Visible to Intel only — GUID: GUID-F076FBCA-2199-41AD-A10B-A4938C244AF0
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_hist_batch.cpp
df_cls_hist_batch_random.cpp
df_cls_traverse_model.cpp
df_reg_hist_batch.cpp
df_reg_hist_batch_random.cpp
df_reg_traverse_model.cpp
heterogen_table.cpp
homogen_table.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_reg_brute_force_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logistic_regression_dense_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_cor_dense_batch.cpp
pca_precomputed_cov_dense_batch.cpp
pca_svd_dense_batch.cpp
rbf_kernel_dense_batch.cpp
svm_two_class_thunder_dense_batch.cpp
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
connected_components_batch.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_dense_batch.cpp
df_reg_dense_batch.cpp
directed_graph.cpp
graph_service_functions.cpp
heterogen_table.cpp
homogen_table.cpp
jaccard_batch.cpp
jaccard_batch_app.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_cls_kd_tree_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logloss_dense_batch.cpp
louvain_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_dense_batch.cpp
pca_svd_dense_batch.cpp
pca_svd_dense_online.cpp
polynomial_kernel_dense_batch.cpp
rbf_kernel_dense_batch.cpp
shortest_paths_batch.cpp
sigmoid_kernel_dense_batch.cpp
subgraph_isomorphism_batch.cpp
svm_multi_class_thunder_csr_batch.cpp
svm_multi_class_thunder_dense_batch.cpp
svm_nu_cls_thunder_csr_batch.cpp
svm_nu_cls_thunder_dense_batch.cpp
svm_nu_reg_thunder_csr_batch.cpp
svm_nu_reg_thunder_dense_batch.cpp
svm_reg_thunder_csr_batch.cpp
svm_reg_thunder_dense_batch.cpp
svm_two_class_smo_csr_batch.cpp
svm_two_class_smo_dense_batch.cpp
svm_two_class_thunder_csr_batch.cpp
svm_two_class_thunder_dense_batch.cpp
triangle_counting_batch.cpp
K-Means Clustering
Density-Based Spatial Clustering of Applications with Noise
Correlation and Variance-Covariance Matrices
Principal Component Analysis
Principal Components Analysis Transform
Singular Value Decomposition
Association Rules
Kernel Functions
Expectation-Maximization
Cholesky Decomposition
QR Decomposition
Outlier Detection
Distance Matrix
Distributions
Engines
Moments of Low Order
Quantile
Quality Metrics
Sorting
Normalization
Optimization Solvers
Decision Forest
Decision Trees
Gradient Boosted Trees
Stump
Linear and Ridge Regressions
LASSO and Elastic Net Regressions
k-Nearest Neighbors (kNN) Classifier
Implicit Alternating Least Squares
Logistic Regression
Naïve Bayes Classifier
Support Vector Machine Classifier
Multi-class Classifier
Boosting
Visible to Intel only — GUID: GUID-F076FBCA-2199-41AD-A10B-A4938C244AF0
Computation Modes
The library algorithms support the following computation modes:
You can select the computation mode during initialization of the Algorithm.
For a list of computation parameters of a specific algorithm in each computation mode, possible input types, and output results, refer to the description of an appropriate algorithm.
Batch processing
All oneDAL algorithms support at least the batch processing computation mode. In the batch processing mode, the only compute method of a particular algorithm class is used.
Online processing
Some oneDAL algorithms enable processing of data sets in blocks. In the online processing mode, the compute(), and finalizeCompute() methods of a particular algorithm class are used. This computation mode assumes that the data arrives in blocks  . Call the compute() method each time a new input becomes available. When the last block of data arrives, call the finalizeCompute() method to produce final results. If the input data arrives in an asynchronous mode, you can use the getStatus() method for a given data source to check whether a new block of data is available for loading.
. Call the compute() method each time a new input becomes available. When the last block of data arrives, call the finalizeCompute() method to produce final results. If the input data arrives in an asynchronous mode, you can use the getStatus() method for a given data source to check whether a new block of data is available for loading.
The following diagram illustrates the computation schema for online processing:
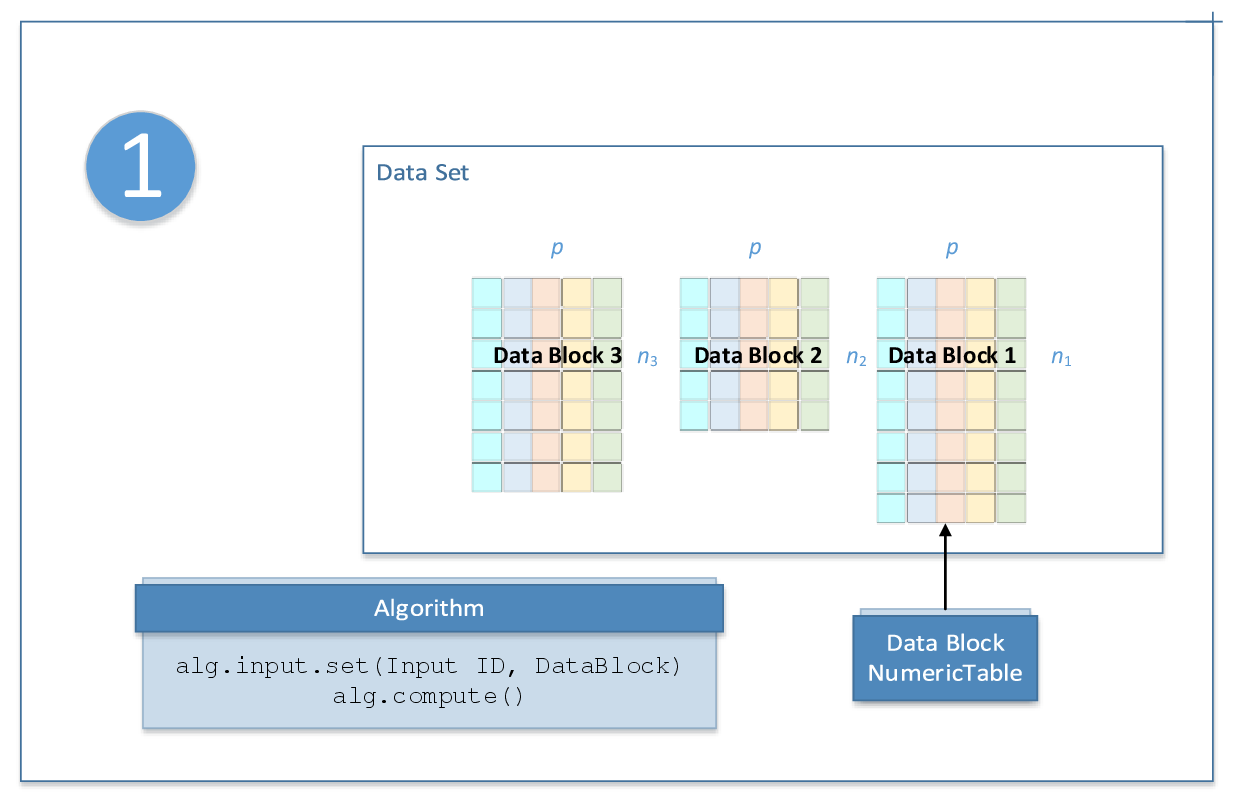
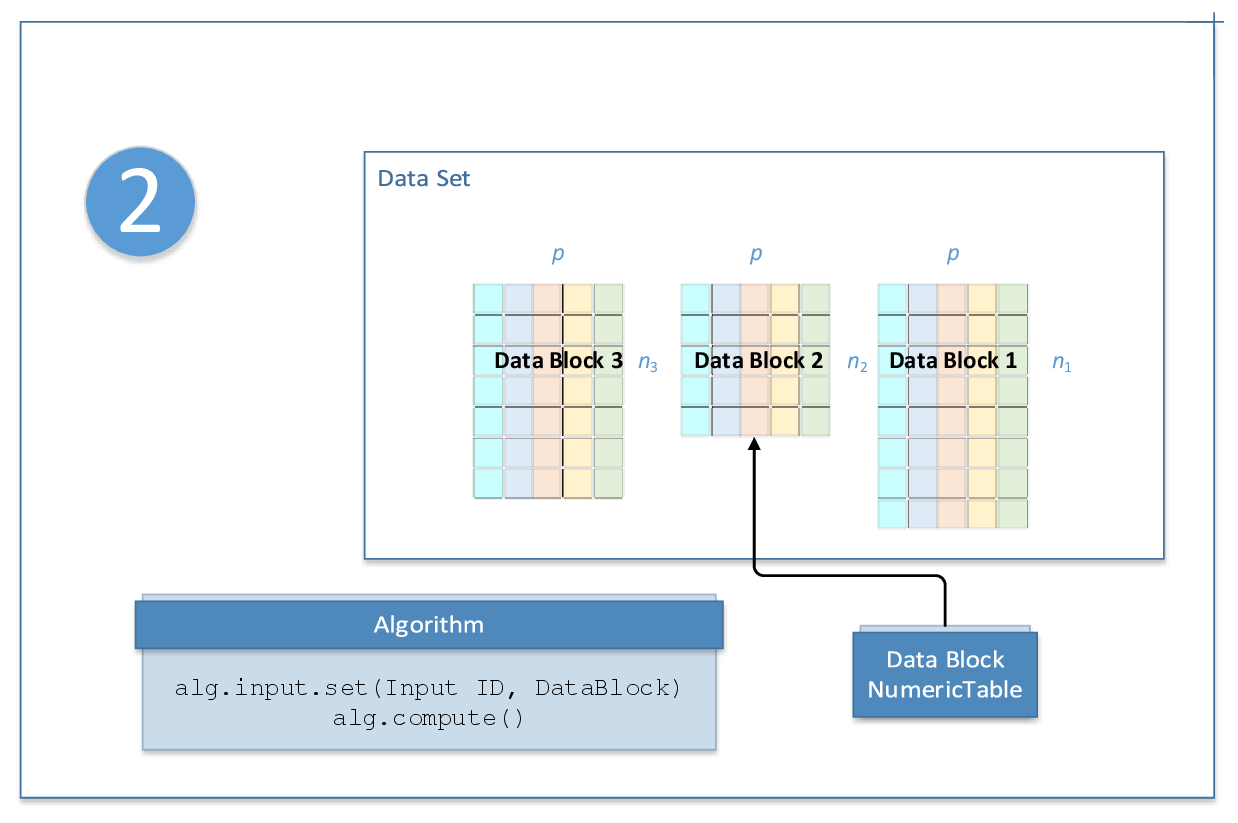
NOTE:
While different data blocks may have different numbers of observations
 , they must have the same number of feature vectors p.
, they must have the same number of feature vectors p.
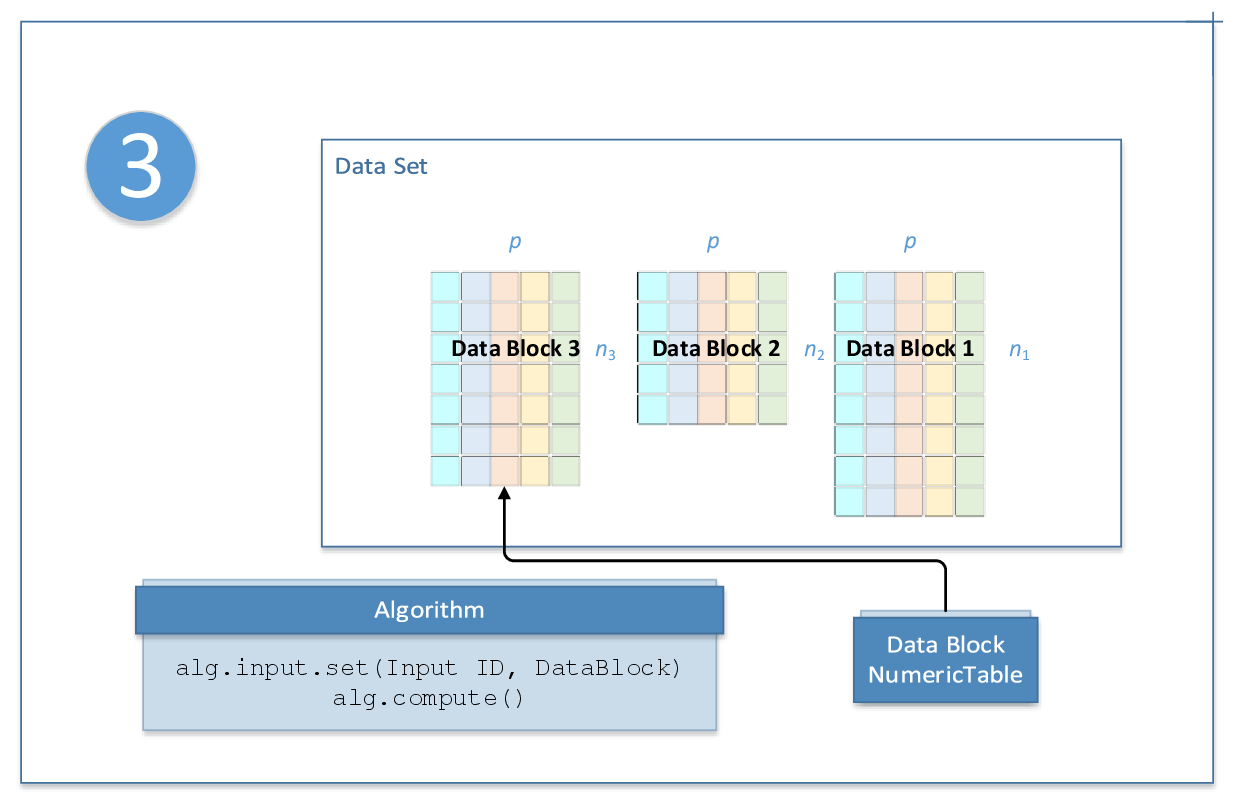
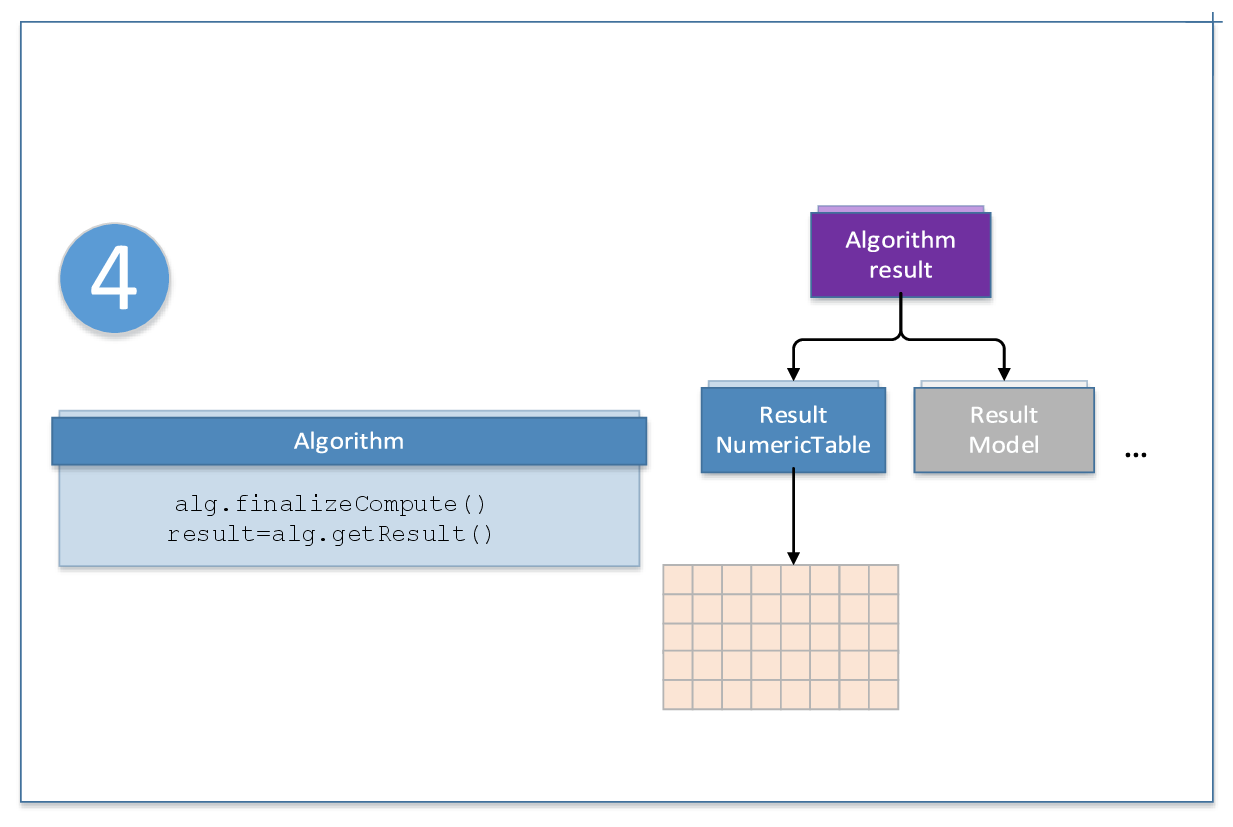
Distributed processing
Some oneDAL algorithms enable processing of data sets distributed across several devices. In distributed processing mode, the compute() and the finalizeCompute() methods of a particular algorithm class are used. This computation mode assumes that the data set is split in nblocks blocks across computation nodes.
Computation is done in several steps. You need to define the computation step for an algorithm by providing the computeStep value to the constructor during initialization of the algorithm. Use the compute() method on each computation node to compute partial results. Use the input.add() method on the master node to add pointers to partial results processed on each computation node. When the last partial result arrives, call the compute() method followed by finalizeCompute() to produce final results. If the input data arrives in an asynchronous mode, you can use the getStatus() method for a given data source to check whether a new block of data is available for loading.
The computation schema is algorithm-specific. The following diagram illustrates a typical computation schema for distribute processing:
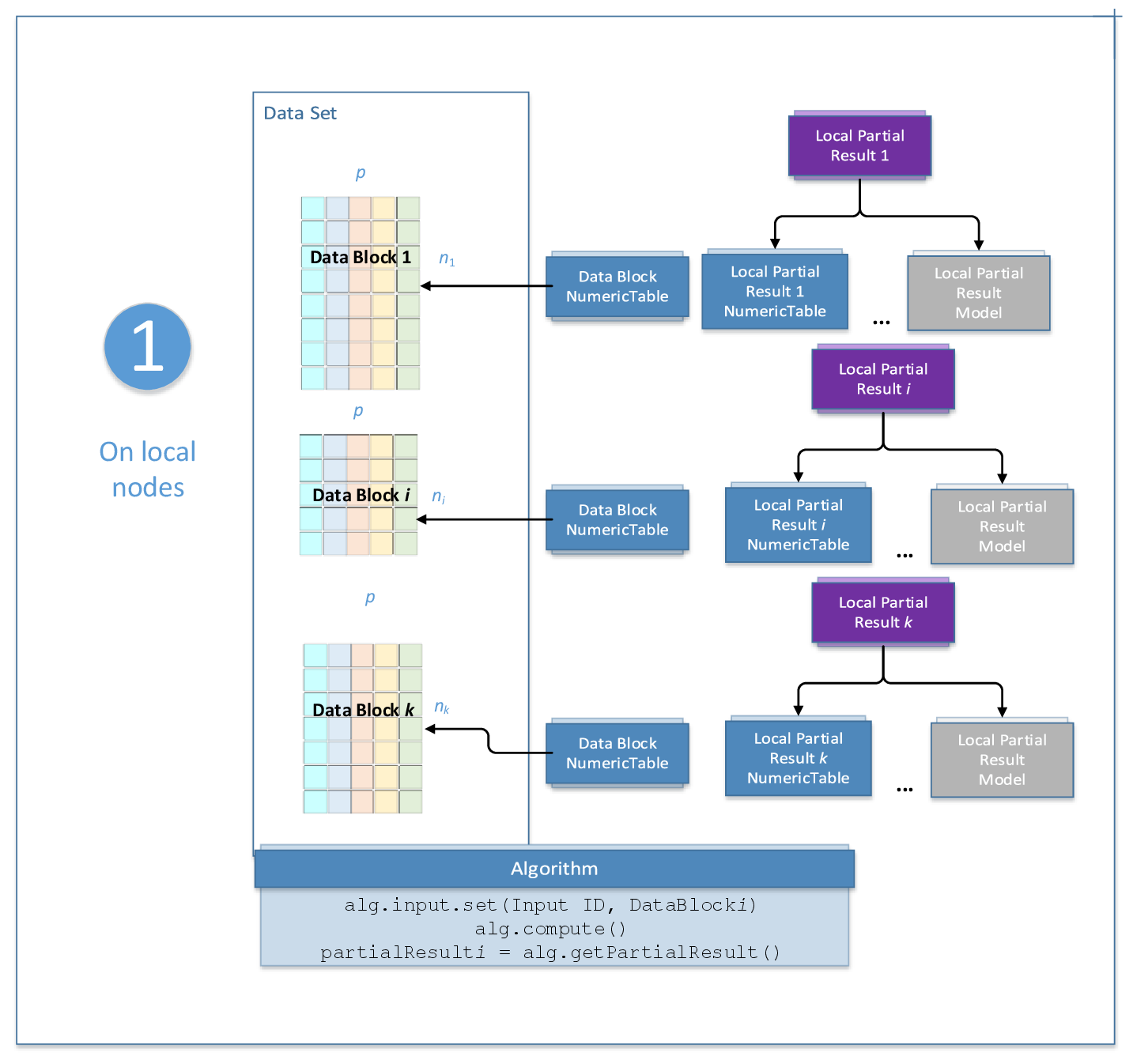
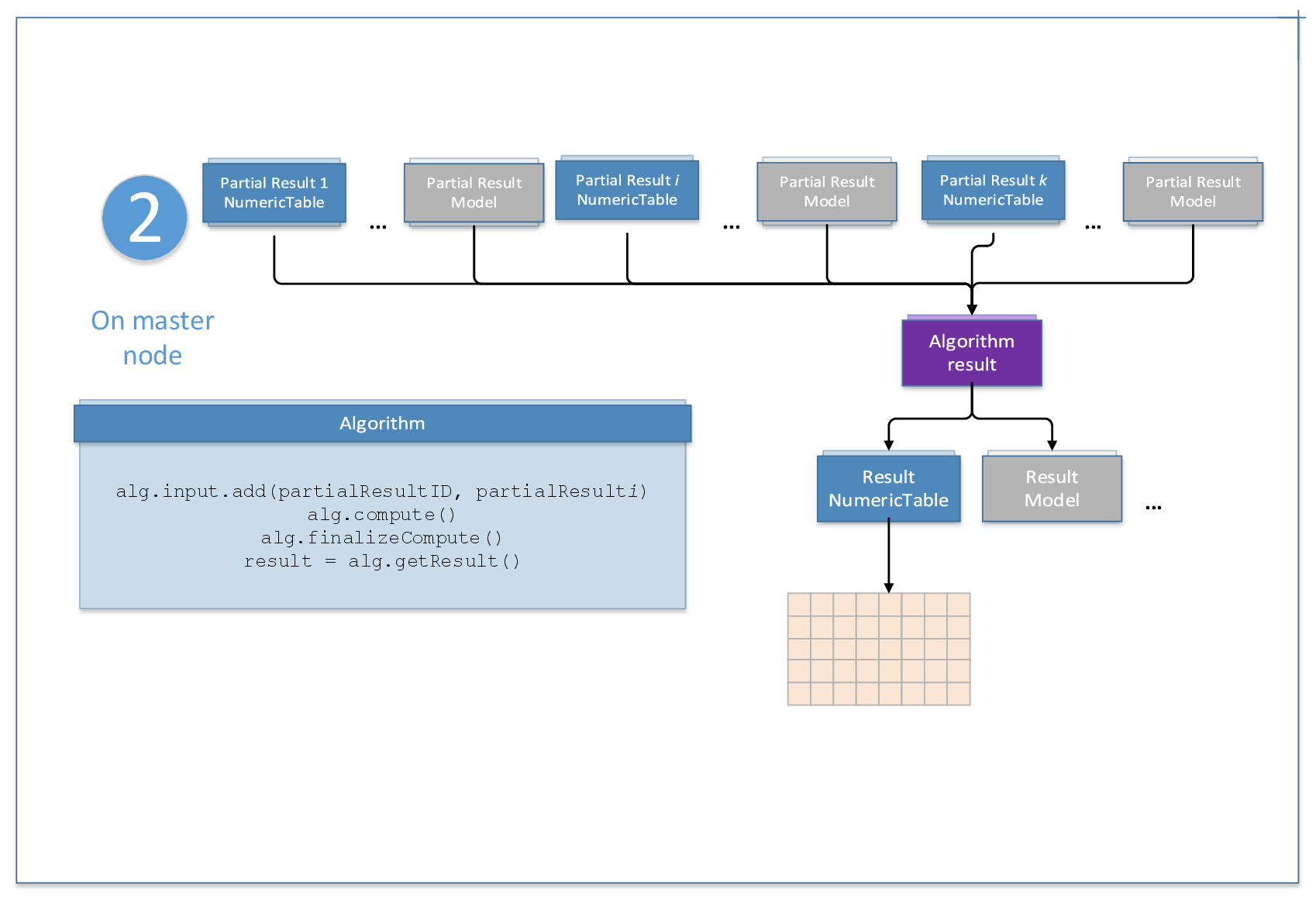
For the algorithm-specific computation schema, refer to the Distributed Processing section in the description of an appropriate algorithm.
Distributed algorithms in oneDAL are abstracted from underlying cross-device communication technology, which enables use of the library in a variety of multi-device computing and data transfer scenarios. They include but are not limited to MPI* based cluster environments, Hadoop* or Spark* based cluster environments, low-level data exchange protocols, and more.