Visible to Intel only — GUID: GUID-E2030AFA-86BF-4AAC-994C-843A6A45122B
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_hist_batch.cpp
df_cls_hist_batch_random.cpp
df_cls_traverse_model.cpp
df_reg_hist_batch.cpp
df_reg_hist_batch_random.cpp
df_reg_traverse_model.cpp
heterogen_table.cpp
homogen_table.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_reg_brute_force_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logistic_regression_dense_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_cor_dense_batch.cpp
pca_precomputed_cov_dense_batch.cpp
pca_svd_dense_batch.cpp
rbf_kernel_dense_batch.cpp
svm_two_class_thunder_dense_batch.cpp
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
connected_components_batch.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_dense_batch.cpp
df_reg_dense_batch.cpp
directed_graph.cpp
graph_service_functions.cpp
heterogen_table.cpp
homogen_table.cpp
jaccard_batch.cpp
jaccard_batch_app.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_cls_kd_tree_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logloss_dense_batch.cpp
louvain_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_dense_batch.cpp
pca_svd_dense_batch.cpp
pca_svd_dense_online.cpp
polynomial_kernel_dense_batch.cpp
rbf_kernel_dense_batch.cpp
shortest_paths_batch.cpp
sigmoid_kernel_dense_batch.cpp
subgraph_isomorphism_batch.cpp
svm_multi_class_thunder_csr_batch.cpp
svm_multi_class_thunder_dense_batch.cpp
svm_nu_cls_thunder_csr_batch.cpp
svm_nu_cls_thunder_dense_batch.cpp
svm_nu_reg_thunder_csr_batch.cpp
svm_nu_reg_thunder_dense_batch.cpp
svm_reg_thunder_csr_batch.cpp
svm_reg_thunder_dense_batch.cpp
svm_two_class_smo_csr_batch.cpp
svm_two_class_smo_dense_batch.cpp
svm_two_class_thunder_csr_batch.cpp
svm_two_class_thunder_dense_batch.cpp
triangle_counting_batch.cpp
K-Means Clustering
Density-Based Spatial Clustering of Applications with Noise
Correlation and Variance-Covariance Matrices
Principal Component Analysis
Principal Components Analysis Transform
Singular Value Decomposition
Association Rules
Kernel Functions
Expectation-Maximization
Cholesky Decomposition
QR Decomposition
Outlier Detection
Distance Matrix
Distributions
Engines
Moments of Low Order
Quantile
Quality Metrics
Sorting
Normalization
Optimization Solvers
Decision Forest
Decision Trees
Gradient Boosted Trees
Stump
Linear and Ridge Regressions
LASSO and Elastic Net Regressions
k-Nearest Neighbors (kNN) Classifier
Implicit Alternating Least Squares
Logistic Regression
Naïve Bayes Classifier
Support Vector Machine Classifier
Multi-class Classifier
Boosting
Visible to Intel only — GUID: GUID-E2030AFA-86BF-4AAC-994C-843A6A45122B
Support Vector Machine Classifier and Regression (SVM)
Support Vector Machine (SVM) classification and regression are among popular algorithms. It belongs to a family of generalized linear classification problems.
Operation |
Computational methods |
Programming Interface |
|||
Mathematical formulation
Training
Given n feature vectors  of size p, their non-negative observation weights
of size p, their non-negative observation weights  , and n responses
, and n responses  ,
,
Classification
 , where M is the number of classes
, where M is the number of classes
Regression

Nu-classification
- , where M is the number of classes
Nu-regression
the problem is to build a Support Vector Machine (SVM) classification, regression, nu-classification, or nu-regression model.
The SVM model is trained using the Sequential minimal optimization (SMO) method [Boser92] for reduced to the solution of the quadratic optimization problem
Classification

with  ,
,  ,
,  , where e is the vector of ones, C is the upper bound of the coordinates of the vector
, where e is the vector of ones, C is the upper bound of the coordinates of the vector  , Q is a symmetric matrix of size
, Q is a symmetric matrix of size  with
with  , and
, and  is a kernel function.
is a kernel function.
Regression

with ,  ,
,  , where C is the upper bound of the coordinates of the vector , Q is a symmetric matrix of size
, where C is the upper bound of the coordinates of the vector , Q is a symmetric matrix of size  with , and is a kernel function. Vectors s and z for the regression problem are formulated according to the following rule:
with , and is a kernel function. Vectors s and z for the regression problem are formulated according to the following rule:

Where  is the error tolerance parameter.
is the error tolerance parameter.
Nu-classification

with  , ,
, ,  ,
,  , where e is the vector of ones,
, where e is the vector of ones,  is an upper bound on the fraction of training errors and a lower bound of the fraction of the support vector, Q is a symmetric matrix of size with , and is a kernel function.
is an upper bound on the fraction of training errors and a lower bound of the fraction of the support vector, Q is a symmetric matrix of size with , and is a kernel function.
Nu-regression
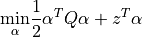
with  , ,
, ,  ,
,  , where C is the upper bound of the coordinates of the vector , is an upper bound on the fraction of training errors and a lower bound of the fraction of the support vector, Q is a symmetric matrix of size with , and is a kernel function. Vector z for the regression problem are formulated according to the following rule:
, where C is the upper bound of the coordinates of the vector , is an upper bound on the fraction of training errors and a lower bound of the fraction of the support vector, Q is a symmetric matrix of size with , and is a kernel function. Vector z for the regression problem are formulated according to the following rule:

Working subset of α updated on each iteration of the algorithm is based on the Working Set Selection (WSS) 3 scheme [Fan05]. The scheme can be optimized using one of these techniques or both:
Cache: the implementation can allocate a predefined amount of memory to store intermediate results of the kernel computation.
Shrinking: the implementation can try to decrease the amount of kernel related computations (see [Joachims99]).
The solution of the problem defines the separating hyperplane and corresponding decision function  , where only those
, where only those  that correspond to non-zero
that correspond to non-zero  appear in the sum, and b is a bias. Each non-zero is called a dual coefficient and the corresponding is called a support vector.
appear in the sum, and b is a bias. Each non-zero is called a dual coefficient and the corresponding is called a support vector.
Training method: smo
In smo training method, all vectors from the training dataset are used for each iteration.
Training method: thunder
In thunder training method, the algorithm iteratively solves the convex optimization problem with the linear constraints by selecting the fixed set of active constrains (working set) and applying Sequential Minimal Optimization (SMO) solver to the selected subproblem. The description of this method is given in Algorithm [Wen2018].
Inference methods: smo and thunder
smo and thunder inference methods perform prediction in the same way:
Given the SVM classification or regression model and r feature vectors  , the problem is to calculate the signed value of the decision function
, the problem is to calculate the signed value of the decision function  ,
,  . The sign of the value defines the class of the feature vector, and the absolute value of the function is a multiple of the distance between the feature vector and the separating hyperplane.
. The sign of the value defines the class of the feature vector, and the absolute value of the function is a multiple of the distance between the feature vector and the separating hyperplane.
Programming Interface
Refer to API Reference: Support Vector Machine Classifier and Regression.
Examples
oneAPI DPC++
Batch Processing:
oneAPI C++
Batch Processing: