Developer Guide
Intel oneAPI DPC++/C++ Compiler Handbook for Intel FPGAs
A newer version of this document is available. Customers should click here to go to the newest version.
Mapping Parallelism Models to FPGA Hardware
This section describes various mechanisms for mapping parallelism models to FPGA hardware:
Data Parallelism
Traditional instruction set architecture (ISA)-based accelerators, such as GPUs, derive data parallelism from vectorized instructions and execute the same operation on multiple processing units. In comparison, FPGAs derive their performance by taking advantage of their spatial architecture. FPGA compilers do not require you to vectorize your code. The compiler vectorizes your code automatically whenever it can.
The generated hardware implements data parallelism in the following ways:
Executing Independent Operations Simultaneously
As described in Mapping Operations to Hardware, the compiler can automatically identify independent operations and execute them simultaneously in hardware. This, when combined with pipelining (explained below), is how performance through data parallelism is achieved on the FPGA.
The following image illustrates an example of an adder and a multiplier, which are scheduled to execute simultaneously while operating on separate inputs:
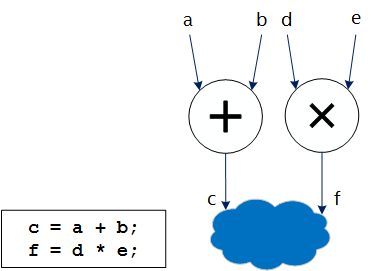
This automatic vectorization is analogous to how a superscalar processor takes advantage of instruction-level parallelism, but this vectorization happens statically at compile time instead of dynamically, at runtime. This means that there is no hardware or runtime cost of dependency checking for the generated hardware datapath. Additionally, the flexible logic and routing of an FPGA mean that only the available resources (ALMs, DSPs, and so on) of the FPGA bound the number of independent operations operating simultaneously.
Unrolling Loops
You can unroll loops in the design by using loop attributes. Loop unrolling decreases the number of iterations executed at the expense of increasing hardware resource consumption corresponding to executing multiple iterations of the loop simultaneously. Once unrolled, the hardware resources are scheduled as described in Scheduling.
Conditional Statements
The Intel® oneAPI DPC++/C++ Compiler attempts to eliminate conditional or branch statements as much as possible. Conditionally executed code becomes predicated in the hardware. Predication increases the possibilities for executing operations simultaneously and achieving better performance. Additionally, removing branches allows the compiler to apply other optimizations to the design.
In the following example, the function foo runs unconditionally. The code that cannot be run unconditionally, like the memory assignments, retains a condition.
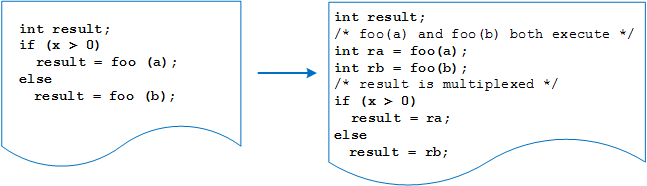
Pipelining
Similar to implementing a CPU with multiple pipeline stages, the compiler generates a deeply pipelined hardware datapath. For more information, refer to Concepts of FPGA Hardware Design and Mapping Source Code Instructions to Hardware. Pipelining allows for many data items to be processed concurrently while efficiently using the hardware in the datapath by keeping it occupied.
Example of Vectorization of the Datapath vs. Pipelining the Datapath
Consider the following example of code mapping to hardware:
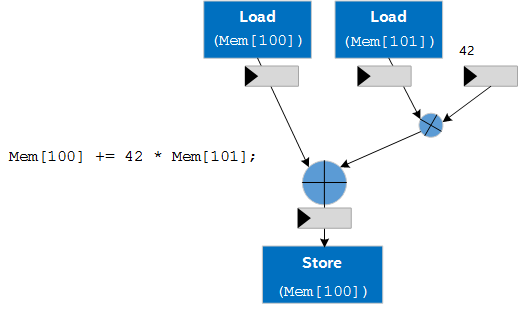
Multiple invocations of this code when running on a CPU would not be pipelined. The output of an invocation is completed before inputs are passed to the next invocation of the code. On an FPGA device, this kind of unpipelined invocation results in poor throughput and low occupancy of the datapath because many of the operations are sitting idle while other parts of the datapath are operating on the data.
The following figure shows what throughput and occupancy of invocations look like in this scenario:
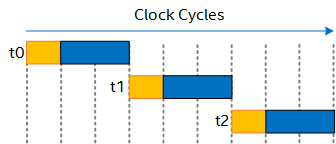
The Intel® oneAPI DPC++/C++ Compiler pipelines your design as much as possible. New inputs can be sent into the datapath each cycle, giving you a fully occupied datapath for higher throughput, as shown in the following figure:
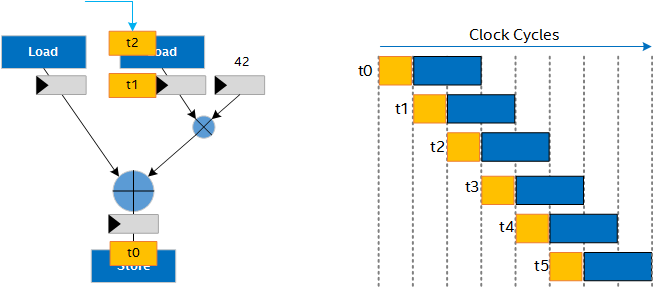
You can gain even further throughput by vectorizing the pipelined hardware. Vectorizing the hardware improves throughput but requires more FPGA area for the additional copies of the pipelined hardware:
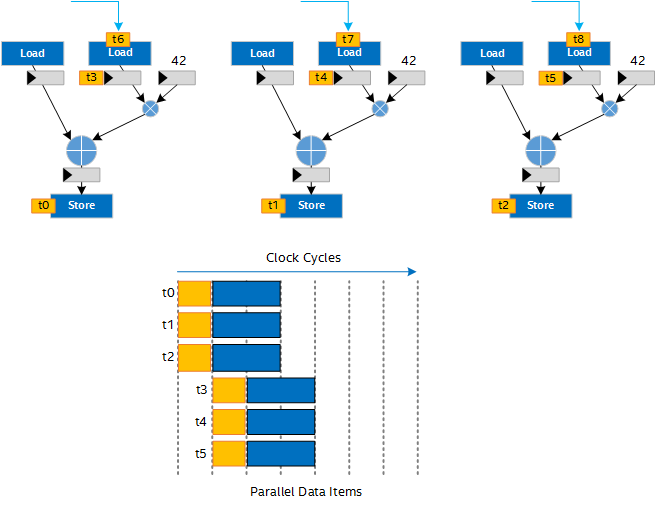
Understanding where the data you need to pipeline is coming from is key to achieving high-performance designs on the FPGA. You can use the following sources of data to take advantage of pipelining:
- Work items
- Loop iterations
Pipelining Loops
The Intel® oneAPI DPC++/C++ Compiler can apply the principles of datapath pipelining to loops in your code. When the Intel® oneAPI DPC++/C++ Compiler pipelines a loop, it attempts to schedule the loop’s execution such that the next iteration of the loop enters the pipeline before the previous iteration has completed. This pipelining of loop iterations can lead to higher performance.
The number of clock cycles between iterations of the loop is called the Initiation Interval (II). For the highest performance, a new iteration of the loop would start every clock cycle corresponding to an II of 1. Data dependencies that are carried from one iteration of the loop to another can affect the ability to achieve an II of 1. These dependencies are called loop carried dependencies. The II of the loop must be high enough to accommodate all loop carried dependencies.
The II required to satisfy this constraint is a function of the fMAX of the design. If the fMAX is lower, the II might also be lower. Conversely, if the fMAX is higher, a higher II might be required. The Intel® oneAPI DPC++/C++ Compiler automatically identifies these dependencies and builds hardware to resolve them while minimizing the II, subject to the target fMAX.
Naively generating hardware for the code in Figure 7 results in two loads: one from memory b and one from memory c. Because the compiler knows that the access to c[i-1] was written to in the previous iteration, the load from c[i-1] can be optimized away.
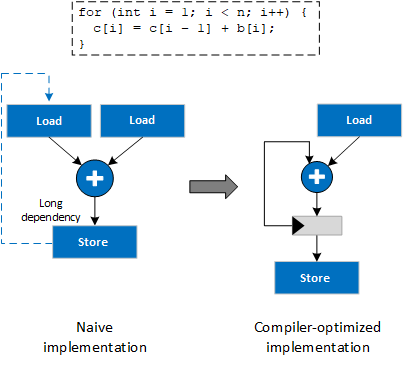
The dependency on the value stored to c in the previous iteration is resolved in a single clock cycle, so an II of 1 is achieved for the loop even though the iterations are not independent.
In cases where the Intel® oneAPI DPC++/C++ Compiler cannot initially achieve II of 1, you have several optimization strategies to choose from:
- Interleaving: When a loop nest with an inner loop II is greater than 1, the Intel® oneAPI DPC++/C++ Compiler can attempt to interleave iterations of the outer loop into iterations of the inner loop to utilize the hardware resources better and achieve higher throughput.
Interleaving
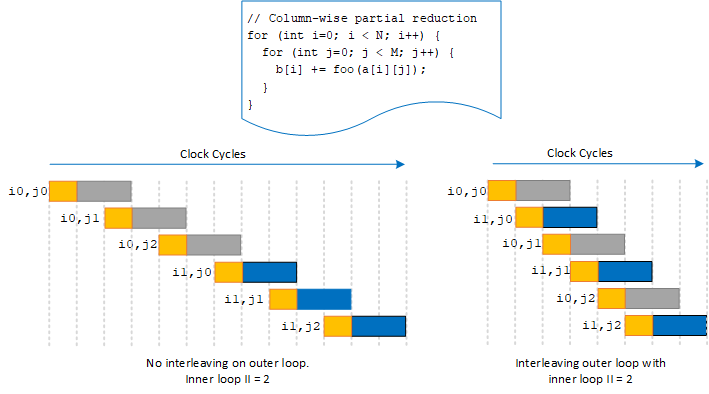
For additional information about controlling interleaving in your kernel, refer to max_interleaving Attribute.
- Speculative Execution: When the critical path affecting II is the computation of the loop's exit condition and not a loop carried dependency, the Intel® oneAPI DPC++/C++ Compiler can attempt to relax this scheduling constraint by speculatively continuing to execute iterations of the loop while the exit condition is being computed. If it is determined that the exit condition is satisfied, the effects of these extra iterations are suppressed. This speculative iteration can achieve lower II and higher throughput, but it can incur additional overhead between the loop invocations (equivalent to the number of speculated iterations). A larger loop trip count helps to minimize this overhead.
NOTE:
A loop invocation is what starts a series of loop iterations. One loop iteration is one execution of the body of a loop.
Loop Orchestration Without Speculative Execution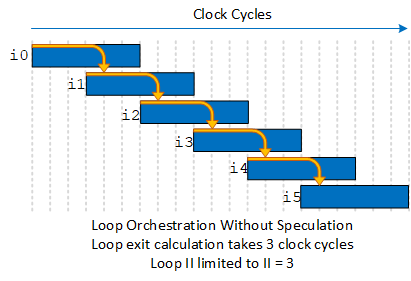
Loop Orchestration With Speculative Execution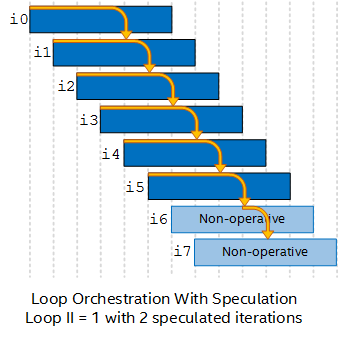
These optimizations are applied automatically by the Intel® oneAPI DPC++/C++ Compiler, and they can also be controlled through pragma statements and loop attributes in the design. For additional information, refer to speculated_iterations Attribute
Pipelining Across Multiple Work Items
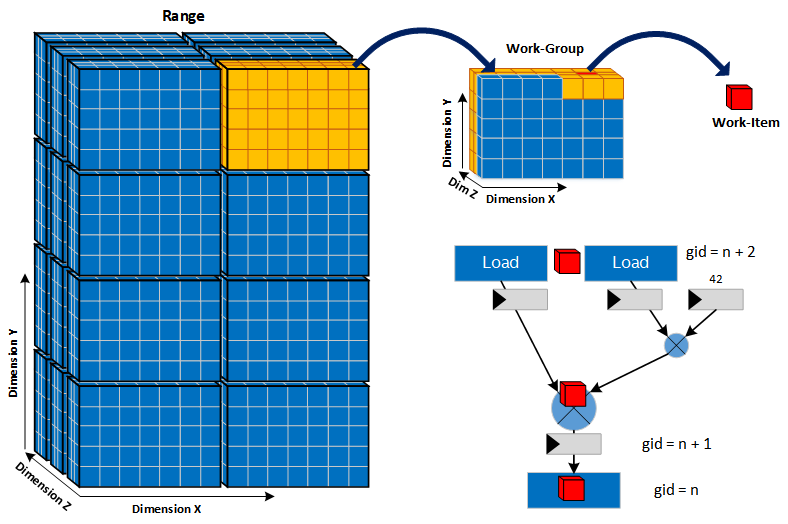
A workgroup (a range of work items) represents a large set of independent data that can be processed in parallel. Since there are no implicit dependencies between work items, at every clock cycle, the next work item can always enter kernel’s datapath before previous work items have completed, unless there is a dynamic stall in the datapath. The following figure illustrates the pipeline in Figure 3 filled with work items:
Loops are not pipelined for kernels that use more than one work item in the current version of the compiler. This will be relaxed in a future release.
Task Parallelism
While the compiler achieves concurrency by scheduling independent individual operations to execute simultaneously, it does not achieve concurrency at coarser granularities (for example, across loops).
For larger code structures to execute in parallel, you must write them as separate kernels that launch simultaneously. These kernels then run asynchronously with each other, and you can achieve synchronization and communication using pipes, as illustrated in the following figure:
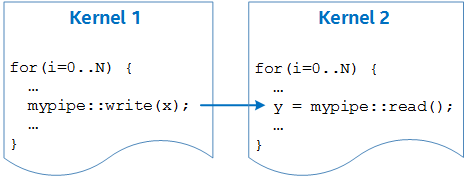
This is similar to how a CPU program can leverage threads running on separate cores to achieve simultaneous asynchronous behavior.