Visible to Intel only — GUID: GUID-CDE2C1C4-8E9B-4336-BD8A-85400FFC93FC
Intel® oneAPI FPGA Handbook
Introduction To FPGA Design Concepts
Intel oneAPI FPGA Development
Defining a Kernel for FPGAs
Debugging and Verifying Your Design
Analyzing Your Design
Optimizing Your Kernel
Optimizing Your Host Application
Integrating Your RTL IP Core Into a System
RTL IP Core Kernel Interfaces
Loops
Pipes
Data Types and Arithmetic Operations
Parallelism
Memories and Memory Operations
Libraries
Additional FPGA Acceleration Flow Considerations
Additional SYCL* HLS Flow Considerations
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the Intel oneAPI FPGA Handbook
Notices and Disclaimers
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Improve fMAX/II with Shannonization
Optimize Inner Loop Throughput
Improve Loop Performance by Caching Data in On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Use SYCL Shared Library With Third-Party Applications
Use of RTL Libraries for FPGA
Object Manifest File Syntax of an RTL Library
Restrictions and Limitations in RTL Support
Intel® Stratix® 10 and Intel Agilex® 7 Design-Specific Reset Requirements for Stall-Free and Stallable RTL Libraries
Stall-Free RTL
Specify Schedule FMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving=<global_memory_name>)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Visible to Intel only — GUID: GUID-CDE2C1C4-8E9B-4336-BD8A-85400FFC93FC
Scheduling
Scheduling refers to the process of determining clock cycles at which each operation in the datapath executes. Pipelining is the outcome of scheduling.
Dynamic Scheduling
The Intel® oneAPI DPC++/C++ Compiler generates pipelined datapath that is dynamically scheduled. A dynamically scheduled portion of the datapath does not pass data to its successor until its successor signals that it is ready to receive it. This signaling is accomplished using handshaking control logic. For example, a variable latency load from memory may refuse to accept its predecessors' data until the load is complete.
Handshaking helps in removing bubbles in the pipeline, thereby increasing occupancy. For more information about bubbles, refer to Occupancy.
The following figure illustrates four regions of dynamically scheduled logic:
Dynamically Scheduled Logic

Clustering the Datapath
Dynamically scheduling all operations adds overhead in the form of additional FPGA areas required to implement the required handshaking control logic.
To reduce this overhead, the compiler groups fixed latency operations into clusters. A cluster of fixed latency operations, such as arithmetic operations, requires fewer handshaking interfaces, thereby reducing the area overhead.
Clustered Logic

If A, B, and C from Figure 1 do not contain variable latency operations, the compiler can cluster them together, as illustrated in Figure 2. Clustering the logic reduces area by removing the need for signals to stall data flow in addition to other handshaking logic within the cluster.
Cluster Types
The Intel® oneAPI DPC++/C++ Compiler can create the following types of clusters:
Stall-Enable Cluster (SEC). This cluster type passes the handshaking logic to every pipeline stage in the cluster in parallel. This means that if the cluster is stalled by logic from further down in the datapath, all logic in the SEC stalls simultaneously.
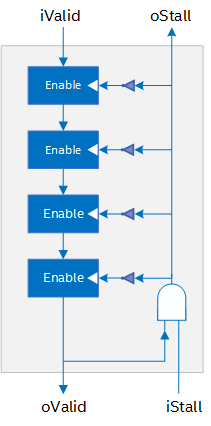
Stall-Free Cluster (SFC). This cluster type adds a first in, first out (FIFO) buffer to the end of the cluster that can accommodate the entire latency of the pipeline in the cluster. This FIFO is often called an exit FIFO because it is attached to the exit of the cluster datapath. 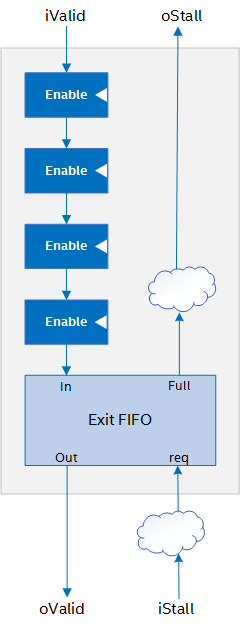
Because of this FIFO, the pipeline stages in the cluster do not require any handshaking logic. The stages can run freely and drain into the capacity FIFO, even if the cluster is stalled from logic further down in the datapath.
Cluster Characteristics
The exit FIFO of the stall-free cluster results in some of the following tradeoffs:
- Area: Because an SEC does not use an exit FIFO, it can save FPGA area compared to an SFC. If you have a design with many small, low-latency clusters, you can save a substantial amount of area by asking the compiler to use SECs instead of SFCs.
- Latency: Logic that uses SFCs might have a larger latency than logic that uses SECs because of the write-read latency of the exit FIFO. If you use a zero-latency FIFO for the exit FIFO, you can mitigate the latency, but fMAX or FPGA area use might be negatively impacted. For additional information, refer to Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>).
- FMAX: In an SFC, the oStall signal has less fanout than in an SEC. For a cluster with many pipeline stages, you can improve your design fMAX by using an SFC.
- Handshaking: The exit FIFO in SFCs allow them to take advantage of hyper-optimized handshaking between clusters. For more information, refer to Hyper Optimized Handshaking. SECs do not support this capability.
- Bubble Handling: SECs remove only leading bubbles in the pipeline under limited circumstances. A leading bubble is a bubble that arrives before the first piece of valid data arrives in the cluster. SECs do not remove any arriving afterward.
SFCs can use the capacity FIFO to remove all bubbles from the pipeline if the SFC gets a downstream stall signal.
- Stall Behavior: When an SEC receives a downstream stall, it stalls any logic upstream of it within one clock cycle. When an SFC receives a downstream stall, the exit FIFO allows it to consume additional valid data depending on how deep the exit FIFO is and how many bubbles are in the cluster datapath.
Handshaking Between Clusters
By default, the handshaking protocol between clusters is a simple stall/valid protocol. Data from the upstream cluster is consumed when the stall signal is low, and the valid signal is high.
Handshaking Between Clusters

Hyper Optimized Handshaking
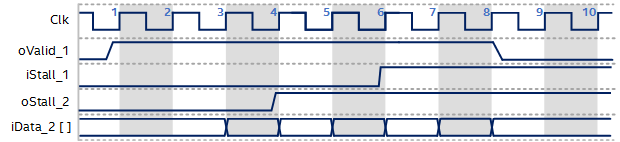
If the distance across the FPGA between these two clusters is large, handshaking may become the critical path that affects peak fMAX in the design. To improve these cases, the Intel® oneAPI DPC++/C++ Compiler can add pipelining registers to the stall/valid protocol to ease the critical path and improve fMAX. This enhanced handshaking protocol is called hyper-optimized handshaking.
Hyper-Optimized Handshaking Data Flow

The following timing diagram illustrates an example of upstream cluster 1 and downstream cluster 2 with two pipelining registers inserted in-between:
Hyper-Optimized Handshaking
RESTRICTION:
Hyper-optimized handshaking is currently available only for the Intel Agilex®7 and Intel®Stratix® 10 device families.
Parent topic: How Source Code Becomes a Custom Hardware Datapath