Visible to Intel only — GUID: tof1696535020995
Ixiasoft
1. Answers to Top FAQs
2. About This Application Note
3. Component Bandwidth Projections and Limitations
4. Resource Planning for Intel Agilex® 7 M-Series FPGAs
5. Factors Affecting NoC Performance
6. Debugging the NoC
7. Document Revision History of AN 1003: Multi Memory IP System Resource Planning for Intel Agilex® 7 M-Series FPGAs
4.1. Hard Memory NoC Resource Planning Overview
4.2. I/O Bank Blockage
4.3. Planning Avalon® Streaming Utilization
4.4. Planning for Initiator Blockage Impact from GPIO, LVDS SERDES, and PHY Lite Bypass Mode
4.5. Planning NoC PLL and I/O PLL
4.6. Pin Planning for HPS EMIF
4.7. Planning for an External Memory Interface
4.8. Planning for HBM2E
4.9. Planning for the Fabric NoC
4.10. Planning for AXI4-Lite
4.11. Planning NoC and Memory Solution Clocks
5.1. Recommended Performance Tuning Procedure
5.2. NoC Initiator and Target Clock Rate
5.3. Recommended NoC Design Topologies
5.4. Traffic Access Pattern and Memory Controller Efficiency
5.5. Traffic Access Pattern Due To Multiple Traffic Flows
5.6. Transaction Size
5.7. Congestion Interaction
5.8. Bandwidth Sharing At Each Switch
5.9. Exceeding NoC Bandwidth Limits
5.10. Maximum Number of Outstanding Transactions
5.11. QoS Priority
5.12. AxID
5.13. Example: 2x2 HBM Crossbars
5.14. Example: 16x16 Crossbar
Visible to Intel only — GUID: tof1696535020995
Ixiasoft
5.8. Bandwidth Sharing At Each Switch
Bandwidth sharing at each switch can impact NoC performance. When fully loaded, each switch in the NoC splits access between its inputs evenly. This splitting creates a potential starvation scenario for connections that span long distances over the NoC. Consider the impact this has on the following topology, consisting of 8 initiators (INIU) writing to one target (TNIU). These initiators all use the same link because they are all going to the same target.
Figure 30. Potential Bandwidth Starvation Scenario
At the switch in the middle, the available bandwidth is divided into two, equally for the left and right half of the initiators. Therefore, you can expect equal performance between the left- and right-half initiators. You can also expect initiators 1, 2, 3, and 4 to collectively have the same bandwidth as initiators 6, 7, 8, and 9.
However, notice how this division continues along the left side (and similarly down the right). The bandwidth is split between initiator 3 and the set of initiators 1, 2, and 3. At the next switch (above initiator 3) the bandwidth is split evenly between initiator 3 and the set of initiators 1 and 2. Finally, initiators 1 and 2 equally share bandwidth. The collective result is a continuous reduction of bandwidth down the NoC, as Relative Throughput At Each Initiator (INIU) shows.
Figure 31. Relative Throughput At Each Initiator (INIU)
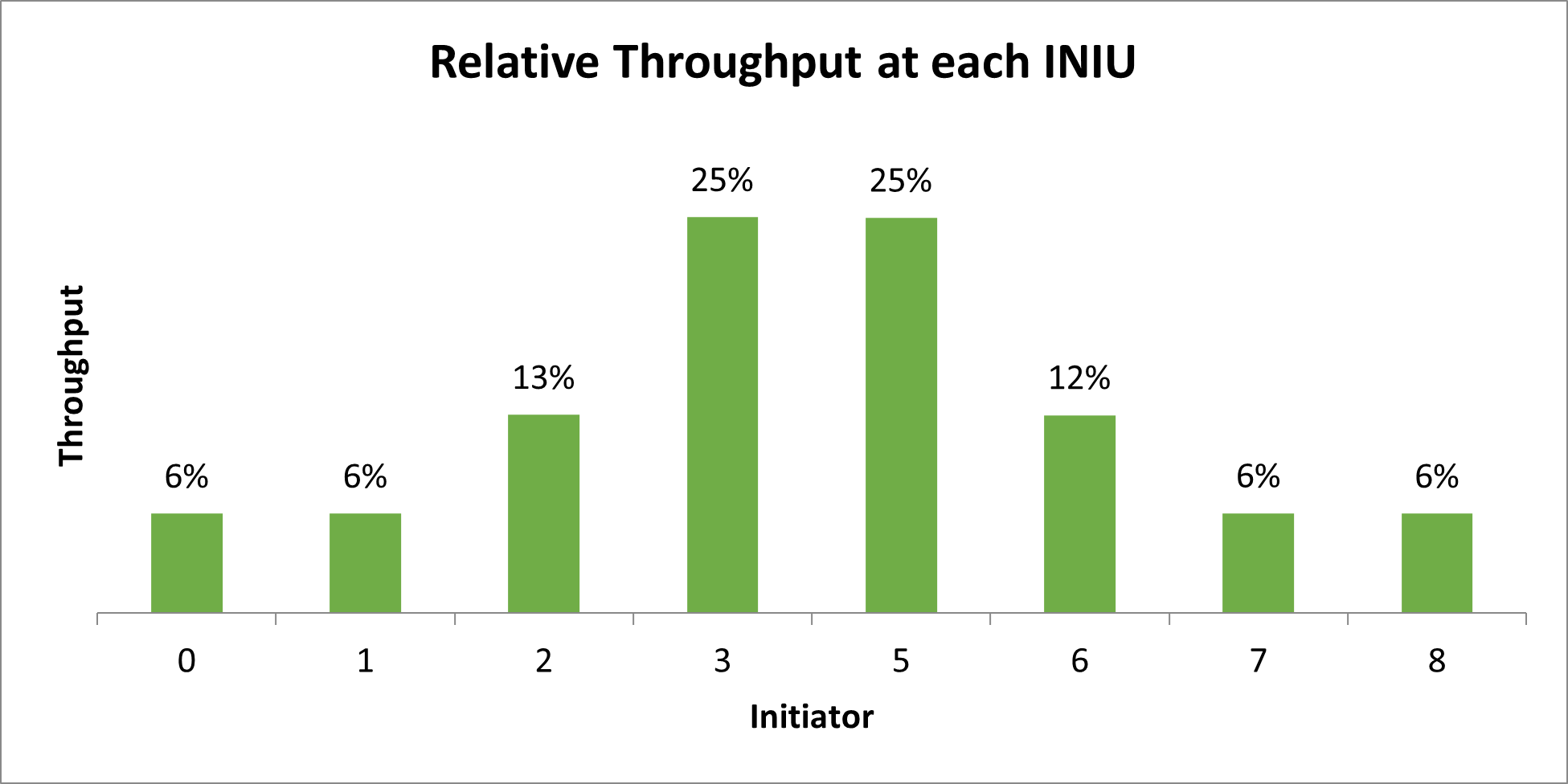
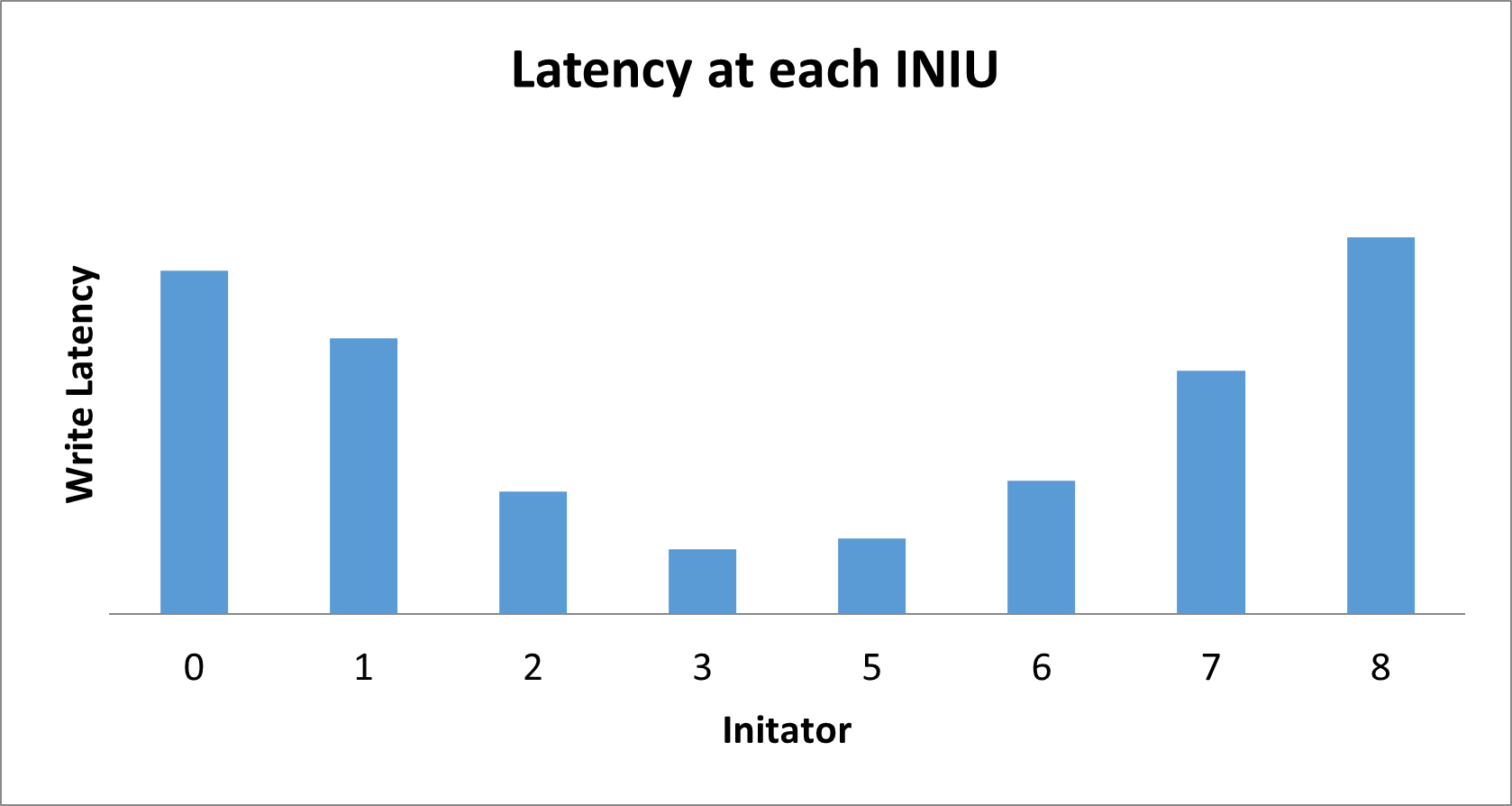
In systems where all of the initiators are issuing transactions at an unbounded rate, you can expect reduced performance for connections that span long distances and involve combining large throughput traffic at switches along the path. Latency increases for the outer initiators because of the added queuing at each switch.
Figure 32. Latency At Each Initiator (INIU)
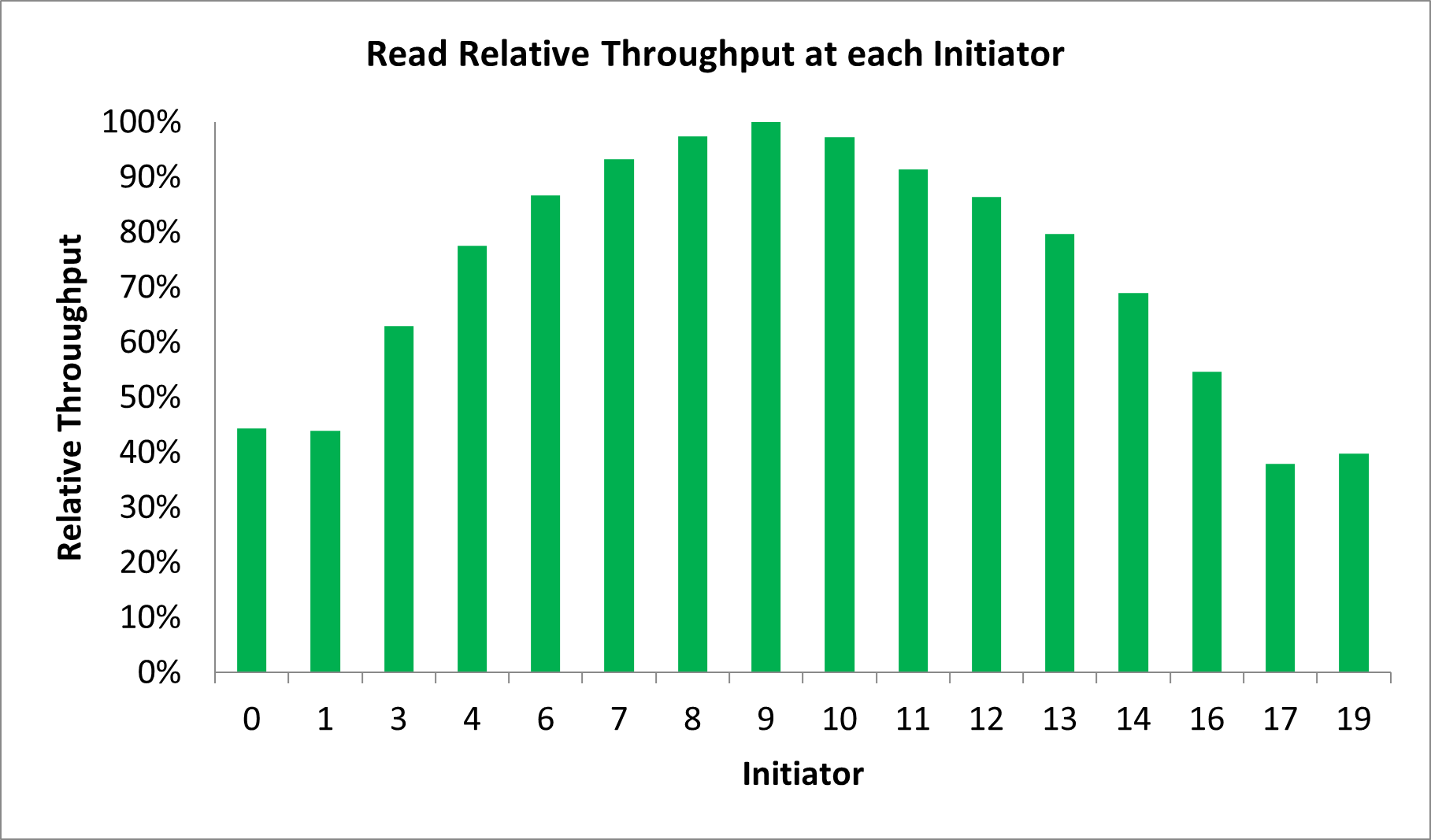
More complex interactions are possible. However, the net effect is still a reduction in bandwidth for initiators that are further away from their targets. Consider an example of a 16x16 crossbar on HBM and note the reduction in throughput for the outer initiators, despite all initiators attempting identical access to all targets.
Figure 33. Read Throughput At Each Initiator HBM 16x16 Crossbar
You can use the QoS priority features to improve performance in these scenarios. It may also be helpful to have IP that is self-limiting in issuing transactions on the NoC, or have system-wide synchronization to allow other parts on the system to get bandwidth:
- Self-limiting means that a block attached to each individual initiator monitors how much traffic is generated, and throttles the number of transactions issued in a given time window.
- System wide synchronization means that a centralized control block coordinates initiators, and one initiator cannot issue more transactions until other initiators complete their transactions. The centralized coordination guarantees fair sharing of bandwidth.