Visible to Intel only — GUID: GUID-92E14BE3-623A-4B5D-9AB0-BCFC258A1779
Prepare for Data Collection
Understand the Intel® VTune™ Profiler Interface
Set Up Project
Set Up Analysis Target
Analyze Performance
Run Intel® VTune™ Profiler Server
Use Intel® VTune™ Profiler with Containers
Recommended Workflows
Intel® VTune™ Profiler Command Line Interface
API Support
Troubleshooting
Reference
Notices and Disclaimers
Prepare Application for Analysis
Windows* Targets
Linux* Targets
Embedded Linux* Targets
FreeBSD* Targets
QNX* Targets
Managed Code Targets
Android* Targets
Intel® Xeon Phi™ Processor Targets
Targets in Virtualized Environments
Targets in a Cloud Environment
Arbitrary Targets
Embedded System Targets
Build and Install the Sampling Drivers for Linux* Targets
Debug Information for Linux* Application Binaries
Compiler Switches for Performance Analysis on Linux* Targets
Enable Linux* Kernel Analysis
Resolution of Symbol Names for Linux-Loadable Kernel Modules
Analyze Statically Linked Binaries on Linux* Targets
Set Up Remote Linux* Target
User-Mode Sampling and Tracing Collection
Hardware Event-based Sampling Collection
Performance Snapshot
Algorithm Group
Microarchitecture Analysis Group
Parallelism Analysis Group
Input and Output Analysis
Accelerators Analysis Group
Platform Analysis Group
Platform Analysis
Hybrid CPU Analysis
Source Code Analysis
Custom Analysis
Energy Analysis
Code Profiling Scenarios
Control Data Collection
Manage Data Views
Manage Result Files
Memory Usage View
Analyze Topology, Memory, and Cross-Socket Bandwidth
View Performance Metrics by Memory Objects (Linux* targets only)
Identify Code Sections and Memory Objects Inducing Bandwidth
Analyze Bandwidth Issues Over Time
Identify Code and Memory Objects with NUMA Issues
Analyze Source
See Also
Switch Viewpoints
Control Window Synchronization
View Stacks
Manage Grid Views
Manage Timeline View
Change Threshold Values
Choose Data Format
Group and Filter Data
View Data on Inline Functions
Analyze Loops
Stitch Stacks for Intel® oneAPI Threading Building Blocks or OpenMP* Analysis
Search for Data
performance-snapshot Command Line Analysis
hotspots Command Line Analysis
anomaly-detection Command Line Analysis
threading Command Line Analysis
memory-consumption Command Line Analysis
hpc-performance Command Line Analysis
uarch-exploration Command Line Analysis
memory-access Command Line Analysis
tsx-exploration Command Line Analysis
tsx-hotspots Command Line Analysis
sgx-hotspots Command Line Analysis
gpu-hotspots Command Line Analysis
gpu-offload Command Line Analysis
npu
xpu
graphics-rendering Command Line Analysis
fpga-interaction Command Line Analysis
io Command Line Analysis
system-overview Command Line Analysis
runsa/runss Custom Command Line Analysis
Configure Analysis Options from Command Line
Collect System-Wide Data from Command Line
Collect Data on Remote Linux* Systems from Command Line
Configure GPU Analysis from Command Line
Specify Search Directories from Command Line
Specify Result Directory from Command Line
Pause Collection from Command Line
Manage Analysis Duration from Command Line
Limit Data Collection from Command Line
Option Descriptions and General Rules
allow-multiple-runs
analyze-kvm-guest
analyze-system
app-working-dir
archive
call-stack-mode
collect
collect-with
column
command
cpu-mask
csv-delimiter
cumulative-threshold-percent
custom-collector
data-limit
discard-raw-data
duration
filter
finalization-mode
finalize
format
group-by
help
import
inline-mode
knob
kvm-guest-kallsyms
kvm-guest-modules
limit
loop-mode
mrte-mode
no-follow-child
no-summary
no-unplugged-mode
quiet
report
report-knob
report-output
report-width
result-dir
resume-after
return-app-exitcode
ring-buffer
search-dir
show-as
sort-asc
sort-desc
source-object
source-search-dir
stack-size
start-paused
strategy
target-install-dir
target-system
target-tmp-dir
target-duration-type
target-pid
target-process
time-filter
trace-mpi
user-data-dir
verbose
version
Best Practices: Resolve Intel® VTune™ Profiler BSODs, Crashes, and Hangs in Windows* OS
Error Message: Application Sets Its Own Handler for Signal
Error Message: Cannot Enable Event-Based Sampling Collection
Error Message: Cannot Collect GPU Hardware Metrics
Error Message: Cannot Load Data File
Error Message: Cannot Locate Debugging Information
Error Message: Cannot Open Data
Error Message: Client Is Not Authorized to Connect to Server
Error Message: Root Privileges Required for Processor Graphics Events
Error Message: No Pre-built Driver Exists for This System
Error Message: Not All OpenCL™ API Profiling Callbacks Are Received
Error Message: Problem Accessing the Sampling Driver
Error Message: Required Key Not Available
Error Message: Scope of ptrace System Call Is Limited
Error Message: Stack Size Is Too Small
Error Message: Symbol File Is Not Found
Problem: Analysis of the .NET* Application Fails
Problem: Cannot Access VTune Profiler Documentation
Problem: CPU time for Hotspots or Threading Analysis is Too Low
Problem: 'Events= Sample After Value (SAV) * Samples' Is Not True If Multiple Runs Are Disabled
Problem: Guessed Stack Frames
Problem: GUI Hangs or Crashes
Problem: Inaccurate Sum in the Grid
Problem: Information Collected via ITT API Is Not Available When Attaching to a Process
Problem: No GPU Utilization Data Is Collected
Problem: Same Functions Are Compared As Different Instances
Problem: Skipped Stack Frames
Problem: Stack in the Top-Down Tree Window Is Incorrect
Problem: Stacks in Call Stack and Bottom-Up Panes Are Different
Problem: System Functions Appear in the User Functions Only Mode
Problem: Intel® VTune™ Profiler is Slow to Respond When Collecting or Displaying Data
Problem: Intel® VTune™ Profiler is Slow on X-Servers with SSH Connection
Problem: Unexpected Paused Time
Problem: {Unknown Timer} in the Platform Power Analysis Viewpoint
Problem: Unknown Critical Error Due to Disabled Loopback Interface
Problem: Unknown Frames
Problem: Unsupported Microsoft* Windows* OS
Context Menu: Grid
Context Menus: Call Stack Pane
Context Menus: Project Navigator
Context Menus: Source/Assembly Window
Dialog Box: Binary/Symbol Search
Dialog Box: Source Search
Hot Keys
Menu: Customize Grouping
Menu: Intel VTune Profiler
Pane: Call Stack
Pane: Options - General
Pane: Options - Result Location
Pane: Options - Source/Assembly
Project Navigator
Pane: Timeline
Toolbar: Configure Analysis
Toolbar: Filter
Toolbar: Source/Assembly
Toolbar: Intel VTune Profiler
Window: Bandwidth - Platform Power Analysis
Window: Bottom-up
Window: Caller/Callee
Window: Cannot Find <file type> File
Window: Collection Log
Window: Compare Results
Window: Configure Analysis
Window: Core Wake-ups - Platform Power Analysis
Window: Correlate Metrics - Platform Power Analysis
Window: CPU C/P States - Platform Power Analysis
Window: Debug
Window: Event Count - Hardware Events
Window: Flame Graph
Window: Graphics - GPU Compute/Media Hotspots
Window: Graphics C/P States - Platform Power Analysis
Window: NC Device States - Platform Power Analysis
Window: Platform
Window: Platform Power Analysis
Window: Sample Count - Hardware Events
Window: SC Device States - Platform Power Analysis
Window: Summary
Window: System Sleep States - Platform Power Analysis
Window: Temperature/Thermal Sample - Platform Power Analysis
Window: Timer Resolution - Platform Power Analysis
Window: Top-down Tree
Window: Uncore Event Count - Hardware Events
Window: Wakelocks - Platform Power Analysis
Window: Summary - Input and Output Summary
Window: Summary - Microarchitecture Exploration
Window: Summary - GPU Analysis
Window: Summary - Hardware Events
Window: Summary - Hotspots by CPU Utilization
Window: Summary - HPC Performance Characterization
Window: Summary - Memory Consumption
Window: Summary - Memory Usage
Window: Summary - Platform Power Analysis
ALU0 Active
ALU0 Instructions
ALU1 Active
ALU1 Instructions
ALU2 Active
ALU2 Instructions
ALU0 and ALU1 Active
ALU0 and ALU2 Active
ALU0 and XMX Utilization
Average Time
Computing Threads Started
Computing Threads Started, Threads/sec
CPU Time
EU 2 FPU Pipelines Active
EU Array Active
EU Array Idle
EU Array Stalled/Idle
EU Array Stalled
EU IPC Rate
EU Send pipeline active
EU Threads Occupancy
Global
GPU EU Array Usage
GPU HW Scheduler Time
GPU Instruction Cache L3 Miss Ratio
GPU L3 Atomics
GPU L3 Bound
GPU L3 Miss Ratio
GPU L3 Misses
GPU L3 Misses, Misses/sec
GPU Load Store Cache Miss Ratio
GPU Load Store Cache L3 Miss Ratio
GPU LSC Atomics
GPU LSC Fences
GPU Media Read Requests
GPU Media Write Requests
GPU SLM Atomics
GPU SLM Fences
GPU Memory Read Bandwidth, GB/sec
GPU Memory Texture Read Bandwidth, GB/sec
GPU Memory Write Bandwidth, GB/sec
GPU Sampler L3 Miss Ratio
GPU Texel Quads Count, Count/sec
GPU Utilization
Graphics Security Controller Busy
Host to GPU Memory Read Bandwidth
Host-to-GPU Memory Write Bandwidth
Instance Count
Instruction Cache Miss Ratio
L3 Busy
L3 Input Available
L3 Instruction Cache Bandwidth
L3 Load Store Cache Read Bandwidth
L3 Load Store Cache Write Bandwidth
L3 Miss Ratio
L3 Output Ready
L3 Read Bandwidth
L3 SQ Full
L3 Stalled
L3 Write Bandwidth
L3 Sampler Bandwidth, GB/sec
L3 Shader Bandwidth, GB/sec
LLC Miss Rate due GPU Lookups
LLC Miss Ratio due GPU Lookups
LSC Input Available
LSC Output Ready
LSC Partial Writes
Local
Maximum GPU Utilization
Multiple Pipe Utilization
Occupancy
PS EU Active %
PS EU Stall %
Ratio to Max Bandwidth, %
Ratio to Max Bandwidth, %
Ratio to Max Bandwidth, %
Render/GPGPU Command Streamer Loaded
Sampler Input Available
Sampler Output Ready
Samples Blended
Samples Killed in PS, pixels
Samples Written
Sampler Busy
Sampler Is Bottleneck
Shared Local Memory Read Bandwidth, GB/sec
Shared Local Memory Write Bandwidth, GB/sec
SIMD Width
SLM Bank Conflicts
Stack-to-stack Incoming Bandwidth
Stack-to-stack Outgoing Bandwidth
System Memory Read Bandwidth
System Memory Write Bandwidth
Size
Total, GB/sec
Thread Dispatcher Active
TLB Misses
Total Time
Typed Memory Read Bandwidth, GB/sec
Typed Memory Write Bandwidth, GB/sec
Typed Reads Coalescence
Typed Writes Coalescence
Untyped Memory Read Bandwidth, GB/sec
Untyped Memory Write Bandwidth, GB/sec
Untyped Reads Coalescence
Untyped Writes Coalescence
Video Codec Busy
Video Codec Read Requests
Video Codec Write Requests
Video Codec 2 Busy
Video Codec 2 Read Requests
Video Codec 2 Write Requests
Video Enhancement Busy
Video Enhancement Read Requests
Video Enhancement Write Requests
Video Enhancement 2 Busy
Video Enhancement 2 Read Requests
Video Enhancement 2 Write Requests
VS EU Active
VS EU Stall
XVE Barrier Stall
XVE Bit Manipulation Instructions
XVE Control Stall
XVE Dist or Acc Stall
XVE INT16\INT32\INT64\FP16\FP32\FP64 Instructions
XVE FP16\BF16\INT8\INT4\INT2 XMX Instructions
XVE Instruction Fetch Stall
XVE Pipe Stall
XVE Send Stall
XVE SBID Stall
XVE XMX Instructions
XVE XMX Pipeline Active
Visible to Intel only — GUID: GUID-92E14BE3-623A-4B5D-9AB0-BCFC258A1779
Memory Usage View
Use the Intel® VTune™ Profiler to analyze cache misses (L1/L2/LLC), memory loads/stores, memory bandwidth and system memory allocation/de-allocation, identify high bandwidth issues and NUMA issues in your memory-bound application.
To analyze memory usage data, run these analysis types:
Memory Access analysis
Microarchitecture Exploration analysis with the Analyze memory bandwidth option enabled
HPC Performance Characterization analysis with the Analyze memory bandwidth option enabled
When the analysis is complete, VTune Profiler opens the Memory Usage viewpoint. This viewpoint displays data per memory-access-correlated event-based metrics. Each metric is an event ratio defined by Intel architects and may have its own predefined threshold. VTune Profiler analyzes a ratio value for each aggregated program unit (for example, function). When this value exceeds the threshold and the program unit has more than 5% of CPU time from the collection CPU time, it signals a potential performance problem and highlights that value.
To interpret performance data obtained through the analysis, follow this procedure:
View performance metrics by memory objects (Linux* targets only).
Identify code sections and memory objects inducing bandwidth.
Analyze Topology, Memory, and Cross-Socket Bandwidth
Start your performance analysis in the Summary window of the Memory Usage viewpoint. Here, the Platform Diagram displays system topology and utilization metrics for DRAM, Intel® UPI links, and physical cores.
Sub-optimal application topology can result in induced DRAM and Intel® QuickPath Interconnect (Intel® QPI) or Intel® Ultra Path Interconnect (Intel® UPI) cross-socket traffic. These incidents can limit performance.

NOTE:
The platform diagram is available for:
- All client platforms
- Server platforms based on Intel® microarchitecture code name Skylake, with up to four sockets.
- Server platforms based on Intel® microarchitecture code named Sapphire Rapids.
High Bandwidth Memory Data in Platform Diagram
For server platforms based on Intel® microarchitecture code named Sapphire Rapids, the Platform Diagram also includes information about High Bandwidth Memory (HBM). Use this information to distinguish from DRAM-specific utilization in the diagram.
For example, this diagram shows information about HBM mode utilization, where the system has no DRAM.

Here is an example of the Platform Diagram data in a system that has both HBM and DRAM.

If you selected the Evaluate max DRAM bandwidth option in your analysis configuration, the Platform Diagram shows the average DRAM utilization. Otherwise, it shows the average DRAM bandwidth.
The Average UPI Utilization metric displays UPI utilization in terms of transmit. Irrespective of the number of UPI links that connect a pair of packages, the Platform Diagram shows a single cross-socket connection, . If there are several links, the diagram displays the maximum value.
On top of each socket, the Average Physical Core Utilization metric indicates the utilization of physical cores by computations of the application under analysis.
Once you examine the topology and utilization information in the diagram, focus on other sections in the Summary window and then switch to the Bottom-up and Platform windows next.
View Performance Metrics by Memory Objects (Linux* targets only)
If you enabled the Analyze dynamic memory objects configuration option for the Memory Access analysis, you can configure the Memory Usage viewpoint to display performance metrics per memory objects (variables, data structures, arrays).
NOTE:
Memory objects identification is supported only for Linux targets and only for processors based on Intel microarchitecture code named Haswell and newer architectures. On Windows*, you can group by Cachelines, see the metrics against the code, and figure out what data structures it accesses.
There are several types of memory objects:
Dynamic memory objects are allocated on heap using the malloc, new, and similar functions. Such objects are identified by the line where an allocation happened; for example, a source line where the malloc function was called.
Global objects are global or static variables. Such objects are identified by the module and variable name, for example: libiomp5.sp!_kmp_avail_proc (4B), where 4B is an allocation size.
Stack objects are local variables. VTune Profiler does not recognize individual variables, so all references to stack memory are associated with one memory object named [Stack].
For memory objects data, click the Bottom-up tab and select a grouping level containing Memory Object or Memory Object Allocation Source. The Memory Object granularity groups the data by individual allocations (call site and size) while Memory Object Allocation Source groups by the place where an allocation happened.
Only metrics based on DLA-capable hardware events are applicable to the memory objects analysis. For example, the CPU Time metric is based on a non DLA-capable Clockticks event, so cannot be applied to memory objects. Examples of applicable metrics are Loads, Stores, LLC Miss Count, and Average Latency.
Identify Code Sections and Memory Objects Inducing Bandwidth
In the Bandwidth Utilization section of the Summary window, you can select a bandwidth domain (like DRAM or Interconnect) and analyze the bandwidth utilization over time represented on the histogram:
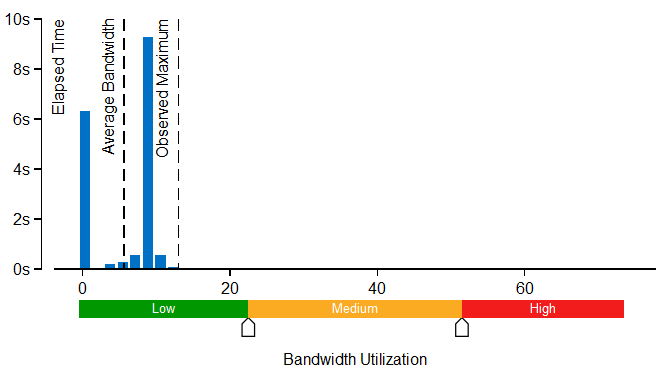
This histogram shows how much time the system bandwidth was utilized by the selected bandwidth domain and provides thresholds to categorize bandwidth utilization as High, Medium and Low. By default, for Memory Analysis results the thresholds are calculated based on the maximum achievable DRAM bandwidth measured by the VTune Profiler before the collection starts and displayed in the System Bandwidth section of the Summary window. To enable this functionality for custom analysis results, make sure to select the Evaluate max DRAM bandwidth option. If this option is not enabled, the thresholds are calculated based on the maximum bandwidth value collected for this result. You can also set the threshold by moving sliders at the bottom. The modified values will be applied to all subsequent results in this project.
Explore the table under the histogram to identify which functions were frequently accessed while the bandwidth utilization for the selected domain was high. Clicking a function from the list opens the Bottom-up window with the grid automatically grouped by Bandwidth Domain / Bandwidth Utilization Type / Function / Call Stack and this function highlighted. Under the DRAM, GB/sec > High utilization type, you can see all functions executing when the system DRAM bandwidth utilization was high. Sort the grid by LLC Miss Count to see what functions contributed to the high DRAM bandwidth utilization the most:

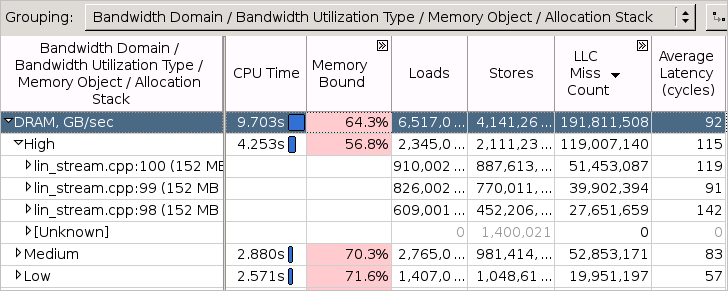
In addition to identifying bandwidth-limited code, the VTune Profiler provides a workflow to see the frequently accessed memory objects (variables, data structures, arrays) that had an impact on the high bandwidth utilization. So, if you enabled the memory object analysis for your target, the Bandwidth Utilization section includes a table with the top memory objects that were frequently accessed while the bandwidth utilization for the selected domain was high. Click such an object to switch to the Bottom-up window with the grid automatically grouped by Bandwidth Domain / Bandwidth Utilization Type / Memory Object / Allocation Stack and this object highlighted. Under the DRAM > High utilization type, explore all memory objects that were accessed when the system DRAM bandwidth utilization was high. Sort the grid by LLC Miss Count to see what memory objects contributed to the high DRAM bandwidth utilization the most:
Analyze Bandwidth Issues Over Time
To identify bandwidth issues in your application over time, focus on the Timeline pane provided at the top of the Bottom-up window. For Memory Analysis results, the DRAM Bandwidth graph is scaled according to the maximum achievable DRAM bandwidth measured by the VTune Profiler before the collection start. To enable this functionality for custom analysis results, make sure to select the Evaluate max DRAM bandwidth option. If this option is not enabled, the thresholds are calculated based on the maximum bandwidth value collected for this result.
Bandwidth events are not associated with any core, but, instead, associated with the uncore (iMC, the integrated memory controller). Uncore events happen on structures shared between all CPUs in a package (for example, 10 CPUs on a single package). This makes it impossible to associate any single uncore event with any code context. So, the VTune Profiler may only associate bandwidth uncore event counts with the socket, or package, on which the uncore event happened, and time.

Hover over a bar with high bandwidth value to learn how much data was read from or written to DRAM through the on-chip memory controller. Use time-filtering context menu options to filter in a specific range of time during which bandwidth is notable. Then, switch to the core-based events that correlate with bandwidth in the grid below to determine what specific code is inducing all the bandwidth.

Identify Code and Memory Objects with NUMA Issues
Many modern multi-socket systems are based on the Non-Uniform Memory Architecture (NUMA) where accesses to the memory allocated on the home (local) CPU socket have better latency/bandwidth than accesses to the remote memory. To identify NUMA issues, focus on the following hierarchically organized metrics in the Bottom-up view:
Memory Bound > DRAM Bound > Local DRAM metric shows a fraction of cycles the CPU stalled waiting for memory loads from the local memory.
Memory Bound > DRAM Bound > Remote DRAM metric shows a fraction of cycles the CPU stalled waiting for memory loads from the remote memory.
Memory Bound > DRAM Bound > Remote Cache metric shows a fraction of cycles the CPU stalled waiting for memory loads from the remote socket cache.
LLC Miss Count > Local DRAM Access Count, LLC Miss Count > Remote DRAM Access Count, LLC Miss Count > Remote Cache Access Count - metrics show the number of accesses to local memory, remote memory and remote cache respectively.
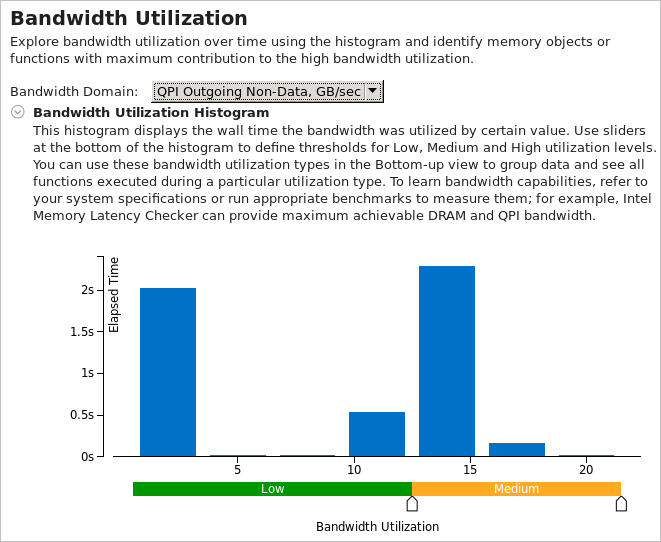
The performance of your application can be also limited by the bandwidth of Interconnect links (inter-socket connections). VTune Profiler provides mechanisms to identify code and memory objects inducing this type of bandwidth similar to those used to identify DRAM bandwidth problems. In the Summary window, use the Bandwidth Utilization Histogram and select Interconnect in the Bandwidth Domain drop-down menu.
If you select the Interconnect Incoming/Outgoing Non-Data categories in the Bandwidth Domain drop-down menu, the histogram displays the bandwidth utilized by hardware generated and system traffic like protocol packet headers, snoop requests and responses, and others:
NOTE:
Interconnect bandwidth analysis is supported by the VTune Profiler for Intel microarchitecture code name Ivy Bridge EP and later.
Switch to the Bottom-up tab and select the Bandwidth Domain / Bandwidth Utilization type / Function / Call Stack grouping level. Expand the Interconnect domain grid row and then expand the High utilization type row to see all functions that were executing when the system Interconnect bandwidth utilization was high:

You can also select areas with the high Interconnect bandwidth utilization in the Timeline view and filter in by this selection:
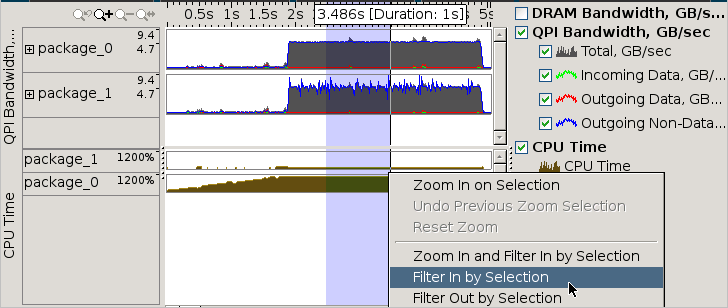
After the filter is applied, the grid view below the Timeline pane shows what was executing during that time range.
Analyze Source
When you identified a critical function, double-click it to open the Source/Assembly window and analyze the source code. The Source/Assembly window displays hardware metrics per code line for the selected function.
To view the Source/Assembly data for memory objects:
Select the ../Function / Memory Object /.. grouping level (the Function granularity should precede the Memory Object granularity) in the Bottom-up window.
Expand a function and double-click a memory object under this function.
The Source/Assembly window opens displaying metrics per function source lines where accesses to the selected memory object happened.
NOTE:
For information on processor event, see Intel Processor Event Reference.
For information on the performance tuning for HPC-computers using the event-based sampling collection, see Tuning Guides and Performance Analysis Papers.
For information on performance improvement opportunities with NUMA hardware, see Optimizing Applications for NUMA.