Visible to Intel only — GUID: GUID-255623E0-2065-43FF-8EBA-76527D44B690
Intel oneAPI DPC++/C++ Compiler Handbook for FPGAs Overview
Introduction To FPGA Design Concepts
Intel oneAPI FPGA Development
Getting Started with the Intel oneAPI DPC++/C++ Compiler for Intel FPGA Development
Defining a Kernel for FPGAs
Debugging and Verifying Your Design
Analyzing Your Design
Optimizing Your Kernel
Optimizing Your Host Application
Integrating Your Kernel into DSP Builder for Intel FPGAs
Integrating Your RTL IP Core Into a System
RTL IP Core Kernel Interfaces
Loops
Pipes
Data Types and Arithmetic Operations
Parallelism
Memories and Memory Operations
Libraries
Additional FPGA Acceleration Flow Considerations
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the Intel oneAPI DPC++/C++ Compiler Handbook for Intel FPGAs
Notices and Disclaimers
Set the Environment Variables and Launch Visual Studio* Code
Create an FPGA Visual Studio* Code Project
Enable Code Completion in a Visual Studio* Code Project
Configure Running and Debugging in a Visual Studio* Code Project
Debugging Your Kernel in Visual Studio* Code with a Native Debugger
Generate and View the FPGA Optimization Report
Build and Run the FPGA Hardware Image
Throughput
Resource Use
System-level Profiling Using the Intercept Layer for OpenCL™ Applications
Multithreaded Host Application
Utilizing Hardware Kernel Invocation Queue
Double Buffering Host Utilizing Kernel Invocation Queue
N-Way Buffering to Overlap Kernel Execution
Prepinning Memory
Simple Host-Device Streaming
Buffered Host-Device Streaming
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Improve fMAX/II with Shannonization
Optimize Inner Loop Throughput
Improve Loop Performance by Caching Data in On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Specify Schedule fMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Allow Wide Memory Initialization (-Xsallow-wide-device-globals)
Specify Schedule fMAX Target for Kernels (scheduler_target_fmax_mhz)
Specify a Workgroup Size (max_work_group_size/reqd_work_group_size)
Specify Number of SIMD Work Items (num_simd_work_items)
Omit Hardware that Generates and Dispatches Kernel IDs (max_global_work_dim)
Omit Hardware that Supports Global Work Offsets (no_global_work_offset)
Reduce Kernel Area and Latency (use_stall_enable_clusters)
Visible to Intel only — GUID: GUID-255623E0-2065-43FF-8EBA-76527D44B690
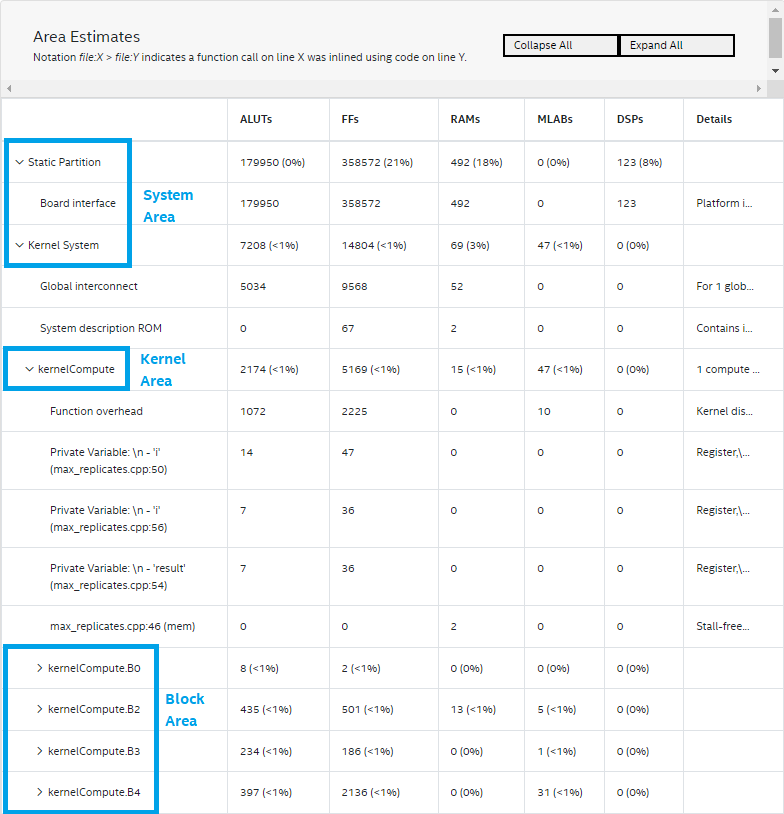
Area Estimates
This view gives you an estimate of how many device resources your design news. The view can be useful if you are trying to ensure that your design fits onto the FPGA device, or you are trying to keep the design below a certain resource footprint.
The report provides the following information:
- Detailed area breakdown of the whole DPC++ system, mapped to your source code where possible.
- Architectural details to give insight into the generated hardware and offers actionable suggestions to resolve potential inefficiencies.
To view the Area Estimates report, click Area Estimates.
As you can observe in the following figure, the report is divided into three levels of hierarchy:
- System area: Used by all kernels, pipes, interconnects, and board logic.
- Kernel area: Used by a specific kernel, including resources by the logic inside the kernel, as well as resources used by local memories in the kernel and the workgroup dispatch logic that is detecting when it can send new workgroups into the kernel.
- Block area: Used by a specific block within a kernel. A block represents a branch-free section of your source code (for example, a loop body). To view the area, use information from the source code lines associated with a block and expand the report entry for that block.
Each line in the table is a sum of the resources used by itself and all of it's children.
Area Estimates Report Hierarchy
NOTE:
The area use data are estimates that the Intel® oneAPI DPC++/C++ Compiler generates. These estimates might differ from the final area utilization results.
Messages in the Area Estimates Report
After you compile your DPC++ application, review the Area Estimates report that the Intel® oneAPI DPC++/C++ Compiler generates. In addition to summarizing the application’s resource use, the Area Estimates report offers suggestions on modifying your design to improve efficiency. Refer to the following sections that describe various messages reported in the Area Estimates report.
Board InterfaceThe Area Estimates report identifies the amount of logic that the Intel® oneAPI DPC++/C++ Compiler generates for the Custom Platform or board interface. The board interface is the static region of the device that facilitates communication with external interfaces such as PCIe®. The Custom Platform specifies the size of the board interface.
Function Overhead
The Area Estimates report identifies the amount of logic that the Intel® oneAPI DPC++/C++ Compiler generates for dispatching kernels.
State
The Area Estimates report identifies the number of resources your design uses for live values and control logic. To reduce the reported area consumption under State, modify your design as follows:
- Decrease the size of local variables.
- Decrease the scope of local variables by localizing them whenever possible.
- Decrease the number of nested loops in the kernel.
Feedback
The Area Estimates report specifies the resources that your design uses for loop-carried dependencies.
To reduce the reported area consumption under Feedback, decrease the number and size of loop-carried variables in your design.
Messages for Private Variable Storage
The Area Estimates report provides information on the implementation of private memory based on your DPC++ design. For single work-item kernels, the Intel® oneAPI DPC++/C++ Compiler implements private memory differently, depending on the types of variable. The Intel® oneAPI DPC++/C++ Compiler implements scalars and small arrays in registers of various configurations (for example, plain registers, shift registers, and barrel shifter). The Intel® oneAPI DPC++/C++ Compiler implements larger arrays in block RAM.
The following table lists messages and notes of different private variable storage types:
Message |
Notes |
|---|---|
Implementation of Private Memory Using On-Chip Block RAM |
|
Private memory implemented in on-chip block RAM. |
The block RAM implementation creates a system that is similar to local memory for NDRange kernels. |
Implementation of Private Memory Using On-Chip Block ROM |
|
— |
For each use of an on-chip block ROM, the Intel® oneAPI DPC++/C++ Compiler creates another instance of the same ROM. There is no explicit annotation for private variables that the Intel® oneAPI DPC++/C++ Compiler implements in on-chip block ROM. |
Implementation of Private Memory Using Registers |
|
Implemented using registers of the following size:
|
Reports that the Intel® oneAPI DPC++/C++ Compiler implements a private variable in registers. The Intel® oneAPI DPC++/C++ Compiler might implement a private variable in many registers. This message provides a list of the registers with their specific widths and depths. |
Implementation of Private Memory Using Shift Registers |
|
Implemented as a shift register with <N> or fewer tap points. This is a very efficient storage type. Implemented using registers of the following sizes:
|
Reports that the Intel® oneAPI DPC++/C++ Compiler implements a private variable in shift registers. This message provides a list of shift registers with their specific widths and depths. The Intel® oneAPI DPC++/C++ Compiler might break a single array into several smaller shift registers depending on its tap points.
NOTE:
The compiler might overestimate the number of tap points. |
Implementation of Private Memory Using Barrel Shifters with Registers |
|
Implemented as a barrel shifter with registers due to dynamic indexing. This is a high overhead storage type. If possible, change to compile-time known indexing. The area cost of accessing this variable is shown on the lines where the accesses occur. Implemented using registers of the following size:
|
Reports that the Intel® oneAPI DPC++/C++ Compiler implements a private variable in a barrel shifter with registers because of dynamic indexing. This row in the report does not specify the full area use of the private variable. The report shows additional area use information on the lines where the variable is accessed. |
NOTE:
- The Area Estimates report annotates memory information on the line of code that declares or uses private memory, depending on its implementation.
- When the Intel® oneAPI DPC++/C++ Compiler implements private memory in on-chip block RAM, the Area Estimates report displays relevant local-memory-specific messages to private memory systems.
Parent topic: Review the FPGA Optimization Report