MAKEDIRQQ
MALLOC
MAP Clause
MAP and END MAP
MASKED
MASKED TASKLOOP
MASKED TASKLOOP SIMD
MASKL
MASKR
MASTER
MASTER TASKLOOP
MASTER TASKLOOP SIMD
MATMUL
MAX
MAXEXPONENT
MAXLOC
MAXVAL
MCLOCK
MERGE
MERGE_BITS
MERGEABLE Clause
MESSAGE
METADIRECTIVE
MIN
MINEXPONENT
MINLOC
MINVAL
MM_PREFETCH
MOD
MODULE
MODULE FUNCTION
MODULE PROCEDURE
MODULE SUBROUTINE
MODULO
MOVE_ALLOC
MVBITS
NAMELIST
NARGS
NEAREST
NEW_LINE
NINT
NOFREEFORM
NOFUSION
NON_RECURSIVE
NOOPTIMIZE
NOPREFETCH
NORM2
NOSTRICT
NOT
NOTHING
NOUNROLL
NOUNROLL_AND_JAM
NOVECTOR
NOWAIT Clause
NULL
NULLIFY
NUM_IMAGES
OBJCOMMENT
OPEN
OPTIONAL
OPTIMIZE and NOOPTIMIZE
OPTIONS Directive
OPTIONS Statement
OR
ORDER Clause
ORDERED
OUT_OF_RANGE
PACK Directive
PACK Function
PACKTIMEQQ
PARALLEL Directive for OpenMP
PARALLEL DO
PARALLEL DO SIMD
PARALLEL LOOP
PARALLEL MASKED
PARALLEL MASKED TASKLOOP
PARALLEL MASKED TASKLOOP SIMD
PARALLEL MASTER
PARALLEL MASTER TASKLOOP
PARALLEL MASTER TASKLOOP SIMD
PARALLEL SECTIONS
PARALLEL WORKSHARE
PARAMETER
PARITY
PAUSE
PEEKCHARQQ
PERROR
POINTER - Fortran
POINTER - Integer
POPCNT
POPPAR
PRECISION
PREFETCH and NOPREFETCH General Directives
PREFETCH DATA Directive for OpenMP
PRESENT
PRINT
PRIORITY
PRIVATE Clause
PRIVATE Statement
PROCEDURE
PROCESSOR Clause
PRODUCT
PROGRAM
PROTECTED
PSECT
PUBLIC
PURE
PUTC
QCMPLX
QEXT
QFLOAT
QNUM
QRANSET
QREAL
QSORT
RADIX
RAISEQQ
RAN
RAND, RANDOM
RANDOM Subroutine
RANDOM_INIT
RANDOM_NUMBER
RANDOM_SEED
RANDU
RANF Intrinsic Procedure
RANF Portability Routine
RANGE
RANGET
RANK
RANSET
READ Statement
REAL Directive
REAL Function
REAL Statement
RECORD
RECURSIVE and NON_RECURSIVE
REDUCE
REDUCTION
%REF
RENAME
RENAMEFILEQQ
REPEAT
REQUIRES
RESHAPE
RESULT
RETURN
REWIND
REWRITE
RINDEX
RNUM
RRSPACING
RSHIFT
RTC
RUNQQ
SAME_TYPE_AS
SAVE
SCALE
SCAN Directive
SCAN Function
SCANENV
SCOPE
SCWRQQ
SECNDS Intrinsic Procedure
SECNDS Portability Routine
SECTIONS
SEED
SELECT CASE and END SELECT
SELECT RANK
SELECT TYPE
SELECTED_CHAR_KIND
SELECTED_INT_KIND
SELECTED_REAL_KIND
SEQUENCE
SETCONTROLFPQQ
SETDAT
SETENVQQ
SETERRORMODEQQ
SET_EXPONENT
SETFILEACCESSQQ
SETFILETIMEQQ
SETTIM
SHAPE
SHARED Clause
SHIFTA
SHIFTL
SHIFTR
SHORT
SIGN
SIGNAL
SIGNALQQ
SIMD Directive for OpenMP
SIN
SIND
SINGLE
SINH
SIZE Function
SIZEOF
SLEEP
SLEEPQQ
SNGL
SORTQQ
SPACING
SPLIT
SPLITPATHQQ
SPREAD
SQRT
SRAND
SSWRQQ
STAT
Statement Function
STATIC
STOP and ERROR STOP
STOPPED_IMAGES
STORAGE_SIZE
STRICT and NOSTRICT
STRUCTURE and END STRUCTURE
SUBDEVICE
SUBMODULE
SUBROUTINE
SUM
SYNC ALL
SYNC IMAGES
SYNC MEMORY
SYNC TEAM
SYSTEM
SYSTEM_CLOCK
SYSTEMQQ
TAN
TAND
TANH
TARGET
TARGET DATA
TARGET Statement
TARGET ENTER DATA
TARGET EXIT DATA
TARGET PARALLEL
TARGET PARALLEL DO
TARGET PARALLEL DO SIMD
TARGET PARALLEL LOOP
TARGET SIMD
TARGET TEAMS
TARGET TEAMS DISTRIBUTE
TARGET TEAMS DISTRIBUTE PARALLEL DO
TARGET TEAMS DISTRIBUTE PARALLEL DO SIMD
TARGET TEAMS DISTRIBUTE SIMD
TARGET TEAMS LOOP
TARGET UPDATE
TASK
TASK_REDUCTION
TASKGROUP
TASKLOOP
TASKLOOP SIMD
TASKWAIT
TASKYIELD
TEAM_NUMBER
TEAMS
TEAMS DISTRIBUTE
TEAMS DISTRIBUTE PARALLEL DO
TEAMS DISTRIBUTE PARALLEL DO SIMD
TEAMS DISTRIBUTE SIMD
TEAMS LOOP
THIS_IMAGE
THREAD_LIMIT
THREADPRIVATE
TILE
TIME Intrinsic Procedure
TIME Portability Routine
TIMEF
TINY
TOKENIZE
TRACEBACKQQ
TRAILZ
TRANSFER
TRANSPOSE
TRIM
TTYNAM
Type Declarations
TYPE Statement for Derived Types
UBOUND
UCOBOUND
UNDEFINE
UNION and END UNION
UNLINK
UNPACK
UNPACKTIMEQQ
UNROLL Directive for OpenMP
UNROLL and NOUNROLL General Directives
UNROLL_AND_JAM and NOUNROLL_AND_JAM
UNTIED Clause
USE
USE_DEVICE_PTR Clause
%VAL
VALUE
VECREMAINDER Clause
VECTOR and NOVECTOR
VERIFY
VIRTUAL
VOLATILE
WAIT
WHERE
WORKSHARE
WRITE Statement
XOR
ZEXT
IPXFARGC
IPXFCONST
IPXFLENTRIM
IPXFWEXITSTATUS
IPXFWSTOPSIG
IPXFWTERMSIG
PXFGET
PXFSET
PXFAGET
PXFASET
PXFACCESS
PXFALARM
PXFCALLSUBHANDLE
PXFCFGETISPEED
PXFCFGETOSPEED
PXFCFSETISPEED
PXFCFSETOSPEED
PXFCHDIR
PXFCHMOD
PXFCHOWN
PXFCLEARENV
PXFCLOSE
PXFCLOSEDIR
PXFCONST
PXFCREAT
PXFCTERMID
PXFDUP, PXFDUP2
PXFEGET
PXFESET
PXFEXECV
PXFEXECVE
PXFEXECVP
PXFEXIT, PXFFASTEXIT
PXFFCNTL
PXFFDOPEN
PXFFFLUSH
PXFFGETC
PXFFILENO
PXFFORK
PXFFPATHCONF
PXFFPUTC
PXFFSEEK
PXFFSTAT
PXFFTELL
PXFGETARG
PXFGETC
PXFGETCWD
PXFGETEGID
PXFGETENV
PXFGETEUID
PXFGETGID
PXFGETGRGID
PXFGETGRNAM
PXFGETGROUPS
PXFGETLOGIN
PXFGETPGRP
PXFGETPID
PXFGETPPID
PXFGETPWNAM
PXFGETPWUID
PXFGETSUBHANDLE
PXFGETUID
PXFISATTY
PXFISBLK
PXFISCHR
PXFISCONST
PXFISDIR
PXFISFIFO
PXFISREG
PXFKILL
PXFLINK
PXFLOCALTIME
PXFLSEEK
PXFMKDIR
PXFMKFIFO
PXFOPEN
PXFOPENDIR
PXFPATHCONF
PXFPAUSE
PXFPIPE
PXFPOSIXIO
PXFPUTC
PXFREAD
PXFREADDIR
PXFRENAME
PXFREWINDDIR
PXFRMDIR
PXFSETENV
PXFSETGID
PXFSETPGID
PXFSETSID
PXFSETUID
PXFSIGACTION
PXFSIGADDSET
PXFSIGDELSET
PXFSIGEMPTYSET
PXFSIGFILLSET
PXFSIGISMEMBER
PXFSIGPENDING
PXFSIGPROCMASK
PXFSIGSUSPEND
PXFSLEEP
PXFSTAT
PXFSTRUCTCOPY
PXFSTRUCTCREATE
PXFSTRUCTFREE
PXFSYSCONF
PXFTCDRAIN
PXFTCFLOW
PXFTCFLUSH
PXFTCGETATTR
PXFTCGETPGRP
PXFTCSENDBREAK
PXFTCSETATTR
PXFTCSETPGRP
PXFTIME
PXFTIMES
PXFTTYNAME
PXFUCOMPARE
PXFUMASK
PXFUNAME
PXFUNLINK
PXFUTIME
PXFWAIT
PXFWAITPID
PXFWIFEXITED
PXFWIFSIGNALED
PXFWIFSTOPPED
PXFWRITE
AUTOAddArg
AUTOAllocateInvokeArgs
AUTODeallocateInvokeArgs
AUTOGetExceptInfo
AUTOGetProperty
AUTOGetPropertyByID
AUTOGetPropertyInvokeArgs
AUTOInvoke
AUTOSetProperty
AUTOSetPropertyByID
AUTOSetPropertyInvokeArgs
COMAddObjectReference
COMCLSIDFromProgID
COMCLSIDFromString
COMCreateObject
COMCreateObjectByGUID
COMCreateObjectByProgID
COMGetActiveObjectByGUID
COMGetActiveObjectByProgID
COMGetFileObject
COMInitialize
COMIsEqualGUID
COMQueryInterface
COMReleaseObject
COMStringFromGUID
COMUninitialize
MBCharLen
MBConvertMBToUnicode
MBConvertUnicodeToMB
MBCurMax
MBINCHARQQ
MBINDEX
MBJISToJMS, MBJMSToJIS
MBLead
MBLen
MBLen_Trim
MBLGE, MBLGT, MBLLE, MBLLT, MBLEQ, MBLNE
MBNext
MBPrev
MBSCAN
MBStrLead
MBVERIFY
NLSEnumCodepages
NLSEnumLocales
NLSFormatCurrency
NLSFormatDate
NLSFormatNumber
NLSFormatTime
NLSGetEnvironmentCodepage
NLSGetLocale
NLSGetLocaleInfo
NLSSetEnvironmentCodepage
NLSSetLocale
ABOUTBOXQQ
APPENDMENUQQ
CLICKMENUQQ
DELETEMENUQQ
FOCUSQQ
GETACTIVEQQ
GETEXITQQ
GETHWNDQQ
GETUNITQQ
GETWINDOWCONFIG
GETWSIZEQQ
INCHARQQ
INITIALSETTINGS
INQFOCUSQQ
INSERTMENUQQ
INTEGERTORGB
MESSAGEBOXQQ
MODIFYMENUFLAGSQQ
MODIFYMENUROUTINEQQ
MODIFYMENUSTRINGQQ
PASSDIRKEYSQQ
REGISTERMOUSEEVENT
RGBTOINTEGER
SETACTIVEQQ
SETEXITQQ
SETMESSAGEQQ
SETMOUSECURSOR
SETWINDOWCONFIG
SETWINDOWMENUQQ
SETWSIZEQQ
UNREGISTERMOUSEEVENT
WAITONMOUSEEVENT
ARC, ARC_W
CLEARSCREEN
DISPLAYCURSOR
ELLIPSE, ELLIPSE_W
FLOODFILL, FLOODFILL_W
FLOODFILLRGB, FLOODFILLRGB_W
GETARCINFO
GETBKCOLOR
GETBKCOLORRGB
GETCOLOR
GETCOLORRGB
GETCURRENTPOSITION, GETCURRENTPOSITION_W
GETFILLMASK
GETFONTINFO
GETGTEXTEXTENT
GETGTEXTROTATION
GETIMAGE, GETIMAGE_W
GETLINESTYLE
GETLINEWIDTHQQ
GETPHYSCOORD
GETPIXEL, GETPIXEL_W
GETPIXELRGB, GETPIXELRGB_W
GETPIXELS
GETPIXELSRGB
GETTEXTCOLOR
GETTEXTCOLORRGB
GETTEXTPOSITION
GETTEXTWINDOW
GETVIEWCOORD, GETVIEWCOORD_W
GETWINDOWCOORD
GETWRITEMODE
GRSTATUS
IMAGESIZE, IMAGESIZE_W
INITIALIZEFONTS
LINETO, LINETO_W
LINETOAR
LINETOAREX
LOADIMAGE, LOADIMAGE_W
MOVETO, MOVETO_W
OUTGTEXT
OUTTEXT
PIE, PIE_W
POLYBEZIER, POLYBEZIER_W
POLYBEZIERTO, POLYBEZIERTO_W
POLYGON, POLYGON_W
POLYLINEQQ
PUTIMAGE, PUTIMAGE_W
RECTANGLE, RECTANGLE_W
REMAPALLPALETTERGB, REMAPPALETTERGB
SAVEIMAGE, SAVEIMAGE_W
SCROLLTEXTWINDOW
SETBKCOLOR
SETBKCOLORRGB
SETCLIPRGN
SETCOLOR
SETCOLORRGB
SETFILLMASK
SETFONT
SETGTEXTROTATION
SETLINESTYLE
SETLINEWIDTHQQ
SETPIXEL, SETPIXEL_W
SETPIXELRGB, SETPIXELRGB_W
SETPIXELS
SETPIXELSRGB
SETTEXTCOLOR
SETTEXTCOLORRGB
SETTEXTCURSOR
SETTEXTPOSITION
SETTEXTWINDOW
SETVIEWORG
SETVIEWPORT
SETWINDOW
SETWRITEMODE
WRAPON
SPORT_CANCEL_IO
SPORT_CONNECT
SPORT_CONNECT_EX
SPORT_GET_HANDLE
SPORT_GET_STATE
SPORT_GET_STATE_EX
SPORT_GET_TIMEOUTS
SPORT_PEEK_DATA
SPORT_PEEK_LINE
SPORT_PURGE
SPORT_READ_DATA
SPORT_READ_LINE
SPORT_RELEASE
SPORT_SET_STATE
SPORT_SET_STATE_EX
SPORT_SET_TIMEOUTS
SPORT_SHOW_STATE
SPORT_SPECIAL_FUNC
SPORT_WRITE_DATA
SPORT_WRITE_LINE
DLGEXIT
DLGFLUSH
DLGGET, DLGGETINT, DLGGETLOG, DLGGETCHAR
DLGINIT, DLGINITWITHRESOURCEHANDLE
DLGISDLGMESSAGE, DLGISDLGMESSAGEWITHDLG
DLGMODAL, DLGMODALWITHPARENT
DLGMODELESS
DLGSENDCTRLMESSAGE
DLGSET, DLGSETINT, DLGSETLOG, DLGSETCHAR
DLGSETCTRLEVENTHANDLER
DLGSETRETURN
DLGSETSUB
DLGSETTITLE
DLGUNINIT
Prepare Your Program for Debugging
Use Breakpoints in the Microsoft Debugger
Debug the Squares Example with Microsoft* Debugger
View Fortran Data Types in the Microsoft Debugger
View the Call Stack in the Microsoft Debugger
Locate Unaligned Data
Debug a Program that Encounters a Signal or Exception
Debugging and Optimizations
Debug Mixed-Language Programs
Debug Multithreaded Programs
Use Remote Debugging
OpenMP* Runtime Library Routines
Intel® Compiler Extension Routines to OpenMP*
OpenMP* Support Libraries
Use the OpenMP* Libraries
Thread Affinity Interface
The KMP_AFFINITY Environment Variable
Affinity Types
permute and offset Combinations
Modifier Values for Affinity Types
Determine Machine Topology
KMP_CPUINFO_FILE and /proc/cpuinfo
Windows Processor Groups
Use a Specific Machine Topology Modeling Method (KMP_TOPOLOGY_METHOD)
Explicitly Specify OS Processor IDs (GOMP_CPU_AFFINITY, KMP_AFFINITY)
Low Level Affinity API
OpenMP* Memory Spaces and Allocators
Support for 64-bit Architecture on Linux
Traceback
Allocate Common Blocks
Generate Listing and Map Files
Create Shared Libraries
Specify Alternative Tools and Locations
Temporary Files Created by the Compiler or Linker
Use the Intel® Fortran COM Server on Windows
Use the Intel® Fortran Module Wizard (COM Client) on Windows
IFPORT Portability Library
Visible to Intel only — GUID: GUID-8BA55F4A-D5AE-4E27-8C25-058B68D280A4
Thread Affinity Interface
The Intel® runtime library has the ability to bind OpenMP* threads to physical processing units. The interface is controlled using the KMP_AFFINITY environment variable. Depending on the system (machine) topology, application, and operating system, thread affinity can have a dramatic effect on the application speed.
Thread affinity restricts execution of certain threads (virtual execution units) to a subset of the physical processing units in a multiprocessor computer. Depending upon the topology of the machine, thread affinity can have a dramatic effect on the execution speed of a program.
Thread affinity is supported on Windows* systems and versions of Linux* systems that have kernel support for thread affinity.
The Intel OpenMP runtime library has the ability to bind OpenMP threads to physical processing units. There are three types of interfaces you can use to specify this binding, which are collectively referred to as the Intel OpenMP Thread Affinity Interface:
The high-level affinity interface uses an environment variable to determine the machine topology and assigns OpenMP threads to the processors based upon their physical location in the machine. This interface is controlled entirely by the KMP_AFFINITY environment variable.
The mid-level affinity interface uses an environment variable to explicitly specifies which processors (labeled with integer IDs) are bound to OpenMP threads. This interface provides compatibility with the GCC* GOMP_CPU_AFFINITY environment variable, but you can also invoke it by using the KMP_AFFINITY environment variable. The GOMP_CPU_AFFINITY environment variable is supported on Linux systems only, but users on Windows or Linux systems can use the similar functionality provided by the KMP_AFFINITY environment variable.
The low-level affinity interface uses APIs to enable OpenMP threads to make calls into the OpenMP runtime library to explicitly specify the set of processors on which they are to be run. This interface is similar in nature to sched_setaffinity and related functions on Linux systems or to SetThreadAffinityMask and related functions on Windows systems.
In addition, you can specify certain options of the KMP_AFFINITY environment variable to affect the behavior of the low-level API interface. For example, you can set the affinity type KMP_AFFINITY to disabled, which disables the low-level affinity interface, or you could use the KMP_AFFINITY or GOMP_CPU_AFFINITY environment variables to set the initial affinity mask, and then retrieve the mask with the low-level API interface.
The following terms are used in this section:
The total number of processing elements on the machine is referred to as the number of OS thread contexts.
Each processing element is referred to as an Operating System processor, or OS proc.
Each OS processor has a unique integer identifier associated with it, called an OS proc ID.
The term package refers to a single or multi-core processor chip.
The term OpenMP Global Thread ID (GTID) refers to an integer which uniquely identifies all threads known to the Intel OpenMP runtime library. The thread that first initializes the library is given GTID 0. In the normal case where all other threads are created by the library and when there is no nested parallelism, then n-threads-var - 1 new threads are created with GTIDs ranging from 1 to ntheads-var - 1, and each thread's GTID is equal to the OpenMP thread number returned by function omp_get_thread_num().
The high-level and mid-level interfaces rely heavily on this concept. Hence, their usefulness is limited in programs containing nested parallelism. The low-level interface does not make use of the concept of a GTID and can be used by programs containing arbitrarily many levels of parallelism.
Some environment variables are available for both Intel® microprocessors and non-Intel microprocessors, but may perform additional optimizations for Intel® microprocessors than for non-Intel microprocessors.
The KMP_AFFINITY Environment Variable
NOTE:
You must set the KMP_AFFINITY environment variable before the first parallel region, or certain API calls including omp_get_max_threads(), omp_get_num_procs() and any affinity API calls, as described in Low Level Affinity API, below.
The KMP_AFFINITY environment variable uses the following general syntax:
KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>]
For example, to list a machine topology map, specify KMP_AFFINITY=verbose,none to use a modifier of verbose and a type of none.
The following table describes the supported specific arguments.
Argument |
Default |
Description |
|---|---|---|
noverbose respect granularity=core |
Optional. String consisting of keyword and specifier.
The syntax for <proc-list> is explained in mid-level affinity interface.
NOTE:
On Windows with multiple processor groups, the norespect affinity modifier is assumed when the process affinity mask equals a single processor group (which is default on Windows). Otherwise, the respect affinity modifier is used.
|
|
none |
Required string. Indicates the thread affinity to use.
The logical and physical types are deprecated but supported for backward compatibility. |
|
0 |
Optional. Positive integer value. Not valid with type values of explicit, none, or disabled. |
|
0 |
Optional. Positive integer value. Not valid with type values of explicit, none, or disabled. |
Affinity Types
Type is the only required argument.
type = none (default)
Does not bind OpenMP threads to particular thread contexts; however, if the operating system supports affinity, the compiler still uses the OpenMP thread affinity interface to determine machine topology. Specify KMP_AFFINITY=verbose,none to list a machine topology map.
type = balanced
Places threads on separate cores until all cores have at least one thread, similar to the scatter type. However, when the runtime must use multiple hardware thread contexts on the same core, the balanced type ensures that the OpenMP thread numbers are close to each other, which scatter does not do. This affinity type is supported on the CPU only for single socket systems.
NOTE:
The OpenMP* environment variable OMP_PROC_BIND=spread is similar to KMP_AFFINITY=balanced and is available on all platforms, including multi-socket CPU systems.
type = compact
Specifying compact assigns the OpenMP thread <n>+1 to a free thread context as close as possible to the thread context where the <n> OpenMP thread was placed. For example, in a topology map, the nearer a node is to the root, the more significance the node has when sorting the threads.
type = disabled
Specifying disabled completely disables the thread affinity interfaces. This forces the OpenMP runtime library to behave as if the affinity interface was not supported by the operating system. This includes the low-level API interfaces such as kmp_set_affinity and kmp_get_affinity, which have no effect and will return a non-zero error code.
type = explicit
Specifying explicit assigns OpenMP threads to a list of OS proc IDs that have been explicitly specified by using the proclist= modifier, which is required for this affinity type. See Explicitly Specify OS Processor IDs (GOMP_CPU_AFFINITY, KMP_AFFINITY).
type = scatter
Specifying scatter distributes the threads as evenly as possible across the entire system. scatter is the opposite of compact; so the leaves of the node are most significant when sorting through the machine topology map.
Deprecated Types: logical and physical
Types logical and physical are deprecated and may become unsupported in a future release. Both are supported for backward compatibility.
For logical and physical affinity types, a single trailing integer is interpreted as an offset specifier instead of a permute specifier. In contrast, with compact and scatter types, a single trailing integer is interpreted as a permute specifier.
Specifying logical assigns OpenMP threads to consecutive logical processors, which are also called hardware thread contexts. The type is equivalent to compact, except that the permute specifier is not allowed. Thus, KMP_AFFINITY=logical,n is equivalent to KMP_AFFINITY=compact,0,n (this equivalence is true regardless of the whether or not a granularity=fine modifier is present).
Specifying physical assigns threads to consecutive physical processors (cores). For systems where there is only a single thread context per core, the type is equivalent to logical. For systems where multiple thread contexts exist per core, physical is equivalent to compact with a permute specifier of 1; that is, KMP_AFFINITY=physical,n is equivalent to KMP_AFFINITY=compact,1,n (regardless of the whether or not a granularity=fine modifier is present).
This equivalence means that when the compiler sorts the map it should permute the innermost level of the machine topology map to the outermost, presumably the thread context level. This type does not support the permute specifier.
Examples of Types compact and scatter
The following figure illustrates the topology for a machine with two processors, and each processor has two cores; further, each core has Intel® Hyper-Threading Technology (Intel® HT Technology) enabled.
The following figure also illustrates the binding of OpenMP thread to hardware thread contexts when specifying KMP_AFFINITY=granularity=fine,compact.
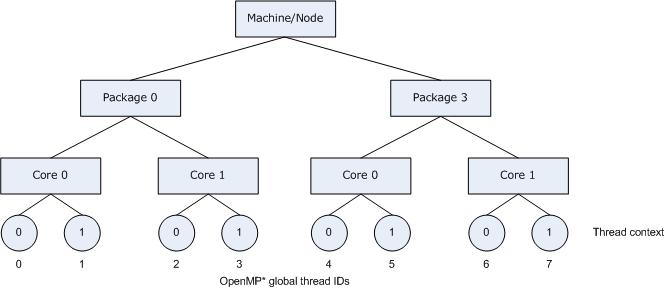
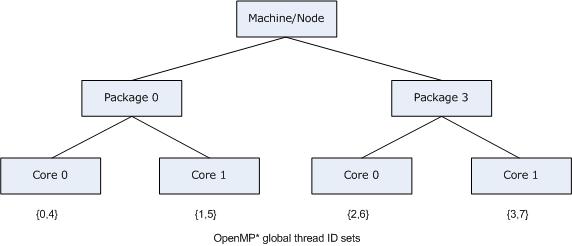
Specifying scatter on the same system as shown in the figure above, the OpenMP threads would be assigned the thread contexts as shown in the following figure, which shows the result of specifying KMP_AFFINITY=granularity=fine,scatter.
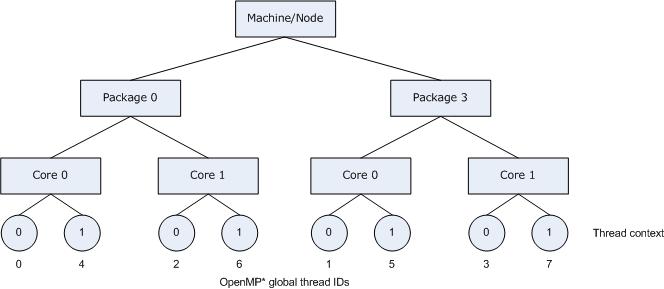
permute and offset Combinations
For both compact and scatter, permute and offset are allowed; however, if you specify only one integer, the compiler interprets the value as a permute specifier. Both permute and offset default to 0.
The permute specifier controls which levels are most significant when sorting the machine topology map. A value for permute forces the mappings to make the specified number of most significant levels of the sort the least significant, and it inverts the order of significance. The root node of the tree is not considered a separate level for the sort operations.
The offset specifier indicates the starting position for thread assignment.
The following figure illustrates the result of specifying KMP_AFFINITY=granularity=fine,compact,0,5.
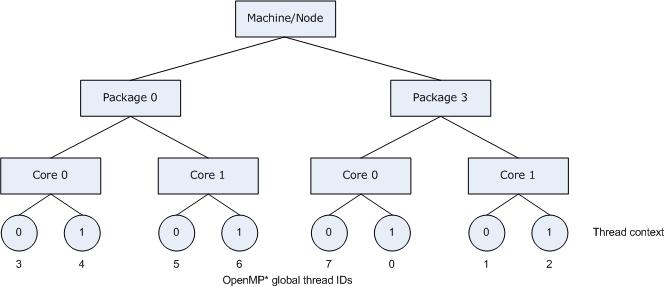
Consider the hardware configuration from the previous example, running an OpenMP application which exhibits data sharing between consecutive iterations of loops. We would therefore like consecutive threads to be bound close together, as is done with KMP_AFFINITY=compact, so that communication overhead, cache line invalidation overhead, and page thrashing are minimized.
Now, suppose the application also had a number of parallel regions which did not use all of the available OpenMP threads. It is desirable to avoid binding multiple threads to the same core and leaving other cores not utilized, since a thread normally executes faster on a core where it is not competing for resources with another active thread on the same core. Since a thread normally executes faster on a core where it is not competing for resources with another active thread on the same core, you might want to avoid binding multiple threads to the same core while leaving other cores unused. The following figure illustrates this strategy of using KMP_AFFINITY=granularity=fine,compact,1,0 as a setting.
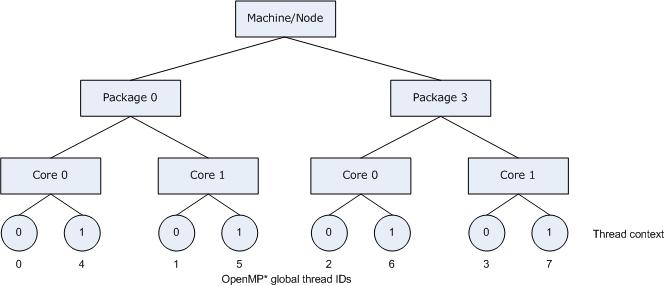
The OpenMP thread n+1 is bound to a thread context as close as possible to OpenMP thread n, but on a different core. Once each core has been assigned one OpenMP thread, the subsequent OpenMP threads are assigned to the available cores in the same order, but they are assigned on different thread contexts.
Modifier Values for Affinity Types
Modifiers are optional arguments that precede type. If you do not specify a modifier, the noverbose, respect, and granularity=core modifiers are used automatically.
Modifiers are interpreted in order from left to right, and they may conflict. Following conflicting modifier is ignored. For example, specifying KMP_AFFINITY=verbose,noverbose,scatter is therefore equivalent to setting KMP_AFFINITY=verbose,scatter.
modifier = noverbose (default)
Does not print verbose messages.
modifier = verbose
Prints messages concerning the supported affinity. The messages include information about the number of packages, number of cores in each package, number of thread contexts for each core, and OpenMP thread bindings to physical thread contexts.
Information about binding OpenMP threads to physical thread contexts is indirectly shown in the form of the mappings between hardware thread contexts and the operating system (OS) processor (proc) IDs. The affinity mask for each OpenMP thread is printed as a set of OS processor IDs.
For example, specifying KMP_AFFINITY=verbose,scatter on a dual core system with two processors, with Intel® Hyper-Threading Technology (Intel® HT Technology) disabled, results in a message listing similar to the following when then program is executed:
... KMP_AFFINITY: Initial OS proc set respected: 0,1,2,3 KMP_AFFINITY: affinity capable, using hwloc. KMP_AFFINITY: 4 available OS procs KMP_AFFINITY: Uniform topology KMP_AFFINITY: 2 sockets x 2 cores/socket x 1 threads/core (4 total cores) KMP_AFFINITY: OS proc to physical thread map: KMP_AFFINITY: OS proc 0 maps to socket 0 core 0 thread 0 KMP_AFFINITY: OS proc 2 maps to socket 0 core 1 thread 0 KMP_AFFINITY: OS proc 1 maps to socket 3 core 0 thread 0 KMP_AFFINITY: OS proc 3 maps to socket 3 core 1 thread 0 KMP_AFFINITY: pid 79739 tid 79739 thread 0 bound to OS proc set 0 KMP_AFFINITY: pid 79739 tid 79740 thread 2 bound to OS proc set 2 KMP_AFFINITY: pid 79739 tid 79741 thread 3 bound to OS proc set 3 KMP_AFFINITY: pid 79739 tid 79742 thread 1 bound to OS proc set 1
The verbose modifier generates several standard, general messages. The following table summarizes how to read the messages.
Message String |
Description |
|---|---|
"affinity capable" |
Indicates that all components (compiler, operating system, and hardware) support affinity, so thread binding is possible. |
"decoding x2APIC ids" |
Indicates that the machine topology was discovered by binding a thread to each operating system processor and decoding the output of the cpuid instruction. |
"using hwloc" |
Indicates that the Portable Hardware Locality* (hwloc) library used to determine machine topology. |
"using /proc/cpuinfo" |
Linux only. Indicates that cpuinfo is being used to determine machine topology. |
"using flat" |
Operating system processor ID is assumed to be equivalent to physical package ID. This method of determining machine topology is used if none of the other methods will work, but may not accurately detect the actual machine topology. |
"uniform topology" |
The machine topology map is a full tree with no missing leaves at any level. |
The mapping from the operating system processors to thread context ID is printed next. The binding of OpenMP thread context ID is printed next unless the affinity type is none. For more information, see Determining Machine Topology.
modifier = granularity
Binding OpenMP threads to particular packages and cores will often result in a performance gain on systems with Intel processors with Intel® Hyper-Threading Technology (Intel® HT Technology) enabled; however, it is usually not beneficial to bind each OpenMP thread to a particular thread context on a specific core. Granularity describes the lowest levels that OpenMP threads are allowed to float within a topology map.
This modifier supports the following additional specifiers.
Specifier |
Description |
|---|---|
core |
Default. Allows all the OpenMP threads bound to a core to float between the different thread contexts. |
fine or thread |
The finest granularity level. Causes each OpenMP thread to be bound to a single thread context. The two specifiers are functionally equivalent. |
tile, die, module, node (can also use numa_domain), group, l1_cache, l2_cache, l3_cache, socket
NOTE:
Only available when Intel® Hybrid Technology is detected in the machine topology: core_type or core_efficiency
|
Allows all OpenMP threads bound to the specified resource to float between the different hardware thread contexts which represent that resource. For example, granularity=socket allows all the OpenMP threads bound to a socket to move between the hardware threads that represent that socket |
Specifying KMP_AFFINITY=verbose,granularity=core,compact on the same dual core system with two processors as in the previous section, but with Intel® Hyper-Threading Technology (Intel® HT Technology) enabled, results in a message listing similar to the following when the program is executed:
KMP_AFFINITY: Initial OS proc set respected: 0-7 KMP_AFFINITY: decoding x2APIC ids. KMP_AFFINITY: 8 available OS procs KMP_AFFINITY: Uniform topology KMP_AFFINITY: 2 sockects x 2 cores/socket x 2 threads/core (4 total cores) KMP_AFFINITY: OS proc to physical thread map: KMP_AFFINITY: OS proc 0 maps to socket 0 core 0 thread 0 KMP_AFFINITY: OS proc 4 maps to socket 0 core 0 thread 1 KMP_AFFINITY: OS proc 2 maps to socket 0 core 1 thread 0 KMP_AFFINITY: OS proc 6 maps to socket 0 core 1 thread 1 KMP_AFFINITY: OS proc 1 maps to socket 3 core 0 thread 0 KMP_AFFINITY: OS proc 5 maps to socket 3 core 0 thread 1 KMP_AFFINITY: OS proc 3 maps to socket 3 core 1 thread 0 KMP_AFFINITY: OS proc 7 maps to socket 3 core 1 thread 1 KMP_AFFINITY: pid 40880 tid 40880 thread 0 bound to OS proc set 0,4 KMP_AFFINITY: pid 40880 tid 40881 thread 1 bound to OS proc set 0,4 KMP_AFFINITY: pid 40880 tid 40882 thread 2 bound to OS proc set 2,6 KMP_AFFINITY: pid 40880 tid 40883 thread 3 bound to OS proc set 2,6 KMP_AFFINITY: pid 40880 tid 40884 thread 4 bound to OS proc set 1,5 KMP_AFFINITY: pid 40880 tid 40885 thread 5 bound to OS proc set 1,5 KMP_AFFINITY: pid 40880 tid 40886 thread 6 bound to OS proc set 3,7 KMP_AFFINITY: pid 40880 tid 40887 thread 7 bound to OS proc set 3,7
The affinity mask for each OpenMP thread is shown in the listing (above) as the set of operating system processor to which the OpenMP thread is bound.
The following figure illustrates the machine topology map, for the above listing, with OpenMP thread bindings.
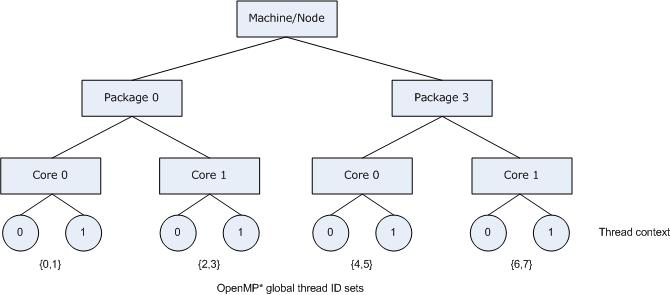
In contrast, specifying KMP_AFFINITY=verbose,granularity=fine,compact or KMP_AFFINITY=verbose,granularity=thread,compact binds each OpenMP thread to a single hardware thread context when the program is executed:
KMP_AFFINITY: Initial OS proc set respected: 0-7 KMP_AFFINITY: decoding x2APIC ids. KMP_AFFINITY: 8 available OS procs KMP_AFFINITY: Uniform topology KMP_AFFINITY: 2 sockets x 2 cores/socket x 2 threads/core (4 total cores) KMP_AFFINITY: OS proc to physical thread map: KMP_AFFINITY: OS proc 0 maps to socket 0 core 0 thread 0 KMP_AFFINITY: OS proc 4 maps to socket 0 core 0 thread 1 KMP_AFFINITY: OS proc 2 maps to socket 0 core 1 thread 0 KMP_AFFINITY: OS proc 6 maps to socket 0 core 1 thread 1 KMP_AFFINITY: OS proc 1 maps to socket 3 core 0 thread 0 KMP_AFFINITY: OS proc 5 maps to socket 3 core 0 thread 1 KMP_AFFINITY: OS proc 3 maps to socket 3 core 1 thread 0 KMP_AFFINITY: OS proc 7 maps to socket 3 core 1 thread 1 KMP_AFFINITY: pid 40895 tid 40895 thread 0 bound to OS proc set 0 KMP_AFFINITY: pid 40895 tid 40896 thread 1 bound to OS proc set 4 KMP_AFFINITY: pid 40895 tid 40897 thread 2 bound to OS proc set 2 KMP_AFFINITY: pid 40895 tid 40898 thread 3 bound to OS proc set 6 KMP_AFFINITY: pid 40895 tid 40899 thread 4 bound to OS proc set 1 KMP_AFFINITY: pid 40895 tid 40900 thread 5 bound to OS proc set 5 KMP_AFFINITY: pid 40895 tid 40901 thread 6 bound to OS proc set 3 KMP_AFFINITY: pid 40895 tid 40902 thread 7 bound to OS proc set 7
The OpenMP to hardware context binding for this example was illustrated in the first example.
Specifying granularity=fine will always cause each OpenMP thread to be bound to a single OS processor. This is equivalent to granularity=thread, currently the finest granularity level.
modifier = respect (Default)
Respect the process' original affinity mask, or more specifically, the affinity mask in place for the thread that initializes the OpenMP runtime library. The behavior differs between Linux and Windows:
Linux
Respect the affinity mask for the thread that initializes the OpenMP runtime library.
Windows
Respect original affinity mask for the process.
NOTE:
On Windows with multiple processor groups, the norespect affinity modifier is the default when the process affinity mask equals a single processor group (which is default on Windows). Otherwise, the respect affinity modifier is the default.
Specifying KMP_AFFINITY=verbose,compact for the same system used in the previous example, with Intel® Hyper-Threading Technology (Intel® HT Technology) enabled, and invoking the library with an initial affinity mask of {4,5,6,7} (thread context 1 on every core) causes the compiler to model the machine as a dual core, two-processor system with Intel® HT Technology disabled.
KMP_AFFINITY: Initial OS proc set respected: 4-7 KMP_AFFINITY: decoding x2APIC ids. KMP_AFFINITY: 4 available OS procs KMP_AFFINITY: Uniform topology KMP_AFFINITY: 2 sockets x 2 cores/socket x 1 threads/core (4 total cores) KMP_AFFINITY: OS proc to physical thread map: KMP_AFFINITY: OS proc 4 maps to socket 0 core 0 thread 1 KMP_AFFINITY: OS proc 6 maps to socket 0 core 1 thread 1 KMP_AFFINITY: OS proc 5 maps to socket 3 core 0 thread 1 KMP_AFFINITY: OS proc 7 maps to socket 3 core 1 thread 1 KMP_AFFINITY: pid 41032 tid 41032 thread 0 bound to OS proc set 4 KMP_AFFINITY: pid 41032 tid 41033 thread 1 bound to OS proc set 6 KMP_AFFINITY: pid 41032 tid 41034 thread 2 bound to OS proc set 5 KMP_AFFINITY: pid 41032 tid 41035 thread 3 bound to OS proc set 7
Because there are four thread contexts accessible on the machine, by default the compiler created four threads for an OpenMP parallel construct.
The following figure illustrates the corresponding machine topology map and threads placement in case eight OpenMP threads requested via OMP_NUM_THREADS=8
When using the local cpuid information to determine the machine topology, it is not always possible to distinguish between a machine that does not support Intel® Hyper-Threading Technology (Intel® HT Technology) and a machine that supports it, but has it disabled. Therefore, the compiler does not include a level in the map if the elements (nodes) at that level had no siblings, with the exception that the package level is always modeled. As mentioned earlier, the package level will always appear in the topology map, even if there only a single package in the machine.
modifier = norespect
Do not respect original affinity mask for the process. Binds OpenMP threads to all operating system processors.
In early versions of the OpenMP runtime library that supported only the physical and logical affinity types, norespect was the default and was not recognized as a modifier.
The default was changed to respect when types compact and scatter were added; therefore, thread bindings may have changed with the newer compilers in situations where the application specified a partial initial thread affinity mask.
modifier = nowarnings
Do not print warning messages from the affinity interface.
modifier = warnings (Default)
Print warning messages from the affinity interface (default).
modifier = noreset (Default)
Do not reset the primary thread's affinity after each outermost parallel region is complete. This setting preserves the primary thread's OpenMP affinity setting between parallel regions. For example, if KMP_AFFINITY=compact,granularity=core, then the primary thread's affinity is set to the first core for the first parallel region and kept that way for the thread's lifetime, even during serial regions.
modifier = reset
Reset the primary thread's affinity after each outermost parallel region is complete. This setting will reset the primary thread's affinity back to the initial affinity before OpenMP was initialized after each outermost parallel region is complete.
Determine Machine Topology
If the package has an APIC (Advanced Programmable Interrupt Controller), the compiler will use the cpuid instruction to obtain the package id, core id, and thread context id. Under normal conditions, each thread context on the system is assigned a unique APIC ID at boot time. The compiler obtains other pieces of information obtained by using the cpuid instruction, which together with the number of OS thread contexts (total number of processing elements on the machine), determine how to break the APIC ID down into the package ID, core ID, and thread context ID.
There are several ways to specify the APIC ID in the cpuid instruction - the legacy method in leaf 4, and the more modern method in leaf 11 and leaf 31. Only 256 unique APIC IDs are available in leaf 4. Leaf 11 and leaf 31 have no such limitation.
Normally, all core ids on a package and all thread context ids on a core are contiguous; however, numbering assignment gaps are common for package ids, as shown in the figure above.
If the compiler cannot determine the machine topology using any other method, but the operating system supports affinity, a warning message is printed, and the topology is assumed to be flat. For example, a flat topology assumes the operating system process N maps to package N, and there exists only one thread context per core and only one core for each package.
If the machine topology cannot be accurately determined as described above, the user can manually copy /proc/cpuinfo to a temporary file, correct any errors, and specify the machine topology to the OpenMP runtime library via the environment variable KMP_CPUINFO_FILE=<temp_filename>, as described in the section KMP_CPUINFO_FILE and /proc/cpuinfo.
Regardless of the method used in determining the machine topology, if there is only one thread context per core for every core on the machine, the thread context level will not appear in the topology map. If there is only one core per package for every package in the machine, the core level will not appear in the machine topology map. The topology map need not be a full tree, because different packages may contain a different number of cores, and different cores may support a different number of thread contexts.
The package level will always appear in the topology map, even if there only a single package in the machine.
KMP_CPUINFO_FILE and /proc/cpuinfo
One of the methods the OpenMP runtime library can use to detect the machine topology on Linux systems is to parse the contents of /proc/cpuinfo. If the contents of this file (or a device mapped into the Linux file system) are insufficient or erroneous, you can consider copying its contents to a writable temporary file <temp_file>, correct it or extend it with the necessary information, and set KMP_CPUINFO_FILE=<temp_file>.
If you do this, the OpenMP runtime library will read the <temp_file> location pointed to by KMP_CPUINFO_FILE instead of the information contained in /proc/cpuinfo or attempting to detect the machine topology by decoding the APIC IDs. That is, the information contained in the <temp_file> overrides these other methods. You can use the KMP_CPUINFO_FILE interface on Windows systems, where /proc/cpuinfo does not exist.
The content of /proc/cpuinfo or <temp_file> should contain a list of entries for each processing element on the machine. Each processor element contains a list of entries (descriptive name and value on each line). A blank line separates the entries for each processor element. Only the following fields are used to determine the machine topology from each entry, either in <temp_file> or /proc/cpuinfo:
Field |
Description |
|---|---|
processor : |
Specifies the OS ID for the processing element. The OS ID must be unique. The processor and physical id fields are the only ones that are required to use the interface. |
physical id : |
Specifies the package ID, which is a physical chip ID. Each package may contain multiple cores. The package level always exists in the compiler's OpenMP runtime library model of the machine topology. |
core id : |
Specifies the core ID. If it does not exist, it defaults to 0. If every package on the machine contains only a single core, the core level will not exist in the machine topology map (even if some of the core ID fields are non-zero). |
apicid : |
Specifies the thread ID. If it does not exist, it defaults to 0. If every core on the machine contains only a single thread, the thread level will not exist in the machine topology map (even if some thread ID fields are non-zero). |
node_n id : |
This is a extension to the normal contents of /proc/cpuinfo that can be used to specify the nodes at different levels of the memory interconnect on Non-Uniform Memory Access (NUMA) systems. Arbitrarily many levels n are supported. The node_0 level is closest to the package level; multiple packages comprise a node at level 0. Multiple nodes at level 0 comprise a node at level 1, and so on. |
Each entry must be spelled exactly as shown, in lowercase, followed by optional whitespace, a colon (:), more optional whitespace, then the integer ID. Fields other than those listed are simply ignored.
NOTE:
It is common for the thread id field to be missing from /proc/cpuinfo on many Linux variants, and for a field labeled siblings to specify the number of threads per node or number of nodes per package. However, the Intel OpenMP runtime library ignores fields labeled siblings so it can distinguish between the thread id and siblings fields. When this situation arises, the warning message Physical node/pkg/core/thread ids not unique appears (unless the type specified is nowarnings).
Windows Processor Groups
On a 64-bit Windows operating system, it is possible for multiple processor groups to accommodate more than 64 processors. Each group is limited in size, up to a maximum value of sixty-four (64) processors.
If multiple processor groups are detected, the default is to model the machine as a 2-level tree, where level 0 are for the processors in a group, and level 1 are for the different groups. Threads are assigned to a group until there are as many OpenMP threads bound to the groups as there are processors in the group. Subsequent threads are assigned to the next group, and so on.
By default, threads are allowed to float among all processors in a group, that is to say, granularity equals the group [granularity=group]. You can override this binding and explicitly use another affinity type like compact, scatter, and so on. If you do so, the granularity must be sufficiently fine to prevent a thread from being bound to multiple processors in different groups.
Use a Specific Machine Topology Modeling Method (KMP_TOPOLOGY_METHOD)
You can set the KMP_TOPOLOGY_METHOD environment variable to force OpenMP to use a particular machine topology modeling method.
Value |
Description |
|---|---|
cpuid_leaf31 |
Decodes the APIC identifiers as specified by leaf 31 of the cpuid instruction. |
cpuid_leaf11 |
Decodes the APIC identifiers as specified by leaf 11 of the cpuid instruction. |
cpuid_leaf4 |
Decodes the APIC identifiers as specified in leaf 4 of the cpuid instruction. |
cpuinfo |
If KMP_CPUINFO_FILE is not specified, forces OpenMP to parse /proc/cpuinfo to determine the topology (Linux only). If KMP_CPUINFO_FILE is specified as described above, uses it (Windows or Linux). |
group |
Models the machine as a 2-level map, with level 0 specifying the different processors in a group, and level 1 specifying the different groups (Windows 64-bit only) . |
flat |
Models the machine as a flat (linear) list of processors. |
hwloc |
Models the machine as the Portable Hardware Locality* (hwloc) library does. This model is the most detailed and includes, but is not limited to: numa nodes, packages, cores, hardware threads, caches, and Windows processor groups. |
Explicitly Specify OS Processor IDs (GOMP_CPU_AFFINITY, KMP_AFFINITY)
NOTE:
You must set the GOMP_CPU_AFFINITY or KMP_AFFINITY environment variable
- before the first parallel region,
- before certain API calls, including omp_get_max_threads(), omp_get_num_procs(), and any affinity API calls, as described in Low Level Affinity API.
Instead of allowing the library to detect the hardware topology and automatically assign OpenMP threads to processing elements, the user may explicitly specify the assignment by using a list of operating system (OS) processor (proc) IDs. However, this requires knowledge of which processing elements the OS proc IDs represent.
On Linux systems you can use the GOMP_CPU_AFFINITY environment variable to specify a list of OS processor IDs. Its syntax is identical to that accepted by libgomp (assume that <proc_list> produces the entire GOMP_CPU_AFFINITY environment string):
Value |
Description |
|---|---|
<proc_list> := |
<entry> | <elem> , <list> | <elem> <whitespace> <list> |
<elem> := |
<proc_spec> | <range> |
<proc_spec> := |
<proc_id> |
<range> := |
<proc_id> - <proc_id> | <proc_id> - <proc_id> : <int> |
<proc_id> := |
<positive_int> |
OS processors specified in this list are then assigned to OpenMP threads, in order of OpenMP Global Thread IDs. If more OpenMP threads are created than there are elements in the list, then the assignment occurs modulo the size of the list. That is, OpenMP Global Thread ID n is bound to list element n mod <list_size>.
Consider the machine previously mentioned: a dual core, dual-package machine without Intel® Hyper-Threading Technology (Intel® HT Technology) enabled, where the OS proc IDs are assigned in the same manner as the example in a previous figure. Suppose that the application creates six OpenMP threads instead of 4 (the default), oversubscribing the machine. If GOMP_CPU_AFFINITY=3,0-2, then OpenMP threads are bound as shown in the figure below, just as should happen when compiling with gcc and linking with libgomp:
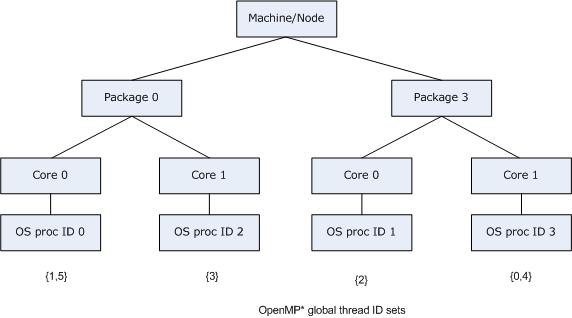
The same syntax can be used to specify the OS proc ID list in the proclist=[<proc_list>] modifier in the KMP_AFFINITY environment variable string. There is a slight difference: in order to have strictly the same semantics as in the gcc OpenMP runtime library libgomp: the GOMP_CPU_AFFINITY environment variable implies granularity=fine. If you specify the OS proc list in the KMP_AFFINITY environment variable without a granularity= specifier, then the default granularity is not changed. That is, OpenMP threads are allowed to float between the different thread contexts on a single core. Thus GOMP_CPU_AFFINITY=<proc_list> is an alias for KMP_AFFINITY="granularity=fine,proclist=[<proc_list>],explicit".
In the KMP_AFFINITY environment variable string, the syntax is extended to handle operating system processor ID sets. The user may specify a set of operating system processor IDs among which an OpenMP thread may execute ("float") enclosed in brackets:
Value |
Description |
|---|---|
<proc_list> := |
<proc_id> | { <float_list> } |
<float_list> := |
<proc_id> | <proc_id> , <float_list> |
This allows functionality similarity to the granularity= specifier, but it is more flexible. The OS processors on which an OpenMP thread executes may exclude other OS processors nearby in the machine topology, but include other distant OS processors. Building upon the previous example, we may allow OpenMP threads 2 and 3 to "float" between OS processor 1 and OS processor 2 by using KMP_AFFINITY="granularity=fine,proclist=[3,0,{1,2},{1,2}],explicit", as shown in the figure below:
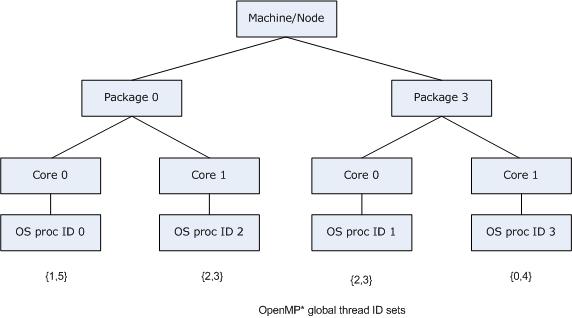
If verbose were also specified, the output when the application is executed would include:
KMP_AFFINITY: Initial OS proc set respected: 0,1,2,3 KMP_AFFINITY: decoding x2APIC ids. KMP_AFFINITY: 4 available OS procs KMP_AFFINITY: Uniform topology KMP_AFFINITY: 2 sockets x 2 cores/socket x 1 threads/core (4 total cores) KMP_AFFINITY: OS proc to physical thread map: KMP_AFFINITY: OS proc 0 maps to socket 0 core 0 thread 0 KMP_AFFINITY: OS proc 2 maps to socket 0 core 1 thread 0 KMP_AFFINITY: OS proc 1 maps to socket 3 core 0 thread 0 KMP_AFFINITY: OS proc 3 maps to socket 3 core 1 thread 0 KMP_AFFINITY: pid 41464 tid 41464 thread 0 bound to OS proc set 3 KMP_AFFINITY: pid 41464 tid 41465 thread 1 bound to OS proc set 0 KMP_AFFINITY: pid 41464 tid 41466 thread 2 bound to OS proc set 1,2 KMP_AFFINITY: pid 41464 tid 41467 thread 3 bound to OS proc set 1,2 KMP_AFFINITY: pid 41464 tid 41468 thread 4 bound to OS proc set 3 KMP_AFFINITY: pid 41464 tid 41469 thread 5 bound to OS proc set 0
Low Level Affinity API
Instead of relying on the user to specify the OpenMP thread to OS proc binding by setting an environment variable before program execution starts (or by using the kmp_settings interface before the first parallel region is reached), each OpenMP thread can determine the desired set of OS procs on which it is to execute and bind to them with the kmp_set_affinity API call.
CAUTION:
When you use this affinity interface you take complete control of the hardware resources on which your threads run. To do that sensibly you need to understand in detail how the logical CPUs, the enumeration of hardware threads controlled by the OS, map to the physical hardware of the specific machine on which you are running. That mapping can be, and likely is, different on different machines, so you risk binding machine-specific information into your code, which can result in explicitly forcing bad affinities when your code runs on a different machine. And if you are concerned with optimization at this level of detail, your code is probably valuable, and therefore will probably move to another machine.
This interface may also allow you to ignore the resource limitations that were set by the program startup mechanism, such as Message Passing Interface (MPI), specifically to prevent multiple OpenMP processes on the same node from using the same hardware threads. Again, this can result in explicitly forcing affinities that cause bad performance, and the OpenMP runtime will neither prevent this from happening, nor warn you when it does. These are expert interfaces and you must use them with caution.
Therefore, it is recommended that you use the higher level affinity settings if you possibly can, because they are more portable and do not require this low level knowledge.
The Fortran API interfaces follow, where the type name kmp_affinity_mask_kind is defined in omp_lib.h or omp_lib.mod:
Syntax |
Description |
|---|---|
integer function kmp_set_affinity(mask) |
Sets the affinity mask for the current OpenMP thread to mask, where mask is a set of OS proc IDs that has been created using the API calls listed below, and the thread will only execute on OS procs in the set. Returns either a zero (0) upon success or a non-zero error code. |
integer function kmp_get_affinity(mask) |
Retrieves the affinity mask for the current OpenMP thread, and stores it in mask, which must have previously been initialized with a call to kmp_create_affinity_mask(). Returns either a zero (0) upon success or a non-zero error code. |
integer function kmp_get_affinity_max_proc() |
Returns the maximum OS proc ID that is on the machine, plus 1. All OS proc IDs are guaranteed to be between 0 (inclusive) and kmp_get_affinity_max_proc() (exclusive). |
subroutine kmp_create_affinity_mask(mask) |
Allocates a new OpenMP thread affinity mask, and initializes mask to the empty set of OS procs. The implementation is free to use an object of kmp_affinity_mask_t either as the set itself, a pointer to the actual set, or an index into a table describing the set. Do not make any assumption as to what the actual representation is. |
subroutine kmp_destroy_affinity_mask(mask) |
Deallocates the OpenMP thread affinity mask. For each call to kmp_create_affinity_mask(), there should be a corresponding call to kmp_destroy_affinity_mask(). |
integer function kmp_set_affinity_mask_proc(proc, mask) |
Adds the OS proc ID proc to the set mask, if it is not already. Returns either a zero (0) upon success or a non-zero error code. |
integer function kmp_unset_affinity_mask_proc(proc, mask) |
If the OS proc ID proc is in the set mask, it removes it. Returns either a zero (0) upon success or a non-zero error code. |
integer function kmp_get_affinity_mask_proc(proc, mask)integer proc |
Returns 1 if the OS proc ID proc is in the set mask; if not, it returns 0. |
Once an OpenMP thread has set its own affinity mask via a successful call to kmp_set_affinity(), then that thread remains bound to the corresponding OS proc set until at least the end of the parallel region, unless reset via a subsequent call to kmp_set_affinity().
Between parallel regions, the affinity mask (and the corresponding OpenMP thread to OS proc bindings) can be considered thread private data objects, and have the same persistence as described in the OpenMP Application Program Interface. For more information, see the OpenMP API specification (http://www.openmp.org), some relevant parts of which are provided below:
In order for the affinity mask and thread binding to persist between two consecutive active parallel regions, all three of the following conditions must hold:
Neither parallel region is nested inside another explicit parallel region.
The number of threads used to execute both parallel regions is the same.
The value of the dyn-var internal control variable in the enclosing task region is false at entry to both parallel regions."
Therefore, by creating a parallel region at the start of the program whose sole purpose is to set the affinity mask for each thread, you can mimic the behavior of the KMP_AFFINITY environment variable with low-level affinity API calls, if program execution obeys the three aforementioned rules from the OpenMP specification.
The following example shows how these low-level interfaces can be used. This code binds the executing thread to the specified logical CPU:
! Force the executing thread to execute on logical CPU i
! Returns .TRUE. on success, .FALSE. on failure
function forceAffinity (i)
use omp_lib
logical forceAffinity
integer, intent(in) :: i
integer(kmp_affinity_mask_kind) :: mask
call kmp_create_affinity_mask(mask)
forceAffinity = (kmp_set_affinity_mask_proc(i, mask) == 0)
if (.not. forceAffinity) return
forceAffinity = (kmp_set_affinity_mask(mask) == 0)
return
end function forceAffinity
This program fragment was written with knowledge about the mapping of the OS proc IDs to the physical processing elements of the target machine. On another machine, or on the same machine with a different OS installed, the program would still run, but the OpenMP thread to physical processing element bindings could differ and you might be explicitly force a bad distribution.
Parent topic: OpenMP* Library Support