Visible to Intel only — GUID: GUID-2073F5EE-0096-4FBF-9329-37ED5DCE9744
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_hist_batch.cpp
df_cls_hist_batch_random.cpp
df_cls_traverse_model.cpp
df_reg_hist_batch.cpp
df_reg_hist_batch_random.cpp
df_reg_traverse_model.cpp
heterogen_table.cpp
homogen_table.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_reg_brute_force_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logistic_regression_dense_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_cor_dense_batch.cpp
pca_precomputed_cov_dense_batch.cpp
pca_svd_dense_batch.cpp
rbf_kernel_dense_batch.cpp
svm_two_class_thunder_dense_batch.cpp
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
connected_components_batch.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_dense_batch.cpp
df_reg_dense_batch.cpp
directed_graph.cpp
graph_service_functions.cpp
heterogen_table.cpp
homogen_table.cpp
jaccard_batch.cpp
jaccard_batch_app.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_cls_kd_tree_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logloss_dense_batch.cpp
louvain_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_dense_batch.cpp
pca_svd_dense_batch.cpp
pca_svd_dense_online.cpp
polynomial_kernel_dense_batch.cpp
rbf_kernel_dense_batch.cpp
shortest_paths_batch.cpp
sigmoid_kernel_dense_batch.cpp
subgraph_isomorphism_batch.cpp
svm_multi_class_thunder_csr_batch.cpp
svm_multi_class_thunder_dense_batch.cpp
svm_nu_cls_thunder_csr_batch.cpp
svm_nu_cls_thunder_dense_batch.cpp
svm_nu_reg_thunder_csr_batch.cpp
svm_nu_reg_thunder_dense_batch.cpp
svm_reg_thunder_csr_batch.cpp
svm_reg_thunder_dense_batch.cpp
svm_two_class_smo_csr_batch.cpp
svm_two_class_smo_dense_batch.cpp
svm_two_class_thunder_csr_batch.cpp
svm_two_class_thunder_dense_batch.cpp
triangle_counting_batch.cpp
K-Means Clustering
Density-Based Spatial Clustering of Applications with Noise
Correlation and Variance-Covariance Matrices
Principal Component Analysis
Principal Components Analysis Transform
Singular Value Decomposition
Association Rules
Kernel Functions
Expectation-Maximization
Cholesky Decomposition
QR Decomposition
Outlier Detection
Distance Matrix
Distributions
Engines
Moments of Low Order
Quantile
Quality Metrics
Sorting
Normalization
Optimization Solvers
Decision Forest
Decision Trees
Gradient Boosted Trees
Stump
Linear and Ridge Regressions
LASSO and Elastic Net Regressions
k-Nearest Neighbors (kNN) Classifier
Implicit Alternating Least Squares
Logistic Regression
Naïve Bayes Classifier
Support Vector Machine Classifier
Multi-class Classifier
Boosting
Visible to Intel only — GUID: GUID-2073F5EE-0096-4FBF-9329-37ED5DCE9744
K-Means
The K-Means algorithm solves clustering problem by partitioning n feature vectors into k clusters minimizing some criterion. Each cluster is characterized by a representative point, called a centroid.
Operation |
Computational methods |
Programming Interface |
||
Mathematical formulation
Training
Given the training set  of p-dimensional feature vectors and a positive integer k, the problem is to find a set
of p-dimensional feature vectors and a positive integer k, the problem is to find a set  of p-dimensional centroids that minimize the objective function
of p-dimensional centroids that minimize the objective function
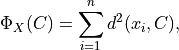
where  is the squared Euclidean distance from
is the squared Euclidean distance from  to the closest centroid in C,
to the closest centroid in C,
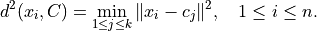
Expression  denotes
denotes  norm.
norm.
NOTE:
In the general case, d may be an arbitrary distance function. Current version of the oneDAL spec defines only Euclidean distance case.
Training method: Lloyd’s
The Lloyd’s method [Lloyd82] consists in iterative updates of centroids by applying the alternating Assignment and Update steps, where t denotes a index of the current iteration, e.g.,  is the set of centroids at the t-th iteration. The method requires the initial centroids
is the set of centroids at the t-th iteration. The method requires the initial centroids  to be specified at the beginning of the algorithm (
to be specified at the beginning of the algorithm ( ).
).
(1) Assignment step: Assign each feature vector to the nearest centroid.  denotes the assigned label (cluster index) to the feature vector .
denotes the assigned label (cluster index) to the feature vector .
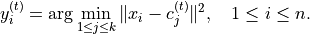
Each feature vector from the training set X is assigned to exactly one centroid so that X is partitioned to k disjoint sets (clusters)
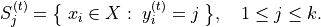
(2) Update step: Recalculate centroids by averaging feature vectors assigned to each cluster.

If any of  are empty, start the empty clusters handling procedure. In this case, you can set the value of
are empty, start the empty clusters handling procedure. In this case, you can set the value of  as the farthest point from the previously calculated centroids for each empty cluster. This procedure makes sure that the number of clusters remains the same.
as the farthest point from the previously calculated centroids for each empty cluster. This procedure makes sure that the number of clusters remains the same.
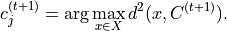
The steps (1) and (2) are performed until the following stop condition,
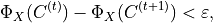
is satisfied or number of iterations exceeds the maximal value T defined by the user.
Inference
Given the inference set  of p-dimensional feature vectors and the set
of p-dimensional feature vectors and the set  of centroids produced at the training stage, the problem is to predict the index
of centroids produced at the training stage, the problem is to predict the index  ,
,  , of the centroid in accordance with a method-defined rule.
, of the centroid in accordance with a method-defined rule.
Inference method: Lloyd’s
Lloyd’s inference method computes the  as an index of the centroid closest to the feature vector
as an index of the centroid closest to the feature vector  ,
,
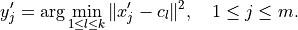
Programming Interface
Refer to API Reference: K-Means.
Distributed mode
The algorithm supports distributed execution in SPMD mode (only on GPU).
Usage Example
Training
kmeans::model<> run_training(const table& data,
const table& initial_centroids) {
const auto kmeans_desc = kmeans::descriptor<float>{}
.set_cluster_count(10)
.set_max_iteration_count(50)
.set_accuracy_threshold(1e-4);
const auto result = train(kmeans_desc, data, initial_centroids);
print_table("labels", result.get_labels());
print_table("centroids", result.get_model().get_centroids());
print_value("objective", result.get_objective_function_value());
return result.get_model();
}Inference
table run_inference(const kmeans::model<>& model,
const table& new_data) {
const auto kmeans_desc = kmeans::descriptor<float>{}
.set_cluster_count(model.get_cluster_count());
const auto result = infer(kmeans_desc, model, new_data);
print_table("labels", result.get_labels());
}Examples
oneAPI DPC++
Batch Processing:
oneAPI C++
Batch Processing: