A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-01C2E72A-89D7-4721-B944-4266F41599EE
Visible to Intel only — GUID: GUID-01C2E72A-89D7-4721-B944-4266F41599EE
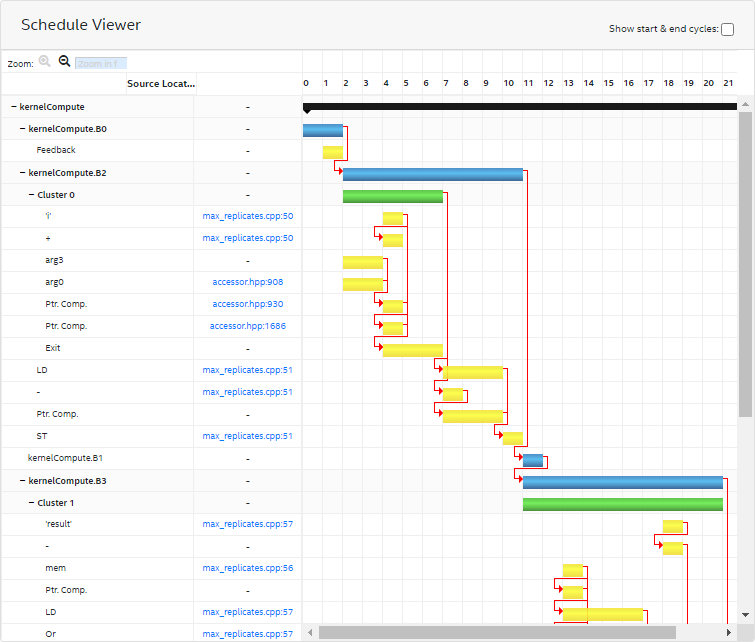
Schedule Viewer
The Schedule Viewer displays a static view of the scheduled cycle and latency of a clustered group of instructions in your design. Use this report to view loop bottlenecks such as fMAX/II bottlenecks, memory dependency, and occupancy limiter.
To view the Schedule Viewer, click Views > Schedule Viewer.
In the Schedule Viewer:
- Columns depict the clock cycles.
- Rows display a list of kernels, blocks, clusters, and instructions ranked by the order of execution.
- The red arrows are dependency lines for each block, cluster, or instruction. The arrows show how each block, cluster, or instruction is dependent on other blocks, clusters, or instructions. Hovering over a node (bar) highlights its outgoing dependency lines.
- Each row represents a node and its start and end cycle.
- The bars are color-coded. Black indicates a kernel, blue indicates a block, green indicates a cluster, and yellow indicates an instruction.