Visible to Intel only — GUID: GUID-D7C36DB5-FDA7-4122-A4ED-DF6712AEFD95
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_hist_batch.cpp
df_cls_hist_batch_random.cpp
df_cls_traverse_model.cpp
df_reg_hist_batch.cpp
df_reg_hist_batch_random.cpp
df_reg_traverse_model.cpp
heterogen_table.cpp
homogen_table.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_reg_brute_force_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logistic_regression_dense_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_cor_dense_batch.cpp
pca_precomputed_cov_dense_batch.cpp
pca_svd_dense_batch.cpp
rbf_kernel_dense_batch.cpp
svm_two_class_thunder_dense_batch.cpp
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
connected_components_batch.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_dense_batch.cpp
df_reg_dense_batch.cpp
directed_graph.cpp
graph_service_functions.cpp
heterogen_table.cpp
homogen_table.cpp
jaccard_batch.cpp
jaccard_batch_app.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_cls_kd_tree_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logloss_dense_batch.cpp
louvain_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_dense_batch.cpp
pca_svd_dense_batch.cpp
pca_svd_dense_online.cpp
polynomial_kernel_dense_batch.cpp
rbf_kernel_dense_batch.cpp
shortest_paths_batch.cpp
sigmoid_kernel_dense_batch.cpp
subgraph_isomorphism_batch.cpp
svm_multi_class_thunder_csr_batch.cpp
svm_multi_class_thunder_dense_batch.cpp
svm_nu_cls_thunder_csr_batch.cpp
svm_nu_cls_thunder_dense_batch.cpp
svm_nu_reg_thunder_csr_batch.cpp
svm_nu_reg_thunder_dense_batch.cpp
svm_reg_thunder_csr_batch.cpp
svm_reg_thunder_dense_batch.cpp
svm_two_class_smo_csr_batch.cpp
svm_two_class_smo_dense_batch.cpp
svm_two_class_thunder_csr_batch.cpp
svm_two_class_thunder_dense_batch.cpp
triangle_counting_batch.cpp
K-Means Clustering
Density-Based Spatial Clustering of Applications with Noise
Correlation and Variance-Covariance Matrices
Principal Component Analysis
Principal Components Analysis Transform
Singular Value Decomposition
Association Rules
Kernel Functions
Expectation-Maximization
Cholesky Decomposition
QR Decomposition
Outlier Detection
Distance Matrix
Distributions
Engines
Moments of Low Order
Quantile
Quality Metrics
Sorting
Normalization
Optimization Solvers
Decision Forest
Decision Trees
Gradient Boosted Trees
Stump
Linear and Ridge Regressions
LASSO and Elastic Net Regressions
k-Nearest Neighbors (kNN) Classifier
Implicit Alternating Least Squares
Logistic Regression
Naïve Bayes Classifier
Support Vector Machine Classifier
Multi-class Classifier
Boosting
Visible to Intel only — GUID: GUID-D7C36DB5-FDA7-4122-A4ED-DF6712AEFD95
Decision Forest
Details
Given n feature vectors  of np-dimensional feature vectors and n responses
of np-dimensional feature vectors and n responses  , the problem is to build a decision forest classification or regression model.
, the problem is to build a decision forest classification or regression model.
Training Stage
Library uses the following algorithmic framework for the training stage. Let  be the set of observations. Given a positive integer parameters, such as the number of trees B, the bootstrap parameter
be the set of observations. Given a positive integer parameters, such as the number of trees B, the bootstrap parameter  , where f is a fraction of observations used for a training of one tree, and the number of features per node m, the algorithm does the following for
, where f is a fraction of observations used for a training of one tree, and the number of features per node m, the algorithm does the following for 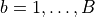 :
:
Selects randomly with replacement the set
 of N vectors from the set S. The set is called a bootstrap set.
of N vectors from the set S. The set is called a bootstrap set.Trains a decision tree classifier
 on using parameter m for each tree.
on using parameter m for each tree.
Decision tree T is trained using the training set D of size N. Each node t in the tree corresponds to the subset  of the training set D, with the root node being D itself. Its internal nodes t represent a binary test (split) dividing their subset
of the training set D, with the root node being D itself. Its internal nodes t represent a binary test (split) dividing their subset  in two subsets
in two subsets  and
and  , corresponding to their children
, corresponding to their children  and
and  .
.
Inexact Histogram Computation Method
In inexact histogram method only a selected subset of splits is considered for computation of a best split. This subset is computed for each feature at the initialization stage of the algorithm. After the set of splits is computed, each value from initially provided data is substituted with the value of the corresponding bin. The bins are continuous intervals between the selected splits.
Split Criteria
The metric for measuring the best split is called impurity, i(t). It generally reflects the homogeneity of responses within the subset in the node t. For the detailed definition of i(t) metrics, see the description of a specific algorithm.
Let the impurity decrease in the node t be

Termination Criteria
The library supports the following termination criteria of decision forest training:
- Minimal number of observations in a leaf node
-
Node t is not processed if
 is smaller than the predefined value. Splits that produce nodes with the number of observations smaller than that value are not allowed.
is smaller than the predefined value. Splits that produce nodes with the number of observations smaller than that value are not allowed. - Minimal number of observations in a split node
-
Node t is not processed if
is smaller than the predefined value. Splits that produce nodes with the number of observations smaller than that value are not allowed. - Minimum weighted fraction of the sum total of weights of all the input observations required to be at a leaf node
-
Node t is not processed if
is smaller than the predefined value. Splits that produce nodes with the number of observations smaller than that value are not allowed. - Maximal tree depth
-
Node t is not processed if its depth in the tree reached the predefined value.
- Impurity threshold
-
Node t is not processed if its impurity is smaller than the predefined threshold.
- Maximal number of leaf nodes
-
Grow trees with positive maximal number of leaf nodes in a best-first fashion. Best nodes are defined by relative reduction in impurity. If maximal number of leaf nodes equals zero, then this criterion does not limit the number of leaf nodes, and trees grow in a depth-first fashion.
Tree Building Strategies
Maximal number of leaf nodes defines the strategy of tree building: depth-first or best-first.
Depth-first Strategy
If maximal number of leaf nodes equals zero, a decision tree is built using depth-first strategy. In each terminal node t, the following recursive procedure is applied:
Stop if the termination criteria are met.
Choose randomly without replacement m feature indices
 .
.For each
 , find the best split
, find the best split  that partitions subset and maximizes impurity decrease
that partitions subset and maximizes impurity decrease  .
.A node is a split if this split induces a decrease of the impurity greater than or equal to the predefined value. Get the best split
 that maximizes impurity decrease
that maximizes impurity decrease  in all splits.
in all splits.Apply this procedure recursively to
and .
Best-first Strategy
If maximal number of leaf nodes is positive, a decision tree is built using best-first strategy. In each terminal node t, the following steps are applied:
Stop if the termination criteria are met.
Choose randomly without replacement m feature indices
.For each
, find the best split that partitions subset and maximizes impurity decrease .A node is a split if this split induces a decrease of the impurity greater than or equal to the predefined value and the number of split nodes is less or equal to
 . Get the best split that maximizes impurity decrease in all splits.
. Get the best split that maximizes impurity decrease in all splits.Put a node into a sorted array, where sort criterion is the improvement in impurity
 . The node with maximal improvement is the first in the array. For a leaf node, the improvement in impurity is zero.
. The node with maximal improvement is the first in the array. For a leaf node, the improvement in impurity is zero.Apply this procedure to
and and grow a tree one by one getting the first element from the array until the array is empty.
Random Numbers Generation
To create a bootstrap set and choose feature indices in the performant way, the training algorithm requires the source of random numbers, capable to produce sequences of random numbers in parallel.
Initialization of the engine in the decision forest is based on the scheme below:
The state of the engine is updated once the training of the decision forest model is completed. The library provides support to retrieve the instance of the engine with updated state that can be used in other computations. The update of the state is engine-specific and depends on the parallelization technique used as defined earlier:
Family: the updated state is the set of states that represent individual engines in the family.
Leapfrog: the updated state is the state of the sequence with the rightmost position on the sequence. The example below demonstrates the idea for case of 2 subsequences (‘x’ and ‘o’) of the random number sequence:
SkipAhead: the updated state is the state of the independent sequence with the rightmost position on the sequence. The example below demonstrates the idea for case of 2 subsequences (‘x’ and ‘o’) of the random number sequence:
Prediction Stage
Given decision forest classifier and vectors  , the problem is to calculate the responses for those vectors. To solve the problem for each given query vector
, the problem is to calculate the responses for those vectors. To solve the problem for each given query vector  , the algorithm finds the leaf node in a tree in the forest that gives the response by that tree. The response of the forest is based on an aggregation of responses from all trees in the forest. For the detailed definition, see the description of a specific algorithm.
, the algorithm finds the leaf node in a tree in the forest that gives the response by that tree. The response of the forest is based on an aggregation of responses from all trees in the forest. For the detailed definition, see the description of a specific algorithm.
Additional Characteristics Calculated by the Decision Forest
Decision forests can produce additional characteristics, such as an estimate of generalization error and an importance measure (relative decisive power) of each of p features (variables).
Out-of-bag Error
The estimate of the generalization error based on the training data can be obtained and calculated as follows:
For each tree
in the forest, trained on the bootstrap set , the set 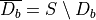 is called the out-of-bag (OOB) set.
is called the out-of-bag (OOB) set.Predict the data from
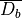 set by .
set by .For each vector
in the dataset X, predict its response  by the trees that contain in their OOB set.
by the trees that contain in their OOB set.Aggregate the out-of-bag predictions in all trees and calculate the OOB error of the decision forest.
If OOB error value per each observation is required, then calculate the prediction error for
.
For the detailed definition, see the description of a specific algorithm.
Variable Importance
There are two main types of variable importance measures:
Mean Decrease Impurity importance (MDI).
Importance of the j-th variable for predicting Y is the sum of weighted impurity decreases
 for all nodes t that use
for all nodes t that use  , averaged over all B trees in the forest:
, averaged over all B trees in the forest:

where
 is the fraction of observations reaching node t in the tree , and
is the fraction of observations reaching node t in the tree , and  is the index of the variable used in split .
is the index of the variable used in split .Mean Decrease Accuracy (MDA).
Importance of the j-th variable for predicting Y is the average increase in the OOB error over all trees in the forest when the values of the j-th variable are randomly permuted in the OOB set. For that reason, this latter measure is also known as permutation importance.
In more details, the library calculates MDA importance as follows:
Let
 be the set of feature vectors where the j-th variable is randomly permuted over all vectors in the set.
be the set of feature vectors where the j-th variable is randomly permuted over all vectors in the set.Let
 be the OOB error calculated for
be the OOB error calculated for  on its out-of-bag dataset
on its out-of-bag dataset  .
.Let
 be the OOB error calculated for using
be the OOB error calculated for using  , and its out-of-bag dataset is permuted on the j-th variable. Then
, and its out-of-bag dataset is permuted on the j-th variable. Then is the OOB error increase for the tree .
is the OOB error increase for the tree . is MDA importance.
is MDA importance. , where
, where  is the variance of
is the variance of 
Batch Processing
Decision forest classification and regression follows the general workflow described in Classification Usage Model.
Training
At the training stage, decision forest regression has the following parameters:
Parameter |
Default Value |
Description |
|---|---|---|
algorithmFPType |
float |
The floating-point type that the algorithm uses for intermediate computations. Can be float or double. |
binningStrategy |
quantiles |
Used only with method="hist" and CPU only. Selects the algorithm used to calculate bin edges. quantiles results in bins with a similar amount of training data points. averages divides the range of values observed in the training data set into equal-width bins of size (max - min) / maxBins. |
bootstrap |
true |
If true, the training set for a tree is a bootstrap of the whole training set. If false, the whole training set is used to build trees. |
engine |
SharePtr<engines::mt2203::Batch>()> |
Pointer to the random number generator engine. The random numbers produced by this engine are used to choose the bootstrap set, split features in every split node in a tree, and generate permutation required in computations of MDA variable importance. |
featuresPerNode |
0 |
The number of features tried as possible splits per node. If the parameter is set to 0, the library uses the square root of the number of features, |
impurityThreshold |
0 |
The threshold value used as stopping criteria: if the impurity value in the node is smaller than the threshold, the node is not split anymore. |
maxBins |
256 |
Used only with method="hist". Maximal number of discrete bins to bucket continuous features. Increasing the number results in higher computation costs. Selecting 0 disables creating buckets. |
maxLeafNodes |
0 |
Grow trees with positive maximal number of leaf nodes in a best-first fashion. Best nodes are defined as relative reduction in impurity. If maximal number of leaf nodes equals zero, then this parameter does not limit the number of leaf nodes, and trees grow in a depth-first fashion. |
maxTreeDepth |
0 |
Maximal tree depth. Default is 0 (unlimited). |
method |
defaultDense |
The computation method used by the decision forest classification. For CPU:
For GPU: |
minBinSize |
5 |
Used only with method="hist". Minimal number of observations in a bin. |
minImpurityDecreaseInSplitNode |
0.0 |
Minimum amount of impurity decrease required to split a node; it can be any non-negative number. |
minObservationsInLeafNode |
1 for classification, 5 for regression |
Minimum number of observations in the leaf node. |
minObservationsInSplitNode |
2 |
Minimum number of samples required to split an internal node; it can be any non-negative number. |
minWeightFractionInLeafNode |
0.0 |
Minimum weighted fraction of the sum total of weights of all the input observations required to be at a leaf node, from 0.0 to 0.5. All observations have equal weights if the weights of the observations are not provided. |
nTrees |
100 |
The number of trees in the forest. |
observationsPerTreeFraction |
1 |
Fraction of the training set S used to form the bootstrap set for a single tree training, |
resultsToCompute |
0 |
The 64-bit integer flag that specifies which extra characteristics of the decision forest to compute. Provide one of the following values to request a single characteristic or use bitwise OR to request a combination of the characteristics:
|
DEPRECATED:seed |
777 |
The seed for random number generator, which is used to choose the bootstrap set, split features in every split node in a tree, and generate permutation required in computations of MDA variable importance.
NOTE:
This parameter is deprecated and will be removed in future releases. Use engine instead.
|
varImportance |
none |
The variable importance computation mode. Possible values:
|
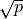 , for classification and
, for classification and 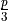 features for regression.
features for regression. . The observations are sampled randomly with replacement.
. The observations are sampled randomly with replacement.Output
In addition to regression or classifier output, decision forest calculates the result described below. Pass the Result ID as a parameter to the methods that access the result of your algorithm.
Result ID |
Result |
|---|---|
outOfBagError |
A numeric table
NOTE:
By default, this result is an object of the HomogenNumericTable class, but you can define the result as an object of any class derived from NumericTable.
|
variableImportance |
A numeric table
NOTE:
By default, this result is an object of the HomogenNumericTable class, but you can define the result as an object of any class derived from NumericTable except PackedTriangularMatrix and PackedSymmetricMatrix.
|
outOfBagErrorPerObservation |
A numeric table of size
NOTE:
By default, this result is an object of the HomogenNumericTable class, but you can define the result as an object of any class derived from NumericTable.
|
updatedEngine |
Engine instance with state updated after computations. |
 containing out-of-bag error computed when the computeOutOfBagErroroption option is on.
containing out-of-bag error computed when the computeOutOfBagErroroption option is on. that contains variable importance values for each feature. If you set the varImportance parameter to none, the library returns a null pointer to the table.
that contains variable importance values for each feature. If you set the varImportance parameter to none, the library returns a null pointer to the table. that contains the computed out-of-bag error when the computeOutOfBagErrorPerObservation option is enabled. The value -1 in the table indicates that no OOB value was computed because this observation was not in OOB set for any of the trees in the model (never left out during the bootstrap).
that contains the computed out-of-bag error when the computeOutOfBagErrorPerObservation option is enabled. The value -1 in the table indicates that no OOB value was computed because this observation was not in OOB set for any of the trees in the model (never left out during the bootstrap).Performance Considerations
To get the best performance of the decision forest variable importance computation, use the Mean Decrease Impurity (MDI) rather than the Mean Decrease Accuracy (MDA) method.
Product and Performance Information |
|---|
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Notice revision #20201201 |