Remote Inference End-to-End Use Case
This tutorial describes how to use the basic fleet management server to set object detection inference on EI for AMR remotely at the OpenVINO™ model server when its battery is lower than the 60% threshold. If the battery is equal to or greather than 60%, the inference is set to be done locally at EI for AMR.
You must do all of the sections in this tutorial in the order listed.
Machine A is the server.
Machine B is an EI for AMR target that sends data to the server and receives instructions (the robot).
Machine A and Machine B need to be in the same network.
Prerequisites: The robot and the server are configured as instructed in their Get Started Guides:
Configuring the client: Get Started Guide for Robots
Configuring the server (Single-Node or Multi-Node): Get Started Guide for Robot Orchestration
Basic Fleet Management (both ThingsBoard* server and Intel® In-Band Manageability are required in the remote inference use case): Get Started Guide for Robot Orchestration
Configure the OpenVINO™ Model Server
On Machine A
Go to the AMR_containers folder:
cd <edge_insights_for_amr_path>/Edge_Insights_for_Autonomous_Mobile_Robots_<version>/AMR_server_containers
Set up the necessary environment variables. Add the environment variables in /etc/environment:
export DOCKER_BUILDKIT=1 export COMPOSE_DOCKER_CLI_BUILD=1 export DOCKER_HOSTNAME=$(hostname) export DOCKER_USER_ID=$(id -u) export DOCKER_GROUP_ID=$(id -g) export DOCKER_USER=$(whoami) export DISPLAY=localhost:0.0
Source the configuration file you have edited:
source /etc/environment
Generate the keys used for server-client remote inference:
cd 01_docker_sdk_env/artifacts/02_edge_server/edge_server_fleet_management/ovms/ chmod +x generate_ovms_certs.sh sudo ./generate_ovms_certs.sh <host-name-of-server>
NOTE:If Single-Node orchestration is deployed, the hostname of the Single-Node server shall be used to generate certificates. If Multi-Node orchestration is deployed, the hostname of the control plane shall be used to generate certificates.Copy required client keys onto the client machine:
# From server folder `keys/` transfer (scp) server.pem, client.pem and client.key to client: cd keys/ scp -r client.key client.pem server.pem <client_user>@<client_hostname>:~/
On Machine B
Copy the keys to /etc/amr/ri-certs:
mkdir -p /etc/amr/ri-certs sudo cp ~/{client.key,client.pem,server.pem} /etc/amr/ri-certs
Start the OpenVINO™ Model Server
On Machine A
If Intel® Smart Edge Open Multi-Node is deployed, there are two machines for orchestration. Machine A-1 represents the controller, and Machine A-2 represents the server node where the OpenVINO™ model server pod is deployed.
If Intel® Smart Edge Open Single-Node is deployed, Machine A-1 and A-2 are the same machine.
Run the following command to avoid an Intel® Smart Edge Open playbook known limitation:
sed -i "s/edge-server-ubuntu2004-ovms-tls/edge-server-ovms-tls/g" AMR_server_containers/01_docker_sdk_env/docker_orchestration/ansible-playbooks/02_edge_server/openvino_model_server/ovms_playbook_install.yaml
Go to <edge_insights_for_amr_path>/Edge_Insights_for_Autonomous_Mobile_Robots_<release>, and run on Machine A-1:
ansible-playbook AMR_server_containers/01_docker_sdk_env/docker_orchestration/ansible-playbooks/02_edge_server/openvino_model_server/ovms_playbook_install.yaml
Verify that the services, pods, and deployment are running on Machine A-1:
$ kubectl get all --output=wide --namespace ovms-tls NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/ovms-deployment-75c7dffdc5-cgxp9 1/1 Running 1 (50m ago) 50m 10.245.202.9 glaic3roscube <none> <none> NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/ovms-service NodePort 10.110.177.249 <none> 3335:32762/TCP,2225:32763/TCP 50m app.kubernetes.io/instance=ovms-tls-abcxzy,app.kubernetes.io/name=ovms-tls NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR deployment.apps/ovms-deployment 1/1 1 1 50m ovms-tls 10.237.23.153:30003/intel/ovms-tls:2022.2 app.kubernetes.io/instance=ovms-tls-abcxzy,app.kubernetes.io/name=ovms-tls NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR replicaset.apps/ovms-deployment-75c7dffdc5 1 1 1 50m ovms-tls 10.237.23.153:30003/intel/ovms-tls:2022.2 app.kubernetes.io/instance=ovms-tls-abcxzy,app.kubernetes.io/name=ovms-tls,pod-template-hash=75c7dffdc5
NOTE:CLUSTER-IP is a virtual IP that is allocated by Kubernetes* to a service. It is the Kubernetes* internal IP. Two different pods can communicate using this IP.Verify that the Docker* container is running on Machine A-2:
docker ps | grep ovms-tls 6b64514a4b9a c9e7db04fe06 "/usr/bin/dumb-init …" 10 minutes ago Up 10 minutes k8s_ovms-tls_ovms-deployment-5856948447-t78tz_ovms-tls_3cd84b35-c604-4948-9228-e381fd0714fa_1 ceeaa7673bcd k8s.gcr.io/pause:3.5 "/pause" 10 minutes ago Up 10 minutes k8s_POD_ovms-deployment-5856948447-t78tz_ovms-tls_3cd84b35-c604-4948-9228-e381fd0714fa_1
If you encounter errors, see Troubleshooting for Robot Orchestration Tutorials.
Configure Object Detection with Remote Inference
On Machine B
Go to the AMR_containers folder:
cd <edge_insights_for_amr_path>/Edge_Insights_for_Autonomous_Mobile_Robots_<version>/AMR_containers
Set up the environment:
export DOCKER_BUILDKIT=1 export COMPOSE_DOCKER_CLI_BUILD=1 export DOCKER_HOSTNAME=$(hostname) export DOCKER_USER_ID=$(id -u) export DOCKER_GROUP_ID=$(id -g) export DOCKER_USER=$(whoami)
Make additional changes for remote inference:
Put the <host-name-of-server> used in the key generation step above inside the config file:
vim 05_tutorials/launch/remote_inference.launch.py
Update remote_hostname:
For Intel® Smart Edge Open Multi-Node, use the control plane hostname.
For Intel® Smart Edge Open Single-Node, use ThingsBoard* server pod’s hostname.
<remote_hostname>: 32762
Start Object Detection with Remote Inference
On Machine B
When running the client on a robot:
CHOOSE_USER=root docker-compose -f 01_docker_sdk_env/docker_compose/05_tutorials/aaeon_wandering_remote_inference.yml up object-detection realsense aaeon-amr-interface ros-base-camera-tf collab-slam fastmapping nav2 wandering object-detection vda5050-ros2-bridge
If a battery bridge is installed, run:
CHOOSE_USER=root docker-compose -f 01_docker_sdk_env/docker_compose/05_tutorials/aaeon_wandering_remote_inference.yml up battery-bridge object-detection realsense aaeon-amr-interface ros-base-camera-tf collab-slam fastmapping nav2 wandering object-detection vda5050-ros2-bridge
When running the client on a laptop or PC with a Intel® RealSense™ camera connected:
Before opening the Docker* images required to run object detection inference, make sure to set up your ROS_DOMAIN_ID in the common.yml file. See: Troubleshooting for Robot Tutorials, “Use ROS_DOMAIN_ID to Avoid Interference in ROS Messages”.
CHOOSE_USER=root docker-compose -f 01_docker_sdk_env/docker_compose/05_tutorials/aaeon_wandering_remote_inference.yml up battery-bridge realsense ros-base-camera-tf object-detection vda5050-ros2-bridge
Because this use case is not executed on a robot with a real battery, you can switch between local and remote inference by manually setting the battery percentage values. In order to be able to do this, you need to have installed the battery kernel module. See: Basic Fleet Management Use Case, “Install the battery-bridge kernel module” for details.
After the battery-bridge kernel module is installed, you can adjust the battery percentage to different values.
Open a new terminal window, and update the battery percentage to a value equal to or higher than 60%:
echo 'capacity0 = 60' | sudo tee /dev/battery_bridge
After setting the battery percentage to 60, the inference in the object-detection terminal should continue to run locally.
Set the battery percentage to a value below 60:
echo 'capacity0 = 59' | sudo tee /dev/battery_bridge
After setting the battery percentage to 59, the object-detection should switch to run remote inference.
Example logs when Local Inference is performed:
[object_detection_node-3] [object_detection_node-3] [ INFO ] <LocalInference> Done frame: 5516 . Processed in: 0.279625 ms [object_detection_node-3] [object_detection_node-3] [ INFO ] <LocalInference> Label tv [object_detection_node-3] [object_detection_node-3] [ INFO ] <LocalInference> Done frame: 5517 . Processed in: 0.240508 ms [object_detection_node-3] [object_detection_node-3] [ INFO ] <LocalInference> Label tv
Example logs when Remote Inference is performed:
[object_detection_node-3] [INFO] [1643382428.696445729] [object_detection]: switchToRemoteInfCallback [object_detection_node-3] [INFO] [1643382428.720869717] [object_detection]: <RemoteInference> Sending Image [object_detection_node-3] [INFO] [1643382428.854300655] [object_detection]: <RemoteInference> Sending Image [remote_inference-4] [INFO] [1643382428.863697253] [remote_inference]: <RemoteInference> Receiving video frame [object_detection_node-3] [INFO] [1643382428.882912426] [object_detection]: <RemoteInference> Sending Image [remote_inference-4] [INFO] [1643382428.895332223] [remote_inference]: <RemoteInference> Processing and inference took 31.16 [object_detection_node-3] [INFO] [1643382428.896419726] [object_detection]: <RemoteInference> Detected Objects Received [object_detection_node-3] [INFO] [1643382428.896478543] [object_detection]: <RemoteInference> Label : tv [remote_inference-4] [INFO] [1643382428.897817637] [remote_inference]: <RemoteInference> Receiving video frame [object_detection_node-3] [INFO] [1643382428.921090305] [object_detection]: <RemoteInference> Sending Image [remote_inference-4] [INFO] [1643382428.922211172] [remote_inference]: <RemoteInference> Processing and inference took 23.68
New Rules in the Basic Fleet Management Server
On Machine A
New rules in Root Chain are added to handle a battery level of less than 60% and equal to or greater than 60% scenarios.
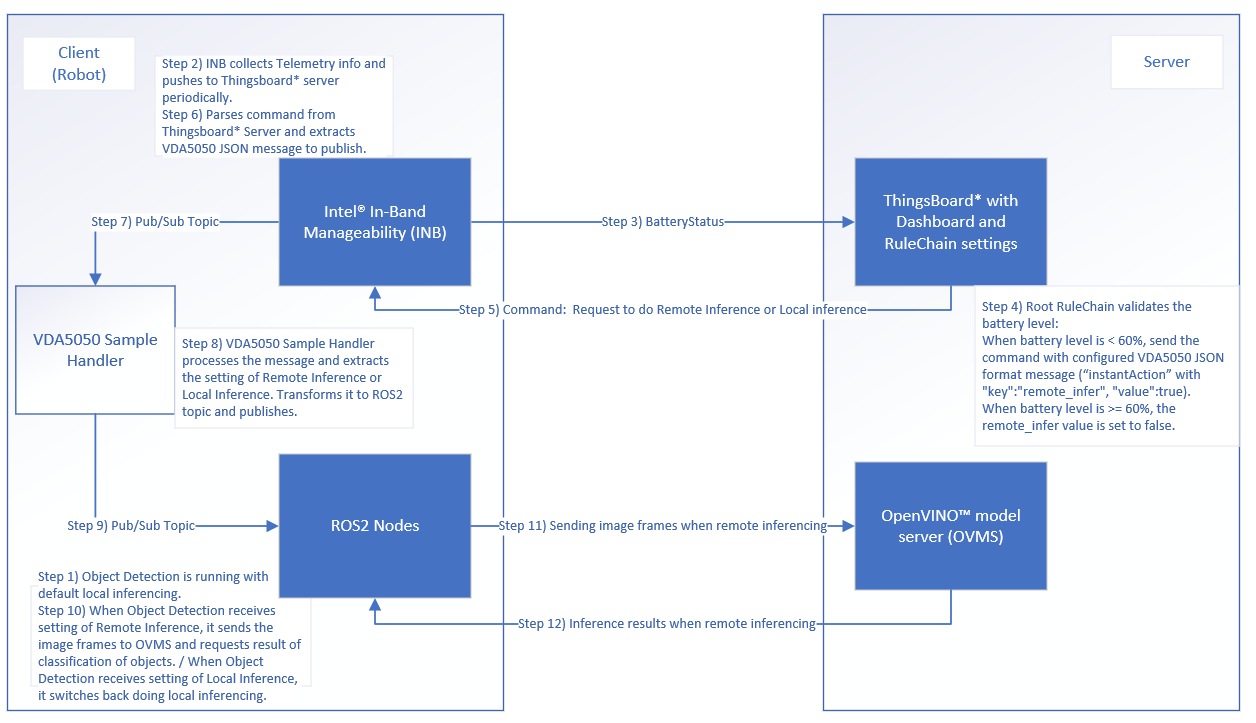
Collaboration Diagram
When a robot’s battery level is less than 60%, basic fleet management tells the robots to do Remote Inference. When the battery level is back to equal or greater than 60%, basic fleet management tells the robots to do Local Inference. The following figure depicts the steps.