Visible to Intel only — GUID: GUID-09754B67-7D66-4917-999D-93E1D461E168
FPGA Optimization Guide for Intel® oneAPI Toolkits
Introduction To FPGA Design Concepts
Analyze Your Design
Optimize Your Design
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the FPGA Optimization Guide for Intel® oneAPI Toolkits
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Shannonization to Improve FMAX/II
Optimize Inner Loop Throughput
Improve Loop Performance by Caching On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Multi-Threaded Host Application
Utilizing Hardware Kernel Invocation Queue
Double Buffering Host Utilizing Kernel Invocation Queue
N-Way Buffering to Overlap Kernel Execution
Prepinning Memory
Simple Host-Device Streaming
Buffered Host-Device Streaming
Roofline Analysis
Optimizing the Design for Throughput
Streaming API
Specify Schedule FMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving=<global_memory_name>)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Visible to Intel only — GUID: GUID-09754B67-7D66-4917-999D-93E1D461E168
Buffered Host-Device Streaming
In this topic, you learn how to optimize a full system design that streams data from the host to the device and back to the host and create heterogeneous designs that can achieve high throughput. The techniques described in this topic are not specific to a CPU-FPGA system, and you can apply them to GPUs, multi-core CPUs, and other processing units as well.
TIP:
If your BSP supports host pipes, use them instead of buffered host-device streaming. For information about host pipes, refer to Host Pipes.
IMPORTANT:
Prior to learning about buffered host-device streaming concept, you must review the following concepts:
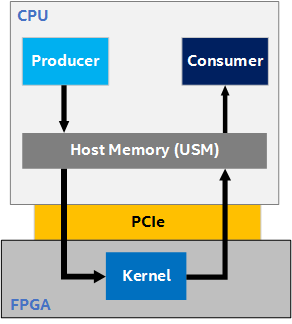
To understand the concept of buffered host-device streaming, consider an example design where a Producer (running on the CPU) produces data into USM host allocations, a Kernel (running on the FPGA) processes this data and produces output into host allocations, and a Consumer (running on the CPU) consumes the data. Data is shared between the host and FPGA device via host pointers (pointers to USM host allocations).
Example Design with a Producer, Kernel, and Consumer

In heterogeneous systems, it is important to understand how different compute architectures are connected (that is, how data is transferred from one to another) to better reason about and address performance bottlenecks in the system. The following figure is a slightly more detailed illustration of the processing pipeline in the example design, which shows the data flow between the Producer, Kernel, and Consumer. It illustrates that the Producer and Consumer operations both execute on the CPU and communicate with the FPGA kernel over a PCIe link (PCIe Gen3 x16).
Detailed Illustration of the Processing Pipeline
Roofline Analysis
When designing for throughput, you must first estimate the maximum throughput the system is capable of. This back-of-the-envelop calculation is called roofline analysis. To calculate the maximum achievable throughput of the Producer-Kernel-Consumer design shown in Figure 2, assume that the Producer and Consumer have infinite bandwidth (that is, they can produce or consume data at an infinite rate, respectively). Then, the bottleneck in the system is the FPGA kernel. Assume that the kernel has an fMAX of 400MHz and processes 64 bytes per cycle. The following is kernel's maximum steady-state throughput:
400 MHz * 64 bytes/cycle = 25.6 GB/s ~= 26 GB/s.
In reality, the rate of data transfer to and from the kernel depends on the bandwidth of the PCIe link. In Figure 2, you can observe that this depends on the bandwidth of the PCIe link. It has been experimentally measured that the PCIe Gen3 x16 link has a total bandwidth of ~22 GB/s (11 GB/s bidirectional). This means that, while the kernel can process data at 26 GB/s, you can only send data to it and receive from it at a rate of 11 GB/s. The system bottleneck is the PCIe link between the CPU and FPGA. It is common for the bottleneck in a heterogeneous system to be the inter-device link, rather than any single device.
In this analysis so far, you assumed that the Producer and Consumer had infinite bandwidth. You can now perform a roofline analysis on the entire system by assuming a finite bandwidth for the Producer and Consumer. For the entire Producer-Kernel-Consumer design, the maximum possible throughput is the minimum of the Producer, Kernel, and Consumer throughput, and the bandwidth of the link (in this case, PCIe) connecting the CPU and FPGA (a chain is only as strong as the weakest link).
Optimizing the Design for Throughput
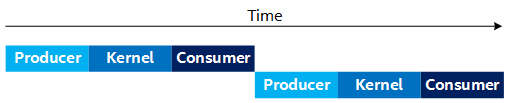
A naive approach to this design is for the Producer, Kernel, and Consumer to run sequentially that is depicted by the following timing diagram. This naive approach underperforms because operations, which could run in parallel, are run sequentially. For example, in the following figure, the Producer could be producing the second set of data, while the Consumer is consuming the first set of data:
Timing Diagram
To improve the performance, you can create a separate CPU thread (called the Producer thread) that produces all of the data for the Kernel to process, and consumes later as shown in the following figure. This allows the Producer and Consumer to run in parallel (that is, the Producer thread produces the next set of data, while the Consumer consumes the current data).
Timing Diagram with Producer and Consumer Running in Parallel
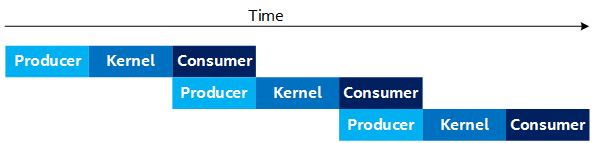
This approach improves the design's throughput, but does require more complicated thread synchronization logic to synchronize between the Producer thread and the main thread that is launching kernels and consuming its output.
Observe that in the Figure 4, the Producer and Consumer are running simultaneously (in separate threads). You must consider the fact that both of these processes are running on the CPU in parallel, which affects their individual throughput capabilities. For example, running these processes in parallel can result in saturating the CPU's memory bandwidth, and therefore lower the overall throughput for the Producer and Consumer processes even if the threads run on different CPU cores.
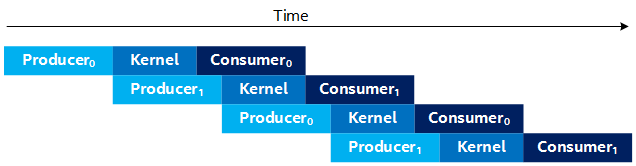
By putting the Producer into its own thread, you can improve performance by producing and consuming data simultaneously. However, it is ideal if the Producer can produce the next set of data while the kernel is processing the current data. This allows the next kernel to launch as soon as the current kernel finishes, instead of waiting for the Producer to finish, as shown in Figure 4. Unfortunately, you cannot produce data into the buffer that the kernel is currently processing, since it is still in use by the kernel. To address this, use multiple buffers (that is, N-Way buffering) of the input and output buffers, which results in a timing diagram, as shown in the following:
Timing Diagram With Multiple Buffers
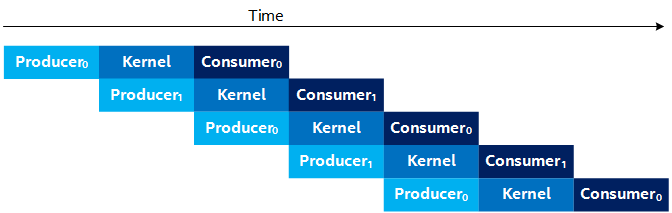
The subscript number on the Producer and Consumer (for example, Producer0 and Consumer0) represents the buffer index they are processing. The Figure 5 illustrates the case where you use two sets of buffers (double-buffering). Observe that in Figure 5, the Producer produces into buffer 1 (Producer1) while the kernel is processing the data from buffer 0. Thus, by the time the kernel finishes processing buffer 0, it can start processing buffer 1 right away, so long as the Producer has finished producing the next buffer of data.
In the steady-state for Figure 5, the throughput of the design is bottlenecked by the throughput of the slowest stage (the Producer, Kernel, or Consumer), which matches the Roofline Analysis you did earlier. For example, the Figure 6 shows an example timeline where the Kernel is the throughput bottleneck. The Figure 7 shows an example timeline where the Producer (or Consumer) is the bottleneck.
Timing Diagram With Kernel as the Throughput Bottleneck
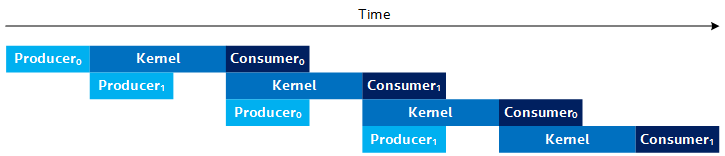
Timing Diagram With Producer/Consumer as the Throughput Bottleneck
Streaming API
In the Buffered Host-Device Streaming example on GitHub, the techniques described in the previous section are implemented in two ways. The design is implemented directly using SYCL USM host allocations and C++ multithreading, and the kernel queue is managed intelligently. The code achieves high performance, but it might be difficult to understand and extend it to different designs. To address this, a convenient and performant API wrapper (HostStreamer.hpp) is created. The same design is implemented in streaming_with_api.hpp with similar performance and significantly less code that is much easier to understand.
IMPORTANT:
While the code that uses the HostStreamer API achieves similar performance to a direct implementation, it uses extra FPGA resources. The direct implementation has a single kernel (Kernel) that does all the processing. Using the API creates a Producer and Consumer kernel that access host allocations and produce/consume data to/from the processing kernel (APIKernel in streaming_with_api.hpp). These extra kernels (that are transparent) are the mechanism by which the API abstracts the production/consumption of data, but come at the cost of extra FPGA resources. However, when compiled for the Intel FPGA PAC D5005, these extra kernels result in less than 1% increase in FPGA resource utilization. Therefore, given the programming convenience they provide, the tradeoff is often worth it.
Parent topic: Host