Visible to Intel only — GUID: GUID-D80EA756-88F9-42CD-B26B-7F38E8C1F3E5
Intel® oneAPI FPGA Handbook
Introduction To FPGA Design Concepts
Intel oneAPI FPGA Development
Defining a Kernel for FPGAs
Debugging and Verifying Your Design
Analyzing Your Design
Optimizing Your Kernel
Optimizing Your Host Application
Integrating Your RTL IP Core Into a System
RTL IP Core Kernel Interfaces
Loops
Pipes
Data Types and Arithmetic Operations
Parallelism
Memories and Memory Operations
Libraries
Additional FPGA Acceleration Flow Considerations
Additional SYCL* HLS Flow Considerations
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the Intel oneAPI FPGA Handbook
Notices and Disclaimers
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Improve fMAX/II with Shannonization
Optimize Inner Loop Throughput
Improve Loop Performance by Caching Data in On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Use SYCL Shared Library With Third-Party Applications
Use of RTL Libraries for FPGA
Object Manifest File Syntax of an RTL Library
Restrictions and Limitations in RTL Support
Intel® Stratix® 10 and Intel Agilex® 7 Design-Specific Reset Requirements for Stall-Free and Stallable RTL Libraries
Stall-Free RTL
Specify Schedule FMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving=<global_memory_name>)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Visible to Intel only — GUID: GUID-D80EA756-88F9-42CD-B26B-7F38E8C1F3E5
Interpret Performance Counter Data
Profiling information helps in identifying poor memory or pipe behaviors that lead to unsatisfactory kernel performance.
The following sections explain the Profiler metrics that the Profiler reports record.
Stall, Occupancy, Bandwidth
The CPU/FPGA Interaction View shows stall percentage, occupancy percentage, and average memory bandwidth for specific lines of kernel code. For definitions of stall, occupancy, data transfer size, and bandwidth, refer to Table 1.SYCL* generates a pipeline architecture where work-items traverse through the pipeline stages sequentially. For more information, refer to Pipelining.
Simplified Representation of a Kernel Pipeline Instrumented with Performance Counters
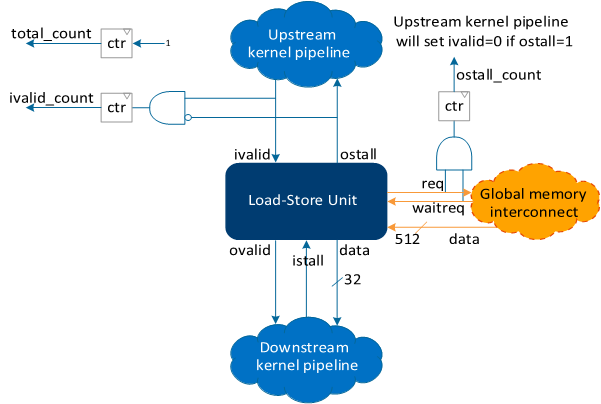
The following are simplified equations that describe how the Profiler calculates stall, occupancy, and bandwidth:

NOTE:
ivalid_count in the bandwidth equation also includes the predicate=true input to the load-store unit.
Ideal kernel pipeline conditions:
- Stall percentage equals 0%
- Occupancy percentage equals 100%
- Bandwidth equals the board's bandwidth
For a given location in the kernel pipeline, if the sum of the stall percentage and the occupancy percentage approximately equals 100%, the Profiler identifies the location as the stall source. If the stall percentage is low, the Profiler identifies the location as the victim of the stall.
The Profiler reports a high occupancy percentage if the compiler generates a highly efficient pipeline from your kernel, where work-items or iterations are moving through the pipeline stages without stalling. The following notes may be helpful when interpreting profiling data:
- If all LSUs are accessed the same number of times, they have the same occupancy value.
- If work-items cannot enter the pipeline consecutively, bubbles are inserted into the pipeline.
- In loop pipelining, loop-carried dependencies also form bubbles in the pipeline because of bubbles that exist between iterations. For more information about bubbles, refer to Occupancy.
- If an LSU is accessed less frequently than other LSUs, such as when an LSU is outside a loop that contains other LSUs, this LSU has a lower occupancy value than the other LSUs. This rule also applies to pipes.
Stalling Pipes
Pipes provide a point-to-point communication link between two kernels.
Stalls occur if there is an imbalance between the read and write sides of the pipe or if the read and write kernels are not running concurrently.
For example, if the kernel that reads is not launched concurrently with the kernel that writes, or if the read operations occur much slower than the write operations, the Profiler identifies a stall for the ProducerToConsumerPipe::write call in the write kernel.
Parent topic: Use Intel® VTune™ Profiler