A newer version of this document is available. Customers should click here to go to the newest version.
Examine Regions Recommended for Offloading
Accuracy Level
Low
Enabled Analyses
Survey + Characterization (Trip Counts and FLOP) + Performance Modeling with no assumed dependencies
Result Interpretation
After running the Offload Modeling perspective with Low accuracy, you get a basic Offload Modeling report, which shows you estimated performance of your application after offloading to a target platform assuming it is mostly bounded by compute limitations.
Offload Modeling with Low accuracy assumes that:
- There is no tax for transferring data between baseline and target platforms.
- All data goes to L1/L3 cache level only. L1/L3 cache traffic estimation might be inaccurate.
- A loop is parallel if the loop dependency type in unknown (Assume Dependencies checkbox is disabled). This happens when there is no information about a loop dependency type from a compiler or the loop is not explicitly marked as parallel, for example, with a programming model (OpenMP*, SYCL, Intel® oneAPI Threading Building Blocks (oneTBB))
In the Offload Modeling report:
Review the metrics for the whole application in the Summary tab.
- Check if your application is profitable to offload to a target device or if it has a better performance on a baseline platform in the Program Metrics panes.
- See what prevents your code from achieving a better performance if executed on a target device in the Offload Bounded by pane.
NOTE:If you enable Assume Dependencies option for the Performance Modeling analysis, you might see high percentage of dependency-bound code regions. You are recommended run the Dependencies analysis and rerun Performance Modeling to get more accurate results.
- If the estimated speed-up is high enough and other metrics in the Summary pane suggest that your application can benefit from offloading to a selected target platform, you can start offloading your code.
If you want to investigate the results reported for each region in more detail, go to the Accelerated Regions tab and select a code region:
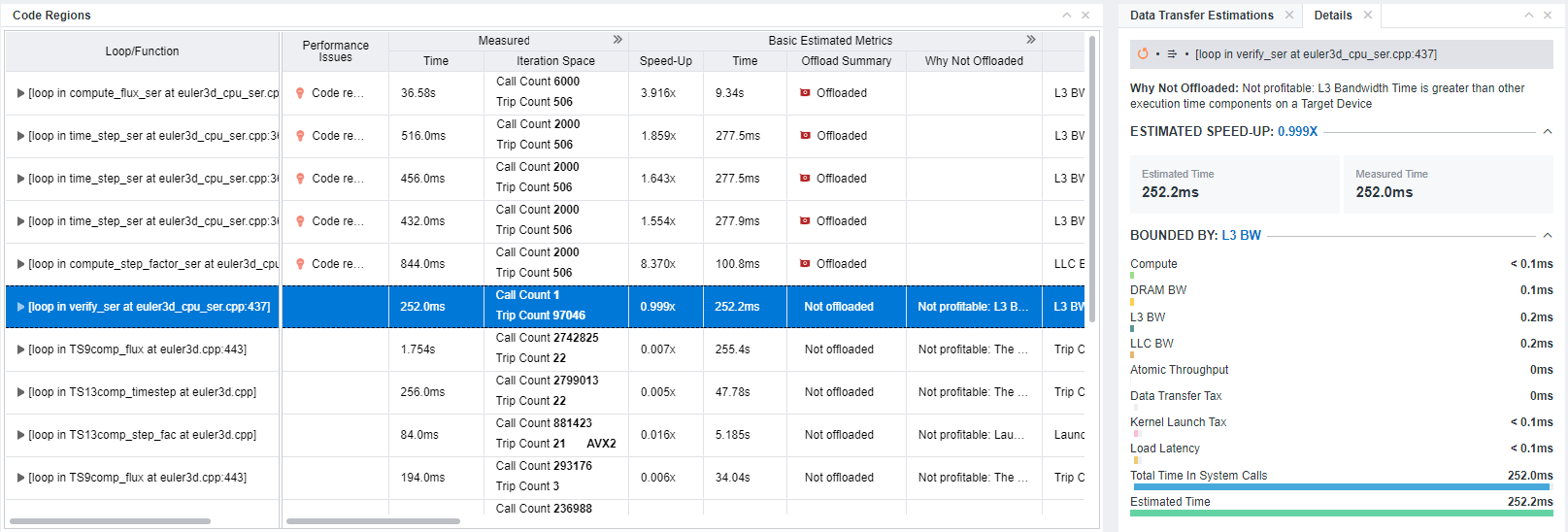
- Check whether your target code region is recommended for offloading to a selected platform. In the Basic Estimated Metrics column group, review the Offload Summary column. The code region is considered profitable for offloading if estimated speed-up is more than 1, that is, estimated time execution on a target device is smaller that on a host platform.
If your code region of interest is not recommended for offloading, consider re-running the perspective with a higher accuracy or refer to Investigate Not Offloaded Code Regions for recommendations on how to model offloading for this code region.
- Examine the Bounded By column of the Estimated Bounded By group in the code region pane to identify the main bottleneck that limits the performance of the code region (see the Bounded by section). The metrics show one or more bottleneck(s) in a code region.
- In the Throughput column of the Estimated Bounded By group, review time spent for compute- and L3 cache bandwidth-bound parts of your code. If the value is high, consider optimizing compute and/or L3 cache usage in your application.
- Review the metrics in the Compute Estimates column group to see the details about instructions and number of threads used in each code region.
- Check whether your target code region is recommended for offloading to a selected platform. In the Basic Estimated Metrics column group, review the Offload Summary column. The code region is considered profitable for offloading if estimated speed-up is more than 1, that is, estimated time execution on a target device is smaller that on a host platform.
- Get guidance for offloading your code to a target device and optimizing it so that your code benefits the most in the Recommendations tab. If the code region has room for optimization or underutilizes the capacity of the target device, Intel Advisor provides you with hints and code snippets that may be helpful to you for further code improvement.
- View the offload summary and details for the selected code region in the Details pane.
For details about metrics reported, see Accelerator Metrics.
Next Steps
- If you think that the estimated speedup is enough and the application is ready to be offloded, rewrite your code to offload profitable code regions to a target platform and measure performance of GPU kernels with GPU Roofline Insights perspective.
- Consider running the Offload Modeling perspective with a higher accuracy level to get a more detailed report.