A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-82D3E5A7-695F-4E7C-B4B9-908835A8509B
Visible to Intel only — GUID: GUID-82D3E5A7-695F-4E7C-B4B9-908835A8509B
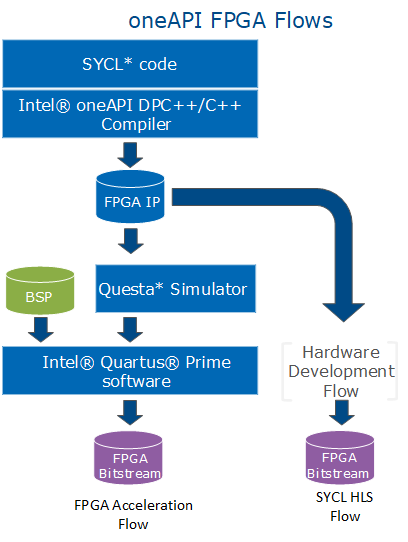
Intel oneAPI FPGA Development Flow
The Intel® oneAPI DPC++/C++ Compiler uses your SYCL* code to generate multiarchitecture binaries or RTL IP cores, depending on the compilation target that you specify. For multiarchitecture binaries, set the compilation target to an FPGA acceleration board. For RTL IP cores, set the compilation target to a supported Intel® FPGA device family or part number instead of a specific acceleration platform.
The typical design flow when you author kernels for FPGA devices or boards consists of the following stages:
- Creating your SYCL kernel and host code.
For information about writing SYCL code, refer to Data Parallelism in C++ using SYCL* in the Intel® oneAPI Programming Guide.
In the SYCL HLS flow, your kernel code becomes your RTL IP core and the host code serves as the testbench for the emulation and simulation flows.
In the FPGA acceleration flow, both kernel and host code end up in the resulting multiarchitecture binary.
- Verify the functionality of your kernel algorithm and testbench through emulation.
Verify the functionality of your kernel and refine the algorithms in your kernel by compiling your design to an x86-64 executable and running the executable. For details, see Emulate and Debug Your Design.
- Optimize and refine the FPGA performance of your kernel.
Use the FPGA Optimization Report to find areas where you can optimize your kernel to improve its performance and throughput. Compile your design with the -Xshardware and -fsycl-link=early compiler command options to obtain the FPGA Optimization Report.
For more details about analyzing your application, refer to Analyzing Your Design.
After completing some initial optimization based on the contents of the FPGA Optimization Report, you can see where to further refine your component by simulating it.
For details, see Evaluate Your Kernel Through Simulation.
SYCL HLS Flow:This step also generates an RTL IP core from your kernel. - (Optional) Obtain More Accurate Kernel Performance Estimates
When you are satisfied with the predicted performance of your kernel, use Intel®Quartus® Prime software to synthesize your kernel. Synthesis also generates accurate area and performance (fMAX) estimates for your design. However, your design is not expected to cleanly close timing in the Intel® Quartus® Prime reports.
To synthesize your kernel, use the -Xshardware compiler command option. Compiling without the -fsycl-link=early compiler command option provides a more accurate estimate of your kernel’s area and fMAX but the compilation takes much longer (hours instead of minutes)
You can expect to see timing closure warnings in the Intel®Quartus® Prime logs because the generated project targets a clock speed of 1000 MHz to achieve the best possible placement for your design. The fMAX value presented in the FPGA Optimization Report estimates the maximum clock rate your component can cleanly close timing for.
To synthesize your kernel and generate quality of results (QoR) data, instruct the compiler to run the Intel® Quartus® Prime compilation flow automatically after synthesizing the components. Include the –Xshardware option in your icpx -fsycl command:
icpx -fsycl -fintelfpga -Xshardware -Xstarget="<FPGA device family or part number>"... - (FPGA Acceleration Flow only) Compile your code to hardware
Use the -Xshardware and -Xstarget= compiler command options to compile your application for the target FPGA acceleration board.
A hardware compilation can take hours.
For details about the hardware compilation in the FPGA Acceleration flow, refer to AOT Compilation Flow in the Intel® oneAPI Programming Guide.
While this step also produces an RTL IP core, you can obtain the same RTL IP core faster without compiling to hardware.
- (SYCL HLS Flow only) Integrate your IP into a system with Intel® Quartus® Prime or Platform Designer.
For details, refer to Integrating Your RTL IP Core Into a System.
The following flowchart shows a coarse-grained progression through the stages of a typical Intel oneAPI FPGA development cycle.