Visible to Intel only — GUID: GUID-DAA0696C-5CD0-45AC-9E4C-AA0FF6CA20E8
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_hist_batch.cpp
df_cls_hist_batch_random.cpp
df_cls_traverse_model.cpp
df_reg_hist_batch.cpp
df_reg_hist_batch_random.cpp
df_reg_traverse_model.cpp
heterogen_table.cpp
homogen_table.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_reg_brute_force_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logistic_regression_dense_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_cor_dense_batch.cpp
pca_precomputed_cov_dense_batch.cpp
pca_svd_dense_batch.cpp
rbf_kernel_dense_batch.cpp
svm_two_class_thunder_dense_batch.cpp
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
connected_components_batch.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_dense_batch.cpp
df_reg_dense_batch.cpp
directed_graph.cpp
graph_service_functions.cpp
heterogen_table.cpp
homogen_table.cpp
jaccard_batch.cpp
jaccard_batch_app.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_cls_kd_tree_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logloss_dense_batch.cpp
louvain_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_dense_batch.cpp
pca_svd_dense_batch.cpp
pca_svd_dense_online.cpp
polynomial_kernel_dense_batch.cpp
rbf_kernel_dense_batch.cpp
shortest_paths_batch.cpp
sigmoid_kernel_dense_batch.cpp
subgraph_isomorphism_batch.cpp
svm_multi_class_thunder_csr_batch.cpp
svm_multi_class_thunder_dense_batch.cpp
svm_nu_cls_thunder_csr_batch.cpp
svm_nu_cls_thunder_dense_batch.cpp
svm_nu_reg_thunder_csr_batch.cpp
svm_nu_reg_thunder_dense_batch.cpp
svm_reg_thunder_csr_batch.cpp
svm_reg_thunder_dense_batch.cpp
svm_two_class_smo_csr_batch.cpp
svm_two_class_smo_dense_batch.cpp
svm_two_class_thunder_csr_batch.cpp
svm_two_class_thunder_dense_batch.cpp
triangle_counting_batch.cpp
K-Means Clustering
Density-Based Spatial Clustering of Applications with Noise
Correlation and Variance-Covariance Matrices
Principal Component Analysis
Principal Components Analysis Transform
Singular Value Decomposition
Association Rules
Kernel Functions
Expectation-Maximization
Cholesky Decomposition
QR Decomposition
Outlier Detection
Distance Matrix
Distributions
Engines
Moments of Low Order
Quantile
Quality Metrics
Sorting
Normalization
Optimization Solvers
Decision Forest
Decision Trees
Gradient Boosted Trees
Stump
Linear and Ridge Regressions
LASSO and Elastic Net Regressions
k-Nearest Neighbors (kNN) Classifier
Implicit Alternating Least Squares
Logistic Regression
Naïve Bayes Classifier
Support Vector Machine Classifier
Multi-class Classifier
Boosting
Visible to Intel only — GUID: GUID-DAA0696C-5CD0-45AC-9E4C-AA0FF6CA20E8
Data Management
Effective data management is among key constituents of the performance of a data analytics application. For Intel® oneAPI Data Analytics Library, effective data management requires effectively performing the following operations:
Raw data acquisition, filtering, and normalization with data source interfaces.
Data conversion to a numeric representation for numeric tables.
Data streaming from a numeric table to an algorithm.
oneDAL provides a set of customizable interfaces to operate on your out-of-memory and in-memory data in different usage scenarios, which include batch processing, online processing, and distributed processing, as well as more complex scenarios, such as a combination of online and distributed processing.
One key concept of Data Management in oneDAL is a data set. A data set is a collection of data of a defined structure that characterizes an analyzed and modeled object. Specifically, the object is characterized by a set of attributes (Features), which form a Feature Vector of dimension p. Multiple feature vectors form a set of Observations of size n. oneDAL defines a tabular view of a data set where table rows represent observations and columns represent features.
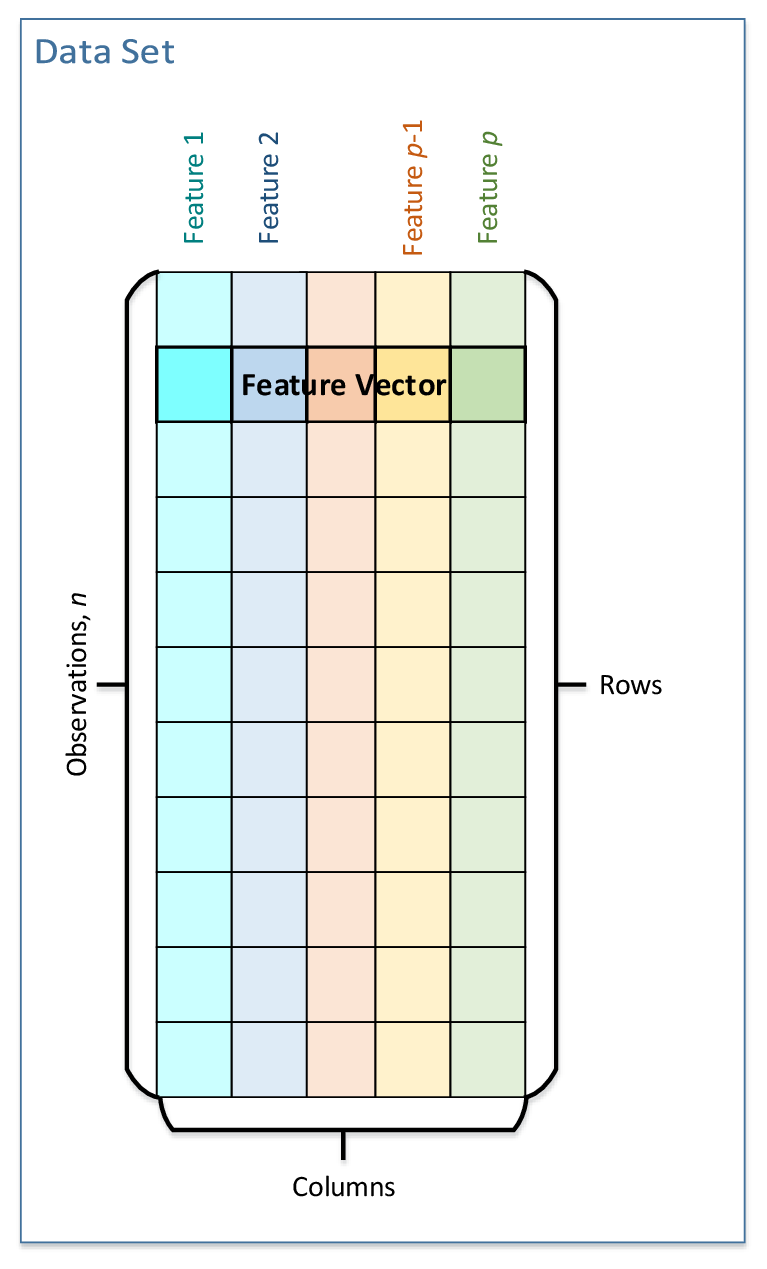
An observation corresponds to a particular measurement of an observed object, and therefore when measurements are done, at distinct moments in time, the set of observations characterizes how the object evolves in time.
It is not a rare situation when only a subset of features can be measured at a given moment. In this case, the non-measured features in the feature vector become blank, or missing. Special statistical techniques enable recovery (emulation) of missing values.
You normally start working with oneDAL by selecting an appropriate data source, which provides an interface for your raw data set. oneDAL data sources support categorical, ordinal, and continuous features. It means that data sources can automatically transform non-numeric categorical and ordinary data into a numeric representation. When the structure of your raw data is more complex or when the default transformation mechanism does not fit your needs, you may customize the data source by implementing a custom derivative class.
Because a data source is typically associated with out-of-memory data, such as files, databases, and so on, streaming out-of-memory data into memory and back is among major functions of a data source. However you can also use a data source to implement an in-memory non-numeric data transformation into a numeric form.
A numeric table is a key interface to operate on numeric in-memory data. oneDAL supports several important cases of a numeric data layout: homogeneous tables, arrays of structures, and structures of arrays, as well as Compressed Sparse Row (CSR) encoding for sparse data.
oneDAL algorithms operate with in-memory numeric data accessed through Numeric table interfaces.