A newer version of this document is available. Customers should click here to go to the newest version.
Memory Access Analysis for Cache Misses and High Bandwidth Issues
Use the Intel® VTune™ Profiler's Memory Access analysis to identify memory-related issues, like NUMA problems and bandwidth-limited accesses, and attribute performance events to memory objects (data structures), which is provided due to instrumentation of memory allocations/de-allocations and getting static/global variables from symbol information.
Intel® VTune™ Profiler is a new renamed version of the Intel® VTune™ Amplifier.
How It Works
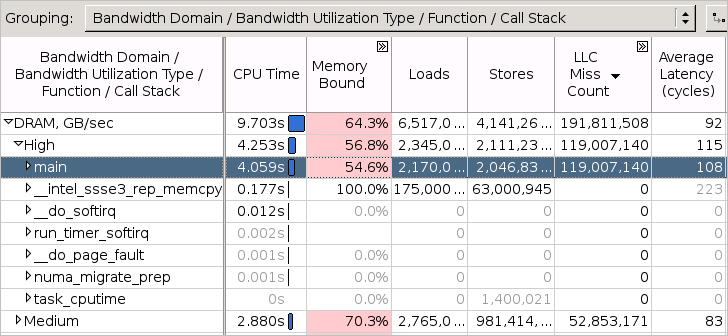
Memory Access analysis type uses hardware event-based sampling to collect data for the following metrics:
Loads and Stores metrics that show the total number of loads and stores
LLC Miss Count metric that shows the total number of last-level cache misses
Local DRAM Access Count metric that shows the total number of LLC misses serviced by the local memory
Remote DRAM Access Count metric that shows the number of accesses to the remote socket memory
Remote Cache Access Count metric that shows the number of accesses to the remote socket cache
Memory Bound metric that shows a fraction of cycles spent waiting due to demand load or store instructions
L1 Bound metric that shows how often the machine was stalled without missing the L1 data cache
L2 Bound metric that shows how often the machine was stalled on L2 cache
L3 Bound metric that shows how often the CPU was stalled on L3 cache, or contended with a sibling core
L3 Latency metric that shows a fraction of cycles with demand load accesses that hit the L3 cache under unloaded scenarios (possibly L3 latency limited)
NUMA: % of Remote Accesses metric shows percentage of memory requests to remote DRAM. The lower its value is, the better.
DRAM Bound metric that shows how often the CPU was stalled on the main memory (DRAM). This metric enables you to identify DRAM Bandwidth Bound, UPI Utilization Bound issues, as well as Memory Latency issues with the following metrics:
Remote / Local DRAM Ratio metric that is defined by the ratio of remote DRAM loads to local DRAM loads
Local DRAM metric that shows how often the CPU was stalled on loads from the local memory
Remote DRAM metric that shows how often the CPU was stalled on loads from the remote memory
Remote Cache metric that shows how often the CPU was stalled on loads from the remote cache in other sockets
Average Latency metric that shows an average load latency in cycles
The list of metrics may vary depending on your microarchitecture.
The UPI Utilization metric replaced QPI Utilization starting with systems based on Intel microarchitecture code name Skylake.
Many of the collected events used in the Memory Access analysis are precise. This simplifies understanding the data access pattern. Off-core traffic is divided into the local DRAM and remote DRAM accesses. Typically, you should focus on minimizing remote DRAM accesses that usually have a high cost.
Configure and Run Analysis
To configure options for the Memory Access analysis:
Prerequisites: Create a project.
Click the
 (standalone GUI)/
(standalone GUI)/ (Visual Studio IDE) Configure Analysis button on the Intel® VTune™ Profiler toolbar.
(Visual Studio IDE) Configure Analysis button on the Intel® VTune™ Profiler toolbar. The Configure Analysis window opens.
From HOW pane, click the
 Browse button and select Memory Access.
Browse button and select Memory Access. Configure the following options:
CPU sampling interval, ms field
Specify an interval (in milliseconds) between CPU samples.
Possible values - 0.01-1000.
The default value is 1 ms.
Analyze dynamic memory objects check box (Linux only)
Enable the instrumentation of dynamic memory allocation/de-allocation and map hardware events to such memory objects. This option may cause additional runtime overhead due to the instrumentation of all system memory allocation/de-allocation API.
The option is disabled by default.
Minimal dynamic memory object size to track, in bytes spin box (Linux only)
Specify a minimal size of dynamic memory allocations to analyze. This option helps reduce runtime overhead of the instrumentation.
The default value is 1024.
Evaluate max DRAM bandwidth check box
Evaluate maximum achievable local DRAM bandwidth before the collection starts. This data is used to scale bandwidth metrics on the timeline and calculate thresholds.
The option is enabled by default.
Analyze OpenMP regions check box
Instrument and analyze OpenMP regions to detect inefficiencies such as imbalance, lock contention, or overhead on performing scheduling, reduction and atomic operations.
The option is disabled by default.
Details button
Expand/collapse a section listing the default non-editable settings used for this analysis type. If you want to modify or enable additional settings for the analysis, you need to create a custom configuration by copying an existing predefined configuration. VTune Profiler creates an editable copy of this analysis type configuration.
Click the
 Start button to run the analysis.
Start button to run the analysis.
Limitations:
Memory objects analysis can be configured for only Linux* targets only and also only for processors based on Intel microarchitectures code named Haswell or newer architectures.
View Data
For analysis, explore the Memory Usage viewpoint that includes the following windows:
Summary window displays statistics on the overall application execution, including the application-level bandwidth utilization histogram.
Bottom-up window displays performance data per metric for each hotspot object. If you enable the Analyze memory objects option for data collection, the Bottom-up window also displays memory allocation call stacks in the grid and Call Stack pane. Use the Memory Object grouping level, preceded with the Function level, to view memory objects as the source location of an allocation call.
Platform window provides details on tasks specified in your code with the Task API, Ftrace*/Systrace* event tasks, OpenCL™ API tasks, and so on. If corresponding platform metrics are collected, the Platform window displays over-time data as GPU usage on a software queue, CPU time usage, OpenCL™ kernels data, and GPU performance per the Overview group of GPU hardware metrics, Memory Bandwidth, and CPU Frequency.
Support Limitations
Memory Access analysis is supported on the following platforms:
2nd Generation Intel® Core™ processors
Intel® Xeon® processor families, or later
3rd Generation Intel Atom® processor family, or later
If you need to analyze older processors, you can create a custom analysis and choose events related to memory accesses. However, you will be limited to memory-related events available on those processors. For information about memory access events per processor, see the VTune Profiler tuning guides.
For dynamic memory object analysis on Linux, the VTune Profiler instruments the following Memory Allocation APIs:
standard system memory allocation API: mmap, malloc/free, calloc, and others
memkind - https://github.com/memkind/memkind
jemalloc - https://github.com/memkind/jemalloc
pmdk - https://github.com/pmem/pmdk