Visible to Intel only — GUID: GUID-0C3CB23E-CAA8-4337-B552-533463A10161
Intel® oneAPI FPGA Handbook
Introduction To FPGA Design Concepts
Intel oneAPI FPGA Development
Defining a Kernel for FPGAs
Debugging and Verifying Your Design
Analyzing Your Design
Optimizing Your Kernel
Optimizing Your Host Application
Integrating Your RTL IP Core Into a System
RTL IP Core Kernel Interfaces
Loops
Pipes
Data Types and Arithmetic Operations
Parallelism
Memories and Memory Operations
Libraries
Additional FPGA Acceleration Flow Considerations
Additional SYCL* HLS Flow Considerations
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the Intel oneAPI FPGA Handbook
Notices and Disclaimers
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Improve fMAX/II with Shannonization
Optimize Inner Loop Throughput
Improve Loop Performance by Caching Data in On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Use SYCL Shared Library With Third-Party Applications
Use of RTL Libraries for FPGA
Object Manifest File Syntax of an RTL Library
Restrictions and Limitations in RTL Support
Intel® Stratix® 10 and Intel Agilex® 7 Design-Specific Reset Requirements for Stall-Free and Stallable RTL Libraries
Stall-Free RTL
Specify Schedule FMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving=<global_memory_name>)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Visible to Intel only — GUID: GUID-0C3CB23E-CAA8-4337-B552-533463A10161
Contiguous Memory Accesses
The Intel® oneAPI DPC++/C++ Compiler attempts to dynamically coalesce accesses to adjacent memory locations to improve global memory efficiency. This is effective if consecutive work items access consecutive memory locations in a given load or store operation. The same is true in a single_task invocation if consecutive loop iterations access consecutive memory locations.
Consider the following code example:
q.submit([&](handler &cgh) { accessor a(a_buf, cgh, read_only); accessor b(b_buf, cgh, read_only); accessor c(c_buf, cgh, write_only, no_init); cgh.parallel_for<class SimpleVadd>(N, [=](id<1> ID) { c[ID] = a[ID] + b[ID]; }); });
The load operation from the accessor a uses an index that is a direct function of the work-item global ID. By basing the accessor index on the work-item global ID, the Intel® oneAPI DPC++/C++ Compiler can ensure contiguous load operations. These load operations retrieve the data sequentially from the input array and send the read data to the pipeline as required. Contiguous store operations then store elements of the result that exits the computation pipeline in sequential locations within global memory.
The following figure illustrates an example of the contiguous memory access optimization:
Contiguous Memory Access
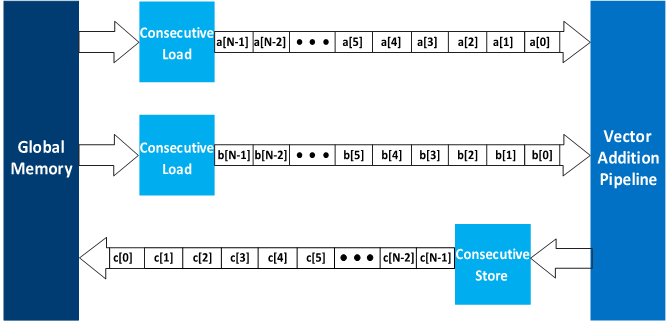
Contiguous load and store operations improve memory access efficiency because they lead to increased access speeds and reduced hardware resource needs. The data travels in and out of the computational portion of the pipeline concurrently, allowing overlaps between computation and memory accesses. Where possible, use work-item IDs that index accesses to arrays in global memory to maximize memory bandwidth efficiency.
Parent topic: Global Memory Accesses Optimization