Visible to Intel only — GUID: GUID-3CFDCFAD-F3F0-464A-A9A6-1818795CE506
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_hist_batch.cpp
df_cls_hist_batch_random.cpp
df_cls_traverse_model.cpp
df_reg_hist_batch.cpp
df_reg_hist_batch_random.cpp
df_reg_traverse_model.cpp
heterogen_table.cpp
homogen_table.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_reg_brute_force_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logistic_regression_dense_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_cor_dense_batch.cpp
pca_precomputed_cov_dense_batch.cpp
pca_svd_dense_batch.cpp
rbf_kernel_dense_batch.cpp
svm_two_class_thunder_dense_batch.cpp
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
connected_components_batch.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_dense_batch.cpp
df_reg_dense_batch.cpp
directed_graph.cpp
graph_service_functions.cpp
heterogen_table.cpp
homogen_table.cpp
jaccard_batch.cpp
jaccard_batch_app.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_cls_kd_tree_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logloss_dense_batch.cpp
louvain_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_dense_batch.cpp
pca_svd_dense_batch.cpp
pca_svd_dense_online.cpp
polynomial_kernel_dense_batch.cpp
rbf_kernel_dense_batch.cpp
shortest_paths_batch.cpp
sigmoid_kernel_dense_batch.cpp
subgraph_isomorphism_batch.cpp
svm_multi_class_thunder_csr_batch.cpp
svm_multi_class_thunder_dense_batch.cpp
svm_nu_cls_thunder_csr_batch.cpp
svm_nu_cls_thunder_dense_batch.cpp
svm_nu_reg_thunder_csr_batch.cpp
svm_nu_reg_thunder_dense_batch.cpp
svm_reg_thunder_csr_batch.cpp
svm_reg_thunder_dense_batch.cpp
svm_two_class_smo_csr_batch.cpp
svm_two_class_smo_dense_batch.cpp
svm_two_class_thunder_csr_batch.cpp
svm_two_class_thunder_dense_batch.cpp
triangle_counting_batch.cpp
K-Means Clustering
Density-Based Spatial Clustering of Applications with Noise
Correlation and Variance-Covariance Matrices
Principal Component Analysis
Principal Components Analysis Transform
Singular Value Decomposition
Association Rules
Kernel Functions
Expectation-Maximization
Cholesky Decomposition
QR Decomposition
Outlier Detection
Distance Matrix
Distributions
Engines
Moments of Low Order
Quantile
Quality Metrics
Sorting
Normalization
Optimization Solvers
Decision Forest
Decision Trees
Gradient Boosted Trees
Stump
Linear and Ridge Regressions
LASSO and Elastic Net Regressions
k-Nearest Neighbors (kNN) Classifier
Implicit Alternating Least Squares
Logistic Regression
Naïve Bayes Classifier
Support Vector Machine Classifier
Multi-class Classifier
Boosting
Visible to Intel only — GUID: GUID-3CFDCFAD-F3F0-464A-A9A6-1818795CE506
Principal Components Analysis (PCA)
Principal Component Analysis (PCA) is an algorithm for exploratory data analysis and dimensionality reduction. PCA transforms a set of feature vectors of possibly correlated features to a new set of uncorrelated features, called principal components. Principal components are the directions of the largest variance, that is, the directions where the data is mostly spread out.
Operation |
Computational methods |
Programming Interface |
|||
Mathematical formulation
Training
Given a training data set  with n feature vectors of dimension p, the problem is to compute r principal directions (p-dimensional eigenvectors [Lang87]) of the training date set. The eigenvectors can be grouped into the
with n feature vectors of dimension p, the problem is to compute r principal directions (p-dimensional eigenvectors [Lang87]) of the training date set. The eigenvectors can be grouped into the  matrix T that contains one eigenvector in each row.
matrix T that contains one eigenvector in each row.
The principal components can be computed with any of the following two methods:
Covariance (or Correlation)
Singular Value Decomposition (SVD)
Partial Training
Given a block of a training data set with n feature vectors of p dimension, the problem is to compute r principal directions (p-dimensional eigenvectors [Lang87]) of the training data set.
To compute the partial products, use any of the following two methods:
Covariance (or Correlation)
Singular Value Decomposition (SVD) (CPU only)
Finalize Training
Given a partial result.
To compute the partial products, use any of the following two methods:
Covariance (or Correlation)
Singular Value Decomposition (SVD) (CPU only)
Training method: Covariance
The PCA algorithm can be trained using either the covariance or the correlation matrix. The choice of covariance matrix or correlation matrix is application-dependent. More specifically, if scaling of the features is important for a problem, which is often the case, using the correlation matrix to compute principal components is more appropriate. By default, oneDAL uses the correlation matrix to compute the principal components. It is possible to use the covariance matrix by passing “precomputed” as method and feeding a covariance matrix as input to the PCA algorithm. To compute the covariance matrix, the Covariance algorithm can be used.
The eigenvector associated with the k-th largest eigenvalue of the covariance (or correlation) matrix is also the k-th principal component of the training data set. Based on this, the principal components can be computed in three steps:
Computation of the covariance (or correlation) matrix.
Computation of the eigenvectors and eigenvalues of the covariance (or correlation) matrix.
Processing (sorting and storing) the results.
Covariance matrix can be computed in the following way:
Compute the column means
 , where
, where  .
.Compute the sample covariance matrix
 , where
, where  ,
,  ,
,  .
.
Corelation matrix can be computed from covariance matrix in the following way:
Compute the correlation matrix
 , where
, where  , , .
, , .
The eigenvalues  and eigenvectors
and eigenvectors  can be computed by an arbitrary method such as [Ping14].
can be computed by an arbitrary method such as [Ping14].
In the final step, the eigenvalues () are sorted in descending order to determine the order of the principal components. Each principal component is stored as a row of the final resulting matrix,  , where
, where  is the i-th principal component of dimension p. Additionally, the means and variances of the input dataset are returned.
is the i-th principal component of dimension p. Additionally, the means and variances of the input dataset are returned.
Training method: SVD
The singular value decomposition (SVD) is a matrix factorization technique that decomposes an observation matrix of p-dimensional feature vectors into three matrices as  . Here:
. Here:
The columns of U are the left-singular vectors.
The columns of V are the right-singular vectors.
 is the conjugate transpose of the matrix V.
is the conjugate transpose of the matrix V.The diagonal entries of
 are the singular values (
are the singular values ( ) of X.
) of X.
The right-singular vectors are the principal components of X. The steps of computing principal components using the SVD technique are:
Mean centering the input data.
Decomposing the mean-centered input data to compute the singular values and the singular vectors.
Processing (sorting and storing) the results.
First step is to mean center the input data  , where
, where  ,
,  , ,
, ,  .
.
Singular values  , left-singular vectors
, left-singular vectors  , and right-singular vectors
, and right-singular vectors 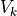 of matrix
of matrix  can be computed with an arbitrary method as described in [Demmel90].
can be computed with an arbitrary method as described in [Demmel90].
The final step is to find a permutation matrix 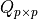 such that the diagonal entries of
such that the diagonal entries of  are sorted in descending order, i.e.
are sorted in descending order, i.e.  , for all
, for all  assuming
assuming  . The rows of the resulting matrix
. The rows of the resulting matrix  are the principal components of X. The rows of T are also the eigenvectors of the covariance matrix of X. Additionally, the means and variances of the initial dataset are returned.
are the principal components of X. The rows of T are also the eigenvectors of the covariance matrix of X. Additionally, the means and variances of the initial dataset are returned.
Sign-flip technique
The eigenvectors (or the right-singular vectors) are not uniquely defined because the negative of any eigenvector is also an eigenvector of the input matrix. The signs of the eigenvectors or the singular vectors often depend on the solver used. A sign-flip technique, such as the one proposed in [Bro07], helps remove the ambiguity. The sign-flip function modifies the matrix T the following way:

where  is i-th row,
is i-th row,  is the element in the i-th row and j-th column,
is the element in the i-th row and j-th column,  is the signum function,
is the signum function,

Inference
Given the inference data set  with m feature vectors of dimension p, and the transformation matrix T produced at the training stage, the problem is to transform
with m feature vectors of dimension p, and the transformation matrix T produced at the training stage, the problem is to transform  to the
to the  matrix
matrix  , where
, where  is an r-dimensional transformed observation.
is an r-dimensional transformed observation.
Each individual observation  can be transformed by applying the following linear transformation [Lang87] defined by the matrix T,
can be transformed by applying the following linear transformation [Lang87] defined by the matrix T,

Inference methods: Covariance and SVD
Covariance and SVD inference methods compute  according to (1).
according to (1).
Programming Interface
Online mode
The algorithm supports online mode.
Distributed mode
The algorithm supports distributed execution in SMPD mode (only on GPU).
Usage Example
Training
pca::model<> run_training(const table& data) {
const auto pca_desc = pca::descriptor<float>{}
.set_component_count(5)
.set_deterministic(true);
const auto result = train(pca_desc, data);
print_table("means", result.get_means());
print_table("variances", result.get_variances());
print_table("eigenvalues", result.get_eigenvalues());
print_table("eigenvectors", result.get_eigenvectors());
return result.get_model();
}Inference
table run_inference(const pca::model<>& model,
const table& new_data) {
const auto pca_desc = pca::descriptor<float>{}
.set_component_count(model.get_component_count());
const auto result = infer(pca_desc, model, new_data);
print_table("labels", result.get_transformed_data());
}Examples
oneAPI DPC++
Batch Processing:
Online Processing:
oneAPI C++
Batch Processing:
Online Processing: