Visible to Intel only — GUID: GUID-3D34EEFE-E4A3-4885-A77E-F4290E3EB0D1
FPGA Optimization Guide for Intel® oneAPI Toolkits
Introduction To FPGA Design Concepts
Analyze Your Design
Optimize Your Design
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the FPGA Optimization Guide for Intel® oneAPI Toolkits
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Shannonization to Improve FMAX/II
Optimize Inner Loop Throughput
Improve Loop Performance by Caching On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Specify Schedule FMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving=<global_memory_name>)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Visible to Intel only — GUID: GUID-3D34EEFE-E4A3-4885-A77E-F4290E3EB0D1
Shannonization to Improve FMAX/II
Shannonization (named after Claude Shannon) is a loop optimization technique that improves the fMAX/II of a design by precomputing operations in a loop and removing the operations from the critical path. To demonstrate shannonization, consider the following example, which counts the number of elements in an array A that are less than some runtime value v:
int A[SIZE] = {/*...*/}; int v = /*some dynamic value*/ int c = 0; for (int i = 0; i < SIZE; i++) { if (A[i] < v) { c++; } }
A possible circuit diagram for this algorithm is shown in the following image, where the orange dotted line represents a possible critical path in the circuit:
Circuit Diagram for the Example Shannonization Algorithm
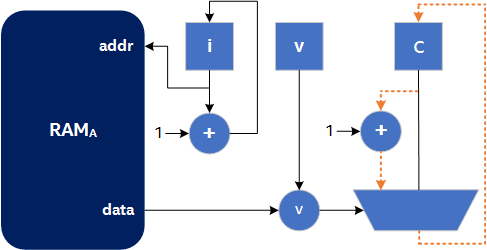
The goal of the shannonization optimization is to remove operations from the critical path. In this case, precompute the next value of c (fittingly named c_next) for a later iteration of the loop to use when required (that is, the next time A[i] < v). This optimization is shown in the following code sample:
int A[SIZE] = {/*...*/}; int v = /*some dynamic value*/ int c = 0; int c_next = 1; for (int i = 0; i < SIZE; i++) { if (A[i] < v) { // these operations can happen in parallel! c = c_next; c_next++; } }
A possible circuit diagram for this optimized algorithm is shown in the following image, where the orange dotted line represents a possible critical path in the circuit:
Circuit Diagram for the Optimized Shannonization Algorithm
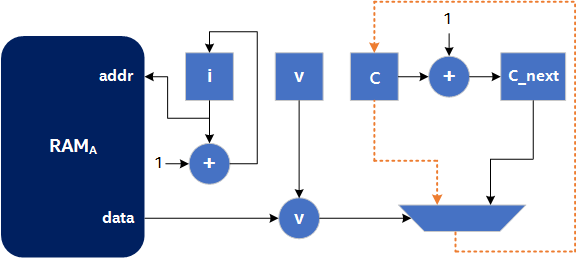
In the Figure 2, the + operation from the critical path is removed. This diagram assumes that the critical path delay through the multiplexer is higher than through the adder. This may not be the case, and the critical path could be from the c register to the c_next register through the adder, in which case, the multiplexer from the critical path is removed. Regardless of which operation has the longer critical path delay (the adder or the multiplexer), an operation from the critical path is removed by precomputing and storing the next value of c. This allows in reducing the critical path delay at the expense of area (in this case, a single 32-bit register).
Parent topic: Loops