Visible to Intel only — GUID: GUID-97E748E3-C038-4D93-B26B-2C46B547869A
Prepare for Data Collection
Understand the Intel® VTune™ Profiler Interface
Set Up Project
Set Up Analysis Target
Analyze Performance
Run Intel® VTune™ Profiler Server
Use Intel® VTune™ Profiler with Containers
Recommended Workflows
Intel® VTune™ Profiler Command Line Interface
API Support
Troubleshooting
Reference
Notices and Disclaimers
Prepare Application for Analysis
Windows* Targets
Linux* Targets
Embedded Linux* Targets
FreeBSD* Targets
QNX* Targets
Managed Code Targets
Android* Targets
Intel® Xeon Phi™ Processor Targets
Targets in Virtualized Environments
Targets in a Cloud Environment
Arbitrary Targets
Embedded System Targets
Build and Install the Sampling Drivers for Linux* Targets
Debug Information for Linux* Application Binaries
Compiler Switches for Performance Analysis on Linux* Targets
Enable Linux* Kernel Analysis
Resolution of Symbol Names for Linux-Loadable Kernel Modules
Analyze Statically Linked Binaries on Linux* Targets
Set Up Remote Linux* Target
User-Mode Sampling and Tracing Collection
Hardware Event-based Sampling Collection
Performance Snapshot
Algorithm Group
Microarchitecture Analysis Group
Parallelism Analysis Group
Input and Output Analysis
Accelerators Analysis Group
Platform Analysis Group
Platform Analysis
Hybrid CPU Analysis
Source Code Analysis
Custom Analysis
Energy Analysis
Code Profiling Scenarios
Control Data Collection
Manage Data Views
Manage Result Files
GPU Offload Analysis
Aspects of the GPU Offload Analysis
Configure the Analysis
Run the Analysis
Run from Command Line
Understand the Results
Analyze Multiple GPUs
Naming Convention for GPU Adapters
The GPU Topology Diagram
Analyze Xe Link Usage
Analyze Data Transfer Between Host and Device
Examine Energy Consumption by your GPU
Support for SYCL* Applications using oneAPI Level Zero API
Support for DirectX Applications
See Also
GPU Compute/Media Hotspots Analysis (Preview)
CPU/FPGA Interaction Analysis
NPU Exploration Analysis
XPU Offload Analysis
Switch Viewpoints
Control Window Synchronization
View Stacks
Manage Grid Views
Manage Timeline View
Change Threshold Values
Choose Data Format
Group and Filter Data
View Data on Inline Functions
Analyze Loops
Stitch Stacks for Intel® oneAPI Threading Building Blocks or OpenMP* Analysis
Search for Data
performance-snapshot Command Line Analysis
hotspots Command Line Analysis
anomaly-detection Command Line Analysis
threading Command Line Analysis
memory-consumption Command Line Analysis
hpc-performance Command Line Analysis
uarch-exploration Command Line Analysis
memory-access Command Line Analysis
tsx-exploration Command Line Analysis
tsx-hotspots Command Line Analysis
sgx-hotspots Command Line Analysis
gpu-hotspots Command Line Analysis
gpu-offload Command Line Analysis
npu
xpu
graphics-rendering Command Line Analysis
fpga-interaction Command Line Analysis
io Command Line Analysis
system-overview Command Line Analysis
runsa/runss Custom Command Line Analysis
Configure Analysis Options from Command Line
Collect System-Wide Data from Command Line
Collect Data on Remote Linux* Systems from Command Line
Configure GPU Analysis from Command Line
Specify Search Directories from Command Line
Specify Result Directory from Command Line
Pause Collection from Command Line
Manage Analysis Duration from Command Line
Limit Data Collection from Command Line
Option Descriptions and General Rules
allow-multiple-runs
analyze-kvm-guest
analyze-system
app-working-dir
archive
call-stack-mode
collect
collect-with
column
command
cpu-mask
csv-delimiter
cumulative-threshold-percent
custom-collector
data-limit
discard-raw-data
duration
filter
finalization-mode
finalize
format
group-by
help
import
inline-mode
knob
kvm-guest-kallsyms
kvm-guest-modules
limit
loop-mode
mrte-mode
no-follow-child
no-summary
no-unplugged-mode
quiet
report
report-knob
report-output
report-width
result-dir
resume-after
return-app-exitcode
ring-buffer
search-dir
show-as
sort-asc
sort-desc
source-object
source-search-dir
stack-size
start-paused
strategy
target-install-dir
target-system
target-tmp-dir
target-duration-type
target-pid
target-process
time-filter
trace-mpi
user-data-dir
verbose
version
Best Practices: Resolve Intel® VTune™ Profiler BSODs, Crashes, and Hangs in Windows* OS
Error Message: Application Sets Its Own Handler for Signal
Error Message: Cannot Enable Event-Based Sampling Collection
Error Message: Cannot Collect GPU Hardware Metrics
Error Message: Cannot Load Data File
Error Message: Cannot Locate Debugging Information
Error Message: Cannot Open Data
Error Message: Client Is Not Authorized to Connect to Server
Error Message: Root Privileges Required for Processor Graphics Events
Error Message: No Pre-built Driver Exists for This System
Error Message: Not All OpenCL™ API Profiling Callbacks Are Received
Error Message: Problem Accessing the Sampling Driver
Error Message: Required Key Not Available
Error Message: Scope of ptrace System Call Is Limited
Error Message: Stack Size Is Too Small
Error Message: Symbol File Is Not Found
Problem: Analysis of the .NET* Application Fails
Problem: Cannot Access VTune Profiler Documentation
Problem: CPU time for Hotspots or Threading Analysis is Too Low
Problem: 'Events= Sample After Value (SAV) * Samples' Is Not True If Multiple Runs Are Disabled
Problem: Guessed Stack Frames
Problem: GUI Hangs or Crashes
Problem: Inaccurate Sum in the Grid
Problem: Information Collected via ITT API Is Not Available When Attaching to a Process
Problem: No GPU Utilization Data Is Collected
Problem: Same Functions Are Compared As Different Instances
Problem: Skipped Stack Frames
Problem: Stack in the Top-Down Tree Window Is Incorrect
Problem: Stacks in Call Stack and Bottom-Up Panes Are Different
Problem: System Functions Appear in the User Functions Only Mode
Problem: Intel® VTune™ Profiler is Slow to Respond When Collecting or Displaying Data
Problem: Intel® VTune™ Profiler is Slow on X-Servers with SSH Connection
Problem: Unexpected Paused Time
Problem: {Unknown Timer} in the Platform Power Analysis Viewpoint
Problem: Unknown Critical Error Due to Disabled Loopback Interface
Problem: Unknown Frames
Problem: Unsupported Microsoft* Windows* OS
Context Menu: Grid
Context Menus: Call Stack Pane
Context Menus: Project Navigator
Context Menus: Source/Assembly Window
Dialog Box: Binary/Symbol Search
Dialog Box: Source Search
Hot Keys
Menu: Customize Grouping
Menu: Intel VTune Profiler
Pane: Call Stack
Pane: Options - General
Pane: Options - Result Location
Pane: Options - Source/Assembly
Project Navigator
Pane: Timeline
Toolbar: Configure Analysis
Toolbar: Filter
Toolbar: Source/Assembly
Toolbar: Intel VTune Profiler
Window: Bandwidth - Platform Power Analysis
Window: Bottom-up
Window: Caller/Callee
Window: Cannot Find <file type> File
Window: Collection Log
Window: Compare Results
Window: Configure Analysis
Window: Core Wake-ups - Platform Power Analysis
Window: Correlate Metrics - Platform Power Analysis
Window: CPU C/P States - Platform Power Analysis
Window: Debug
Window: Event Count - Hardware Events
Window: Flame Graph
Window: Graphics - GPU Compute/Media Hotspots
Window: Graphics C/P States - Platform Power Analysis
Window: NC Device States - Platform Power Analysis
Window: Platform
Window: Platform Power Analysis
Window: Sample Count - Hardware Events
Window: SC Device States - Platform Power Analysis
Window: Summary
Window: System Sleep States - Platform Power Analysis
Window: Temperature/Thermal Sample - Platform Power Analysis
Window: Timer Resolution - Platform Power Analysis
Window: Top-down Tree
Window: Uncore Event Count - Hardware Events
Window: Wakelocks - Platform Power Analysis
Window: Summary - Input and Output Summary
Window: Summary - Microarchitecture Exploration
Window: Summary - GPU Analysis
Window: Summary - Hardware Events
Window: Summary - Hotspots by CPU Utilization
Window: Summary - HPC Performance Characterization
Window: Summary - Memory Consumption
Window: Summary - Memory Usage
Window: Summary - Platform Power Analysis
ALU0 Active
ALU0 Instructions
ALU1 Active
ALU1 Instructions
ALU2 Active
ALU2 Instructions
ALU0 and ALU1 Active
ALU0 and ALU2 Active
ALU0 and XMX Utilization
Average Time
Computing Threads Started
Computing Threads Started, Threads/sec
CPU Time
EU 2 FPU Pipelines Active
EU Array Active
EU Array Idle
EU Array Stalled/Idle
EU Array Stalled
EU IPC Rate
EU Send pipeline active
EU Threads Occupancy
Global
GPU EU Array Usage
GPU HW Scheduler Time
GPU Instruction Cache L3 Miss Ratio
GPU L3 Atomics
GPU L3 Bound
GPU L3 Miss Ratio
GPU L3 Misses
GPU L3 Misses, Misses/sec
GPU Load Store Cache Miss Ratio
GPU Load Store Cache L3 Miss Ratio
GPU LSC Atomics
GPU LSC Fences
GPU Media Read Requests
GPU Media Write Requests
GPU SLM Atomics
GPU SLM Fences
GPU Memory Read Bandwidth, GB/sec
GPU Memory Texture Read Bandwidth, GB/sec
GPU Memory Write Bandwidth, GB/sec
GPU Sampler L3 Miss Ratio
GPU Texel Quads Count, Count/sec
GPU Utilization
Graphics Security Controller Busy
Host to GPU Memory Read Bandwidth
Host-to-GPU Memory Write Bandwidth
Instance Count
Instruction Cache Miss Ratio
L3 Busy
L3 Input Available
L3 Instruction Cache Bandwidth
L3 Load Store Cache Read Bandwidth
L3 Load Store Cache Write Bandwidth
L3 Miss Ratio
L3 Output Ready
L3 Read Bandwidth
L3 SQ Full
L3 Stalled
L3 Write Bandwidth
L3 Sampler Bandwidth, GB/sec
L3 Shader Bandwidth, GB/sec
LLC Miss Rate due GPU Lookups
LLC Miss Ratio due GPU Lookups
LSC Input Available
LSC Output Ready
LSC Partial Writes
Local
Maximum GPU Utilization
Multiple Pipe Utilization
Occupancy
PS EU Active %
PS EU Stall %
Ratio to Max Bandwidth, %
Ratio to Max Bandwidth, %
Ratio to Max Bandwidth, %
Render/GPGPU Command Streamer Loaded
Sampler Input Available
Sampler Output Ready
Samples Blended
Samples Killed in PS, pixels
Samples Written
Sampler Busy
Sampler Is Bottleneck
Shared Local Memory Read Bandwidth, GB/sec
Shared Local Memory Write Bandwidth, GB/sec
SIMD Width
SLM Bank Conflicts
Stack-to-stack Incoming Bandwidth
Stack-to-stack Outgoing Bandwidth
System Memory Read Bandwidth
System Memory Write Bandwidth
Size
Total, GB/sec
Thread Dispatcher Active
TLB Misses
Total Time
Typed Memory Read Bandwidth, GB/sec
Typed Memory Write Bandwidth, GB/sec
Typed Reads Coalescence
Typed Writes Coalescence
Untyped Memory Read Bandwidth, GB/sec
Untyped Memory Write Bandwidth, GB/sec
Untyped Reads Coalescence
Untyped Writes Coalescence
Video Codec Busy
Video Codec Read Requests
Video Codec Write Requests
Video Codec 2 Busy
Video Codec 2 Read Requests
Video Codec 2 Write Requests
Video Enhancement Busy
Video Enhancement Read Requests
Video Enhancement Write Requests
Video Enhancement 2 Busy
Video Enhancement 2 Read Requests
Video Enhancement 2 Write Requests
VS EU Active
VS EU Stall
XVE Barrier Stall
XVE Bit Manipulation Instructions
XVE Control Stall
XVE Dist or Acc Stall
XVE INT16\INT32\INT64\FP16\FP32\FP64 Instructions
XVE FP16\BF16\INT8\INT4\INT2 XMX Instructions
XVE Instruction Fetch Stall
XVE Pipe Stall
XVE Send Stall
XVE SBID Stall
XVE XMX Instructions
XVE XMX Pipeline Active
Visible to Intel only — GUID: GUID-97E748E3-C038-4D93-B26B-2C46B547869A
GPU Offload Analysis
Explore code execution on various CPU and GPU cores on your platform, correlate CPU and GPU activity, and identify whether your application is GPU or CPU bound.
NOTE:
Use the XPU Offload analysis type for a comprehensive view of performance data for your CPU, GPU, and NPU. In a future release, the GPU Offload analysis type will be integrated into the XPU Offload analysis type.
Run the GPU Offload analysis for applications that use a Graphics Processing Unit (GPU) for rendering, video processing, and computations with explicit support of SYCL*, Intel® Media SDK and OpenCL™ software technology.
The tool infrastructure automatically aligns clocks across all cores in the entire system so that you can analyze some CPU-based workloads together with GPU-based workloads within a unified time domain.
This analysis enables you to:
Identify how effectively your application uses SYCL or OpenCL kernels and explore them further with GPU Compute/Media Hotspots analysis
Analyze execution of Intel Media SDK tasks over time (for Linux targets only)
Explore GPU usage and analyze a software queue for GPU engines at each moment of time
For the GPU Offload analysis, Intel® VTune™ Profiler instruments your code executing both on CPU and GPU. Depending on your configuration settings, VTune Profiler provides performance metrics that give you an insight into the efficiency of GPU hardware use. You can also identify next steps in your analysis.

Aspects of the GPU Offload Analysis
By default, the GPU Offload analysis enables the GPU Utilization option to explore GPU busyness over time and understand whether your application is CPU or GPU bound. Consequently, if you explore the Timeline view in the Graphics window, you may observe:
- The GPU is busy most of the time
- There are small idle gaps between busy intervals
- The GPU software queue is rarely decreased to zero
If these behaviors exist, you can conclude that your application is GPU bound.
If the gaps between busy intervals are big and the CPU is busy during these gaps, your application is CPU bound.
But such obvious situations are rare and you need a detailed analysis to understand all dependencies. For example, an application may be mistakenly considered GPU bound when the usage of GPU engines is serialized (for example, when GPU engines responsible for video processing and for rendering are loaded in turns). In this case, an ineffective scheduling on the GPU results from the application code running on the CPU.
Configure the Analysis
On Windows systems, to monitor general GPU usage over time, run VTune Profiler as an Administrator.
For SYCL applications: make sure to compile your code with the -gline-tables-only and -fdebug-info-for-profiling Intel oneAPI DPC++ Compiler options.
Create a project and specify an analysis system and target.
Run the Analysis
Open the Configure Analysis window. Click the
 button on the welcome screen (standalone version) or the
button on the welcome screen (standalone version) or the  Configure Analysis(Visual Studio IDE) toolbar button.
Configure Analysis(Visual Studio IDE) toolbar button. Open the Analysis Tree from the HOW pane and select GPU Offload analysis from the Accelerators group.
The GPU Offload analysis is pre-configured to collect GPU usage data and collect Processor Graphics hardware events (Global Memory Accesses preset).
NOTE:If you have multiple Intel GPUs connected to your system, run the analysis on the GPU of your choice or on all connected devices. For more information, see Analyze Multiple GPUs.
Configure these GPU analysis options:
Use the Trace GPU programming APIs option to analyze SYCL, Level-Zero, OpenCL™, and Intel Media SDK programs running on Intel Processor Graphics. This option may affect the performance of your application on the CPU side.
Use the Collect host stacks option to analyze call stacks executed on the CPU and identify critical paths. You can also examine the CPU-side stacks for GPU computing tasks to investigate the efficiency of your GPU offload. When results display, sort through SYCL*, Level-Zero, or OpenCL™ runtime call stacks by selecting a Call Stack mode in the filter bar.
Use the Analyze CPU-GPU bandwidth option to display data transfers based on hardware events on the timeline. This type of analysis requires Intel sampling drivers to be installed.
For GPUs with Xe Link connections, use the Analyze Xe Link Usage option to examine the traffic between GPU interconnects (Xe Link). This information can help you assess data flow between GPUs and the usage of the Xe Link.
Use the Show GPU performance insights option to get metrics (based on the analysis of Processor Graphics events) that help you estimate the efficiency of hardware usage and learn next steps. The following Insights metrics are collected:
The EU Array metric shows the breakdown of GPU core array cycles, where:
Active: The normalized sum of all cycles on all cores spent actively executing instructions. Formula:
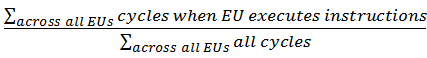
Stalled: The normalized sum of all cycles on all cores spent stalled. At least one thread is loaded, but the core is stalled for some reason. Formula:

Idle: The normalized sum of all cycles on all cores when no threads were scheduled on a core. Formula:

The EU Threads Occupancy metric shows the normalized sum of all cycles on all cores and thread slots when a slot has a thread scheduled.
The Computing Threads Started metric shows the number of threads started across all EUs for compute work.

If you run the GPU Offload analysis on Intel hardware platforms that support the collection of events from media engines, you see an additional option in the GUI for this purpose. Check the Analyze Hardware Events from Media Engines of Intel Processor Graphics option. The media metrics collected in the analysis can vary depending on the hardware you use.

Intel architectures that support the collection of events from media engines include (and are not limited to) microarchitectures code named:
- Meteor Lake
- Arrow Lake
- Lunar Lake
- Battlemage
Click Start to run the analysis.
NOTE:
Families of Intel® Xe graphics products starting with Intel® Arc™ Alchemist (formerly DG2) and newer generations feature GPU architecture terminology that shifts from legacy terms. For more information on the terminology changes and to understand their mapping with legacy content, see GPU Architecture Terminology for Intel® Xe Graphics.
Run from Command Line
To run the GPU Offload analysis from the command line, type this command:
$ vtune -collect gpu-offload [-knob <knob_name=knob_option>] -- <target> [target_options]
NOTE:
To generate the command line for any analysis configuration, use the Command Line button at the bottom of the interface.
Understand the Results
Once the GPU Offload analysis completes data collection, the Summary window displays metrics that describe:
- GPU usage
- GPU idle time
- Xe Link Usage
- The most active computing tasks that ran on the CPU host
- The most active computing tasks that ran on the CPU when the GPU was idle
- The most active Intel® oneAPI Collective Communications Library (oneCCL) communication tasks
- The most active computing tasks that ran on the GPU, along with occupancy information
 You also see Recommendations and guidance for next steps.
You also see Recommendations and guidance for next steps.
Analyze Multiple GPUs
If you connect multiple Intel GPUs to your system, VTune Profiler identifies all of these adapters in the Target GPU pull down menu. Follow these guidelines:
- Use the Target GPU pulldown menu to specify the device you want to profile.
- The Target GPU pulldown menu displays only when VTune Profiler detects multiple GPUs running on the system. The menu then displays the name of each GPU with the bus/device/function (BDF) of its adapter. You can also find this information on your Windows (see Task Manager) or Linux (run lspci) system.
- If you do not select a GPU, VTune Profiler selects the most recent device family in the list by default.
- Select All devices to run the analysis on all of the GPUs connected to your system.
- Full compute set in Characterization mode is not available for multi-adapter/tile analysis.
Once the analysis completes, VTune Profiler displays summary results per GPU including tile information in the Summary window.
Naming Convention for GPU Adapters
The results of GPU profiling analyses use aliases to refer to GPU adapters. .
- Aliases identify GPU adapters in the Summary, Grid, and Timeline sections of profiling results. The full names of GPU adapters display in the Collection and Platform Information sections, along with BDF details.
- A single alias identifies a GPU adapter for all results collected on the same machine.
- Aliases follow the naming convention GPU 0,GPU 1, and so on.
- The assignment of aliases happens in this order:
- Intel GPU adapters, starting with the lowest PCI address
- Non-Intel GPU adapters
- Other software devices like drivers
The GPU Topology Diagram
When you run a GPU analysis across multiple Intel GPUs (or multi-stack GPUs) connected to your system, the Summary window displays interconnections between these GPUs in the GPU Topology diagram. This diagram contains cross-GPU information for a maximum of 2 sockets and 6 GPUs connected to the system.

The GPU Topology diagram displays topological information about the sockets (available for GPU connection) as well as interconnect (Xe Link) connections between GPUs. You can identify GPUs in the GPU Topology diagram by their Bus Device Function (BDF) numbers.
Hover over a GPU stack to see actively utilized links (highlighted in green) and corresponding bandwidth metrics.

Use the information presented here to see average data transferred:
- Through Xe Links
- Between GPU stacks
- Between GPUs and sockets
Analyze Xe Link Usage
For GPUs with Xe Link connections, when you check the option (before running the analysis) to analyze interconnect (Xe Link) usage, the Summary window includes a section that displays the aggregated bandwidth and traffic data through GPU interconnects (Xe Link). Use this information with the GPU Topology diagram to detect any imbalances in the distribution of traffic between GPUs. See if some links are used more frequently than others, and understand why this is happening.

Analyze Overtime Data
Along with the Xe Link usage information in the Summary window, the Platform window displays bandwidth data over time.

Use this information to:
- Match traffic data with kernels or code execution.
- See the bandwidth during any time of the execution of the application.
- Understand how the use of Xe Links improves the performance of your application.
- Verify if the Xe Links reached the bandwidth expected during application execution.
Analyze Data Transfer Between Host and Device
To understand the efficiency of data transfer between the CPU host and GPU device, see metrics in the Summary and Graphics windows.
The Summary window displays the total time spent on computing tasks as well as the execution time per task. The difference indicates the amount of time spent on data transfers between host and device. If the execution time is lower than the data transfer time, this indicates that your offload schema could benefit from optimization.
In the Summary window, look for offload cost metrics including Host-to-Device Transfer and Device-to-Host Transfer. These metrics can help you locate unnecessary memory transfers that reduce performance.
In the Graphics window, see the Total Time by Device Operation Type column, which displays the total time for each computation task.

The total time is broken down into:
- Allocation time
- Time for data transfer from host to device
- Execution time
- Time for data transfer from device to host
This breakdown can help you understand better the balance between data transfer and GPU execution time. The Graphics window also displays in the Transfer Size section, the size of the data transfer between host and device per computation task.
Computation tasks with sub-optimal offload schemas are highlighted in the table with details to help you improve those schemes.

Examine Energy Consumption by your GPU
In Linux environments, when you run the GPU Offload analysis on an Intel® Iris® X e MAX graphics discrete GPU, you can see energy consumption information for the GPU device. To collect this information, make sure you check the Analyze power usage option when you configure the analysis.

NOTE:
Energy consumption metrics do not display in GPU profiling analyses that scan Intel® Iris® X e MAX graphics on Windows machines.
Once the analysis completes, see energy consumption data in these sections of your results.
In the Graphics window, observe the Energy Consumption column in the grid when grouped by Computing Task. Sort this column to identify the GPU kernels that consumed the most energy. You can also see this information mapped in the timeline.
Tune for Power Usage
When you locate individual GPU kernels that consume the most energy, for optimum power efficiency, start by tuning the top energy hotspot.
Tune for Processing Time
If your goal is to optimize GPU processing time, keep a check on energy consumption metrics per kernel to monitor the tradeoff between performance time and power use.
Move the Energy Consumption column next to Total Time to make this comparison easier.

You may notice that the correlation between power use and processing time is not direct. The kernels that compute the fastest may not be the same kernels that consume the least amounts of energy. Check to see if larger values of power usage correspond to longer stalls/wait periods.
Support for SYCL* Applications using oneAPI Level Zero API
This section describes support in the GPU Offload analysis for SYCL applications that run OpenCL or oneAPI Level Zero API in the back end. VTune Profiler supports version 1.0.4 of the oneAPI Level Zero API.
Support Aspect |
SYCL application with OpenCL as back end |
SYCL application with Level Zero as back end |
|---|---|---|
Operating System |
Linux OS Windows OS |
Linux OS Windows OS |
Data collection |
VTune Profiler collects and shows GPU computing tasks and the GPU computing queue. |
VTune Profiler collects and shows GPU computing tasks and the GPU computing queue. |
Data display |
VTune Profiler maps the collected GPU HW metrics to specific kernels and displays them on a diagram. |
VTune Profiler maps the collected GPU HW metrics to specific kernels and displays them on a diagram. |
Display Host side API calls |
Yes |
Yes |
Source Assembler for computing tasks |
Yes |
Yes |
Support for DirectX Applications
This section describes support available in the GPU analysis to trace Microsoft® DirectX* applications running on the CPU host. This support is available in the Launch Application mode only.
| Support Aspect | DirectX Application |
|---|---|
Operating system |
Windows OS |
API version |
DXGI, Direct3D 11, Direct3D 12, Direct3D 11 on 12 |
Display host side API calls |
Yes |
Direct Machine Learning (DirectML) API |
Yes |
Device side computing tasks |
No |
Source Assembler for computing tasks |
No |
Parent topic: Accelerators Analysis Group