Visible to Intel only — GUID: GUID-9FA1CF56-6AA1-4B06-869A-8652F088C41D
FPGA Optimization Guide for Intel® oneAPI Toolkits
Introduction To FPGA Design Concepts
Analyze Your Design
Optimize Your Design
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the FPGA Optimization Guide for Intel® oneAPI Toolkits
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Shannonization to Improve FMAX/II
Optimize Inner Loop Throughput
Improve Loop Performance by Caching On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Specify Schedule FMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving=<global_memory_name>)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Visible to Intel only — GUID: GUID-9FA1CF56-6AA1-4B06-869A-8652F088C41D
Kernel Memory
If you declare a private array, a group local memory, or a local accessor, then the Intel® oneAPI DPC++/C++ Compiler creates a kernel memory in hardware. Kernel memory is sometimes referred to as on-chip memory because it is created from memory sources (such as RAM blocks) available on the FPGA. The following source code snippet illustrates both a kernel and a global memory and their accesses:
constexpr int N = 32; Q.submit([&](handler &cgh) { // Create an accessor for device global memory from buffer buff accessor acc(buff, cgh, write_only); cgh.single_task<class Test>([=]() { // Declare a private array int T[N]; // Write to private memory for (int i = 0; i < N; i++) T[i] = i; // Read from private memory and write to global memory through the accessor for (int i = 0; i < N; i+=2) acc[i] = T[i] + T[i+1]; }); });
To allocate local memory that is accessible to and shared by all work items of a workgroup, define a group-local variable at the function scope of a workgroup using the group_local_memory_for_overwrite function, as shown in the following example:
Q.submit([&](handler &cgh) { cgh.parallel_for<class Test>( nd_range<1>(range<1>(128), range<1>(32)), [=](nd_item<1> item) { auto ptr = group_local_memory_for_overwrite<int[64]>(item.get_group()); auto& ref = *ptr; ref[2 * item.get_local_linear_id()] = 42; }); });
The example above creates a kernel with four workgroups, each containing 32 work items. It defines an int[64] object as a group-local variable, and each work-item in the workgroup obtains a multi_ptr to the same group-local variable.
The compiler performs the following to build a memory system:
- Maps each array access to a load-store unit (LSU) in the datapath that transacts with the kernel memory through its ports.
- Builds the kernel memory and LSUs and retains complete control over their structure.
- Automatically optimizes the kernel memory geometry to maximize the bandwidth available to loads and stores in the datapath.
- Attempts to guarantee that kernel memory accesses never stall.
These are discussed in detail in later sections of this guide.
Stallable and Stall-Free Memory Systems
Accesses to a memory (read or write) can be stall-free or stallable:
| Memory Access | Description |
|---|---|
| Stall-free | A memory access is stall-free if it has contention-free access to a memory port. This is illustrated in Figure 1. A memory system is stall-free if each of its memory operations has contention-free access to a memory port. |
| Stallable | A memory access is stallable if it does not have contention-free access to a memory port. When two datapath LSUs attempt to transact with a memory port in the same clock cycle, one of those memory accesses is delayed (or stalled) until the memory port in contention becomes available. |
As much as possible, the Intel® oneAPI DPC++/C++ Compiler attempts to create stall-free memory systems for your kernel.
A read or write is stall-free if it has contention-free access to a memory port, as shown in the following figure:
Examples of Stall-free and Stallable Memory Systems
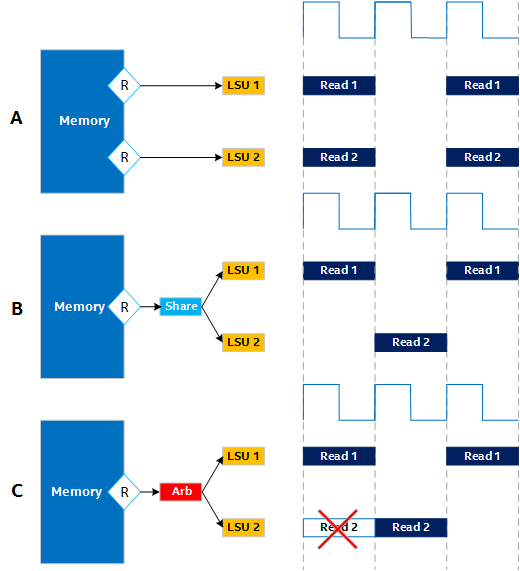
The Figure 1 shows the following example memory systems:
- A: A stall-free memory system
This memory system is stall-free because, even though the reads are scheduled in the same cycle, they are mapped to different ports. There is no contention for accessing the memory systems.
- B: A stall-free memory system
This memory system is stall-free because the two reads are statically scheduled to occur in different clock cycles. The two reads can share a memory port without any contention for the read access.
- C: A stallable memory system
This memory system is stallable because two reads are mapped to the same port in the same cycle. The two reads happen at the same time. These reads require collision arbitration to manage their port access requests, and arbitration can affect throughput.
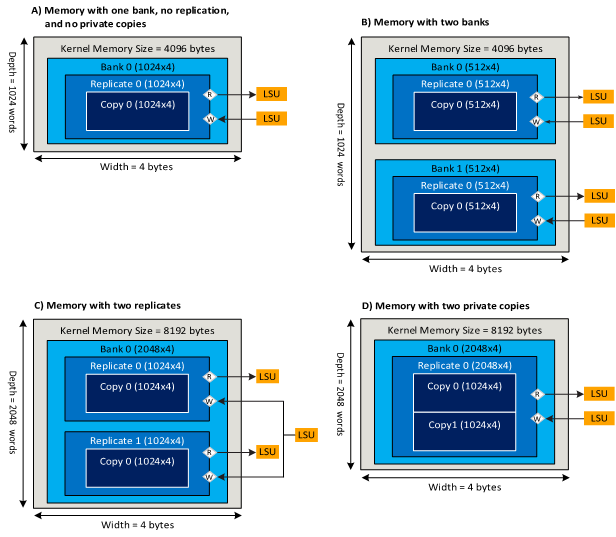
A kernel memory system consists of the following parts:
| Part | Description |
|---|---|
| Port | A memory port is a physical access point into a memory. A port is connected to one or more load-store units (LSUs) in the datapath. An LSU can connect to one or more ports. A port can have one or more LSUs connected. |
| Bank | A memory bank is a division of the kernel memory system that contains a subset of the data stored. That is, all of the data stored for a kernel is split across banks, with each bank containing a unique piece of the stored data. A memory system always has at least one bank. |
| Replicate | A memory bank replicate is a copy of the data in the memory bank with its own ports. All replicates in a bank contain the same data. Each replicate can be accessed independent of the others A memory bank always has at least one replicate. |
| Private Copy | A private copy is a copy of the data in a replicate that is created for nested loops to enable concurrent iterations of the outer loop. A replicate can comprise multiple private copies, with each iteration of an outer loop having its own private copy. Because each outer loop iteration has its own private copy, private copies are not expected to contain the same data. |
The following figure illustrates the relationship between banks, replicates, ports, and private copies:
Schematic Representation of Kernel Memories Showing the Relationship between Banks, Replicates, Ports, and Private Copies
Strategies That Enable Concurrent Stall-Free Memory Accesses
The compiler uses a variety of strategies to ensure that concurrent accesses are stall-free including:
- Adjusting the number of ports the memory system has. This can be done either by replicating the memory to enable more read ports or by using double pumping to enable four ports instead of two per replicate. All of the replicate's physical access ports can be accessed concurrently.
- Partitioning memory content into one or more banks, such that each bank contains a subset of the data contained in the original memory (corresponds to the top-right box of Schematic Representation of Local Memories Showing the Relationship between Banks, Replicates, Ports, and Private Copies). The banks of a kernel memory can be accessed concurrently by the datapath.
- Replicating a bank to create multiple coherent replicates (corresponds to the bottom-left box of Schematic Representation of Local Memories Showing the Relationship between Banks, Replicates, Ports, and Private Copies). Each replicate in a bank contains identical data. The replicates are loaded concurrently.
- Creating private copies of an array declared inside a loop nest (corresponds to the bottom-right box of Schematic Representation of Local Memories Showing the Relationship between Banks, Replicates, Ports, and Private Copies). This enables loop pipelining, as each pipeline-parallel loop iteration accesses its own private copy of the array declared within the loop body. It is not expected for the private copies to contain the same data.
Despite the compiler’s best efforts, the kernel memory system can still be stallable. This might happen due to resource constraints or memory attributes defined in your source code. In that case, the compiler tries to minimize the hardware resources consumed by the arbitrated memory system.
Parent topic: Memory Types