A newer version of this document is available. Customers should click here to go to the newest version.
gpu-hotspots Command Line Analysis
Use the gpu-hotspots value to launch the GPU Compute/Media Hotspots analysis to:
Explore GPU kernels with high GPU utilization, estimate the effectiveness of this utilization, identify possible reasons for stalls or low occupancy and options.
Explore the performance of your application per selected GPU metrics over time.
Analyze the hottest SYCL* standards or OpenCL™ kernels for inefficient kernel code algorithms or incorrect work item configuration.
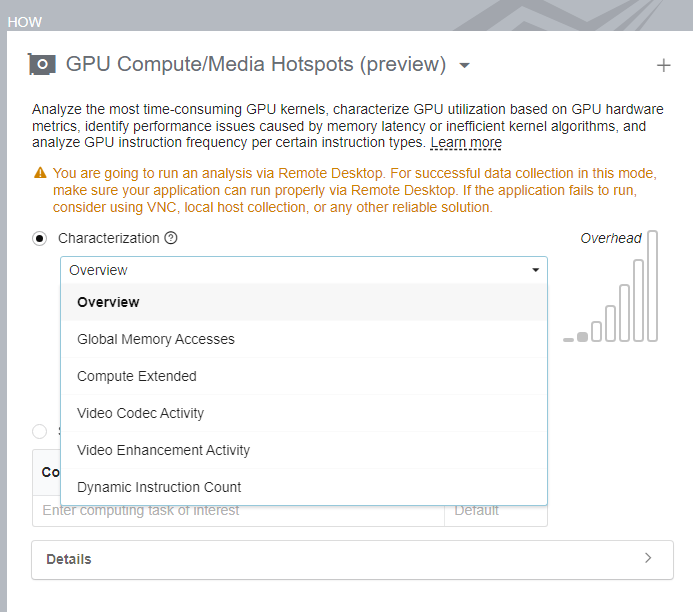
Configure Characterization Analysis
Use the Characterization configuration option to:
- Monitor the Render and GPGPU engine usage (Intel Graphics only)
- Identify the loaded parts of the engine
- Correlate GPU and CPU data
When you select the Characterization radio button, you can select platform-specific presets of GPU metrics. With the exception of the Dynamic Instruction Count preset, all other presets collect the following data about the activity of Execution Units (EU):
- EU Array Active
- EU Array Stalled
- EU Array Idle
- Computing Threads Started
- Thread Occupancy
- Core Frequency
Each preset introduces additional metrics:
The Overview metric set includes additional metrics that track general GPU memory accesses such as Memory Read/Write Bandwidth and XVE pipelines utilization. These metrics can be useful for both graphics and compute-intensive applications.
The Global Memory Accesses metric group includes additional metrics that show the bandwidth between the GPU and system memory as well as bandwidth between GPU stacks. The farther a memory level is located from an XVE, the greater the impact on its performance by unnecessary access operations to the memory level.
The LSE/SLM Accesses metric group includes metrics which cover the XVE to L1 cache traffic. This metric group requires two application runs to collect information.
The HDC Accesses metric group includes metrics which measure the traffic between XVE and L3, that is passing by the L1 cache.
The Full Compute metric group is a combination of all of the other event sets. Therefore, it requires multiple application runs.
The Dynamic Instruction Count metric group counts the execution frequency of specific classes of instructions. With this metric group, you also get an insight into the efficiency of SIMD utilization by each kernel.
The Video Codec Activity and Video Enhancement Activity metric groups are available when you run the GPU Compute/Media Hotspots analysis on Intel hardware platforms that support the collection of events from media engines.
Intel architectures that support the collection of events from media engines include (and are not limited to) microarchitectures code named:
- Meteor Lake
- Arrow Lake
- Lunar Lake
- Battlemage
You can run the GPU Compute/Media Hotspots analysis in Characterization mode for Windows*and Linux* targets. However, for all presets (with the exception of the Dynamic Instruction Count preset), you must have root/administrative privileges to run the GPU Compute/Media Hotspots analysis in Characterization mode.
Alternatively, on Linux* systems, you can configure the system to allow further collections for non-privileged users. To do this, in the bin64 folder of your installation directory, run the prepare-debugfs-and-gpu-environment.sh script with root privileges.
Configure Source Analysis
In the Source Analysis, VTune Profiler helps you identify performance-critical basic blocks, issues caused by memory accesses in the GPU kernels.
- Basic Blocks Latency option helps you identify issues caused by algorithm inefficiencies. In this mode, VTune Profiler measures the execution time of all basic blocks. Basic block is a straight-line code sequence that has a single entry point at the beginning of the sequence and a single exit point at the end of this sequence. During post-processing, VTune Profiler calculates the execution time for each instruction in the basic block. So, this mode helps understand which operations are more expensive.
- Memory Latency option helps identify latency issues caused by memory accesses. In this mode, VTune Profiler profiles memory read/synchronization instructions to estimate their impact on the kernel execution time. Consider using this option, if you ran the GPU Compute/Media Hotspots analysis in the Characterization mode, identified that the GPU kernel is throughput or memory-bound, and want to explore which memory read/synchronization instructions from the same basic block take more time.
In the Basic Block Latency or Memory Latency profiling modes, the GPU Compute/Media Hotspots analysis uses these metrics:
Estimated GPU Cycles: The average number of cycles spent by the GPU executing the profiled instructions.
Average Latency: The average latency of the memory read and synchronization instructions, in cycles.
GPU Instructions Executed per Instance: The average number of GPU instructions executed per one kernel instance.
GPU Instructions Executed per Thread: The average number of GPU instructions executed by one thread per one kernel instance.
If you enable the Instruction count profiling mode, VTune Profiler shows a breakdown of instructions executed by the kernel in the following groups:
Control Flow group |
if, else, endif, while, break, cont, call, calla, ret, goto, jmpi, brd, brc, join, halt and mov, add instructions that explicitly change the ip register. |
Send & Wait group |
send, sends, sendc, sendsc, wait |
Int16 & HP Float | Int32 & SP Float | Int64 & DP Float groups |
Bit operations (only for integer types): and, or, xor, and others. Arithmetic operations: mul, sub, and others; avg, frc, mac, mach, mad, madm. Vector arithmetic operations: line, dp2, dp4, and others. Extended math operations. |
Other group |
Contains all other operations including nop. |
In the Instruction count mode, VTune Profiler also provides Operations per second metrics calculated as a weighted sum of the following executed instructions:
Bit operations (only for integer types):
- and, not, or, xor, asr, shr, shl, bfrev, bfe, bfi1, bfi2, ror, rol - weight 1
Arithmetic operations:
add, addc, cmp, cmpn, mul, rndu, rndd, rnde, rndz, sub - weight 1
avg, frc, mac, mach, mad, madm - weight 2
Vector arithmetic operations:
- line - weight 2
- dp2, sad2 - weight 3
- lrp, pln, sada2 - weight 4
- dp3 - weight 5
- dph - weight 6
- dp4 - weight 7
- dp4a - weight 8
Extended math operations:
math.inv, math.log, math.exp, math.sqrt, math.rsq, math.sin, math.cos (weight 4)
math.fdiv, math.pow (weight 8)
The type of an operation is determined by the type of a destination operand.
vtune -collect gpu-hotspots [-knob <knobName=knobValue>] -- <target> [target_options]
Knobs: gpu-sampling-interval, profiling-mode, characterization-mode, code-level-analysis, collect-programming-api, computing-task-of-interest, target-gpu.
For the most current information on available knobs (configuration options) for the GPU Compute/Media Hotspots analysis, enter:
vtune -help collect gpu-hotspots
Example
This example runs the gpu-hotspots analysis in the default characterization mode with the default overview GPU hardware metric preset:
vtune -collect gpu-hotspots -knob enable-gpu-runtimes=true -- /home/test/myApplicationWhat's Next
When the data collection is complete, do one of the following to view the result:
Use the -report action to view the data from command line.
Use the -report-output action to write report to a .txt or .csv file
Open the data collection result (*.vtune) in the VTune Profiler graphical interface.