Intel® Fortran Compiler Classic and Intel® Fortran Compiler Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Supported Native and Non-Native Numeric Formats
Data storage in different computers uses a convention of either little-endian or big-endian storage. The storage convention generally applies to numeric values that span multiple bytes, as follows:
Little-endian storage occurs when:
The least significant bit (LSB) value is in the byte with the lowest address.
The most significant bit (MSB) value is in the byte with the highest address.
The address of the numeric value is the byte containing the LSB. Subsequent bytes with higher addresses contain more significant bits.
Big-endian storage occurs when:
The least significant bit (LSB) value is in the byte with the highest address.
The most significant bit (MSB) value is in the byte with the lowest address.
The address of the numeric value is the byte containing the MSB. Subsequent bytes with higher addresses contain less significant bits.
Intel® Fortran expects numeric data to be in native little-endian order, in which the least-significant, right-most zero bit (bit 0) or byte has a lower address than the most-significant, left-most bit (or byte).
The following figure shows the difference between the two byte-ordering schemes for the case of storing an integer value:

The following figure shows the difference between the two conventions for the case of addressing byte order within words:
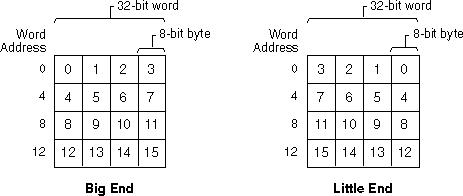
Data types stored as subcomponents (bytes stored in words) end up in different locations within corresponding words of the two conventions. The following figure shows the difference between the representations of character and integer data types in the two conventions. Letters represent 8-bit character data, while numbers represent the 8-bit partial contribution to 32-bit integer data.

If you serially transfer bytes now from the big-endian words to the little-endian words (BE byte 0 to LE byte 0, BE byte 1 to LE byte 1, and so on), the left half of the figure shows how the data ends up in the little-endian words. Note that data of size one byte (characters in this case) is ordered correctly, but that integer data no longer correctly represents the original binary values. The right half of the figure shows that you need to swap bytes around the middle of the word to reconstitute the correct 32-bit integer values. After swapping bytes, the two preceding figures are identical.

You can generalize the previous example to include floating-point data types and to include multiple-word data types.
Moving unformatted data files between big-endian and little-endian computers requires that the data be converted.
Intel Fortran provides the capability for programs to read and write unformatted data (originally written using unformatted I/O statements) in several non-native floating-point formats and in big-endian INTEGER or floating-point format. Supported non-native floating-point formats include Compaq* VAX* little-endian floating-point formats supported by Digital* FORTRAN for OpenVMS* VAX Systems, standard IEEE big-endian floating-point format found on most Sun Microsystems* systems and IBM RISC* System/6000 systems, IBM floating-point formats (associated with the IBM's System/370 and similar systems), and CRAY* floating-point formats.
Converting unformatted data instead of formatted data is generally faster and is less likely to lose precision of floating-point numbers. For unformatted files that contain record lengths before and after the data, specifying big-endian conversion will interpret the lengths as big-endian.
Intel Fortran support of data conversion applies only to I/O list items of instrinsic type (REAL, INTEGER, and so on). I/O list items of derived type are not converted.
The native memory format includes little-endian integers and little-endian IEEE floating-point formats, IEEE binary32 for REAL(KIND=4) and COMPLEX(KIND=4) declarations, IEEE binary64 for REAL(KIND=8) and COMPLEX(KIND=8) declarations, and IEEE binary128 for REAL(KIND=16) and COMPLEX(KIND=16) declarations.
The keywords for supported non-native unformatted file formats and their data types are listed in the following table:
Keyword |
Description |
|---|---|
BIG_ENDIAN |
Big-endian integer data of the appropriate size (one, two, four, or eight bytes) and big-endian IEEE floating-point formats for REAL and COMPLEX single-, double-, and extended-precision numbers. INTEGER(KIND=1) data is the same for little-endian and big-endian. |
CRAY |
Big-endian integer data of the appropriate size (one, two, four, or eight bytes) and big-endian CRAY proprietary floating-point format for REAL and COMPLEX single- and double-precision numbers. |
FDX |
Little-endian integer data of the appropriate size (one, two, four, or eight bytes) and the following little-endian proprietary floating-point formats:
|
FGX |
Little-endian integer data of the appropriate size (one, two, four, or eight bytes) and the following little-endian proprietary floating-point formats:
|
IBM |
Big-endian integer data of the appropriate INTEGER size (one, two, or four bytes) and big-endian IBM proprietary (System\370 and similar) floating-point format for REAL and COMPLEX single- and double-precision numbers. |
LITTLE_ENDIAN |
Native little-endian integers of the appropriate INTEGER size (one, two, four, or eight bytes) and the following native little-endian IEEE floating-point formats:
|
NATIVE |
No conversion occurs between memory and disk. This is the default for unformatted files. |
VAXD |
Native little-endian integers of the appropriate INTEGER size (one, two, four, or eight bytes) and the following little-endian VAX proprietary floating-point formats:
|
VAXG |
Native little-endian integers of the appropriate INTEGER size (one, two, four, or eight bytes) and the following little-endian VAX proprietary floating-point formats:
|
When reading a non-native format, the non-native format on disk is converted to native format in memory. If a converted non-native value is outside the range of the native data type, a runtime message is displayed.