Visible to Intel only — GUID: GUID-E0AD5B48-4535-4784-B2C9-234134BA3F97
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_hist_batch.cpp
df_cls_hist_batch_random.cpp
df_cls_traverse_model.cpp
df_reg_hist_batch.cpp
df_reg_hist_batch_random.cpp
df_reg_traverse_model.cpp
heterogen_table.cpp
homogen_table.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_reg_brute_force_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logistic_regression_dense_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_cor_dense_batch.cpp
pca_precomputed_cov_dense_batch.cpp
pca_svd_dense_batch.cpp
rbf_kernel_dense_batch.cpp
svm_two_class_thunder_dense_batch.cpp
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
connected_components_batch.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_dense_batch.cpp
df_reg_dense_batch.cpp
directed_graph.cpp
graph_service_functions.cpp
heterogen_table.cpp
homogen_table.cpp
jaccard_batch.cpp
jaccard_batch_app.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_cls_kd_tree_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logloss_dense_batch.cpp
louvain_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_dense_batch.cpp
pca_svd_dense_batch.cpp
pca_svd_dense_online.cpp
polynomial_kernel_dense_batch.cpp
rbf_kernel_dense_batch.cpp
shortest_paths_batch.cpp
sigmoid_kernel_dense_batch.cpp
subgraph_isomorphism_batch.cpp
svm_multi_class_thunder_csr_batch.cpp
svm_multi_class_thunder_dense_batch.cpp
svm_nu_cls_thunder_csr_batch.cpp
svm_nu_cls_thunder_dense_batch.cpp
svm_nu_reg_thunder_csr_batch.cpp
svm_nu_reg_thunder_dense_batch.cpp
svm_reg_thunder_csr_batch.cpp
svm_reg_thunder_dense_batch.cpp
svm_two_class_smo_csr_batch.cpp
svm_two_class_smo_dense_batch.cpp
svm_two_class_thunder_csr_batch.cpp
svm_two_class_thunder_dense_batch.cpp
triangle_counting_batch.cpp
K-Means Clustering
Details
Initialization
Computation
Examples
Performance Considerations
Density-Based Spatial Clustering of Applications with Noise
Correlation and Variance-Covariance Matrices
Principal Component Analysis
Principal Components Analysis Transform
Singular Value Decomposition
Association Rules
Kernel Functions
Expectation-Maximization
Cholesky Decomposition
QR Decomposition
Outlier Detection
Distance Matrix
Distributions
Engines
Moments of Low Order
Quantile
Quality Metrics
Sorting
Normalization
Optimization Solvers
Decision Forest
Decision Trees
Gradient Boosted Trees
Stump
Linear and Ridge Regressions
LASSO and Elastic Net Regressions
k-Nearest Neighbors (kNN) Classifier
Implicit Alternating Least Squares
Logistic Regression
Naïve Bayes Classifier
Support Vector Machine Classifier
Multi-class Classifier
Boosting
Visible to Intel only — GUID: GUID-E0AD5B48-4535-4784-B2C9-234134BA3F97
K-Means Clustering
NOTE:
K-Means and K-Means initialization are also available with oneAPI interfaces:
K-Means is among the most popular and simplest clustering methods. It is intended to partition a data set into a small number of clusters such that feature vectors within a cluster have greater similarity with one another than with feature vectors from other clusters. Each cluster is characterized by a representative point, called a centroid, and a cluster radius.
In other words, the clustering methods enable reducing the problem of analysis of the entire data set to the analysis of clusters.
There are numerous ways to define the measure of similarity and centroids. For K-Means, the centroid is defined as the mean of feature vectors within the cluster.
Details
Given the set 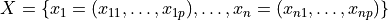 of np-dimensional feature vectors and a positive integer k, the problem is to find a set
of np-dimensional feature vectors and a positive integer k, the problem is to find a set 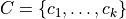 of kp-dimensional vectors that minimize the objective function (overall error)
of kp-dimensional vectors that minimize the objective function (overall error)
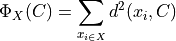
where 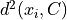 is the distance from
is the distance from  to the closest center in C, such as the Euclidean distance. The vectors
to the closest center in C, such as the Euclidean distance. The vectors 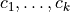 are called centroids. To start computations, the algorithm requires initial values of centroids.
are called centroids. To start computations, the algorithm requires initial values of centroids.
Centroid Initialization
Centroids initialization can be done using these methods:
Choice of first k feature vectors from the data set X.
Random choice of k feature vectors from the data set using the following simple random sampling draw-by-draw algorithm. The algorithm does the following:
Chooses one of the feature vectors
from X with equal probability.Excludes
from X and adds it to the current set of centers.Resumes from step 1 until the set of centers reaches the desired size k.
K-Means++ algorithm [Arthur2007], which selects centers with the probability proportional to their contribution to the overall error
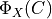 according to the following scheme:
according to the following scheme:Chooses one of the feature vectors
from X with equal probability.Excludes
from X and adds it to the current set of centers C.For each feature vector
in X calculates its minimal distance 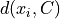 from the current set of centers C.
from the current set of centers C.Chooses one of the feature vectors
from X with the probability 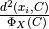 .
.Resumes from step 2 until the set of centers C reaches the desired size k.
Parallel K-Means++ algorithm [Bahmani2012] that does the following:
Chooses one of the feature vectors
from X with equal probability.Excludes
from X and adds it to the current set of centers C.Repeats nRounds times:
For each feature vector
from X calculates its minimal distance from the current set of centers C.Chooses
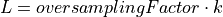 feature vectors from X with the probability .
feature vectors from X with the probability .Excludes
vectors chosen in the previous step from X and adds them to the current set of centers C.
For
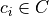 sets
sets  to the ratings, the number of points in X closer to
to the ratings, the number of points in X closer to 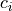 than to any other point in C.
than to any other point in C.Applies K-Means++ algorithm with weights
to the points in C, which means that the following probability is used in step:
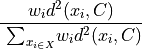
The algorithm parameters define the number of candidates L selected in each round and number of rounds:
Choose oversamplingFactor to make
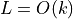 .
.Choose nRounds as
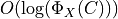 , where is the estimation of the goal function when the first center is chosen. [Bahmani2012] recommends to set nRounds to a constant value not greater than 8.
, where is the estimation of the goal function when the first center is chosen. [Bahmani2012] recommends to set nRounds to a constant value not greater than 8.
Computation
Computation of the goal function includes computation of the Euclidean distance between vectors 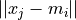 . The algorithm uses the following modification of the Euclidean distance between feature vectors a and b:
. The algorithm uses the following modification of the Euclidean distance between feature vectors a and b: 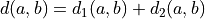 , where
, where 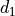 is computed for continuous features as
is computed for continuous features as
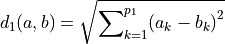
and  is computed for binary categorical features as
is computed for binary categorical features as
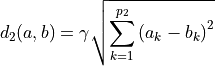
In these equations,  γ weighs the impact of binary categorical features on the clustering,
γ weighs the impact of binary categorical features on the clustering, 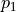 is the number of continuous features, and
is the number of continuous features, and 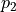 is the number of binary categorical features. Note that the algorithm does not support non-binary categorical features.
is the number of binary categorical features. Note that the algorithm does not support non-binary categorical features.
The K-Means clustering algorithm computes centroids using Lloyd’s method [Lloyd82]. For each feature vector 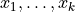 , you can also compute the index of the cluster that contains the feature vector.
, you can also compute the index of the cluster that contains the feature vector.
In some cases, if no vectors are assigned to some clusters on a particular iteration, the iteration produces an empty cluster. It may occur due to bad initialization of centroids or the dataset structure. In this case, the algorithm uses the following strategy to replace the empty cluster centers and decrease the value of the overall goal function:
Feature vectors, most distant from their assigned centroids, are selected as the new cluster centers. Information about these vectors is gathered automatically during the algorithm execution.
In the distributed processing mode, most distant vectors from the local nodes are computed (Step 1), stored in PartialResult, and collected on the master node (Step 2). For more details, see the PartialResult description at Step 1 [Tan2005].
Initialization
The K-Means clustering algorithm requires initialization of centroids as an explicit step. Initialization flow depends on the computation mode. Skip this step if you already calculated initial centroids.
For initialization, the following computation modes are available:
Computation
The following computation modes are available:
NOTE:
Distributed mode is not available for oneAPI interfaces and for Python* with DPC++ support.
Examples
oneAPI DPC++
Batch Processing:
oneAPI C++
Batch Processing:
C++ (CPU)
Batch Processing:
Distributed Processing:
Python*
Batch Processing:
Distributed Processing
Performance Considerations
To get the best overall performance of the K-Means algorithm:
If input data is homogeneous, provide the input data and store results in homogeneous numeric tables of the same type as specified in the algorithmFPType class template parameter.
If input data is non-homogeneous, use AOS layout rather than SOA layout.
For the output assignments table, use a homogeneous numeric table of the int type.
Product and Performance Information |
|---|
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Notice revision #20201201 |