Visible to Intel only — GUID: GUID-A9C3B12F-7A9A-4C8D-A6CD-9974ABC570E9
Create a New Project
Use the Intel® C++ Compiler Classic
Select the Compiler Version
Specify a Base Platform Toolset
Use Property Pages
Use Intel® Libraries with Microsoft Visual Studio*
Include MPI Support
Use Guided Auto Parallelism in Microsoft Visual Studio*
Use Code Coverage in Microsoft Visual Studio*
Use Profile Guided Optimization in Microsoft Visual Studio*
Optimization Reports
Dialog Box Help
Options: Compilers dialog box
Use Intel® C++ Compiler Classic dialog box
Options: Intel Libraries for oneAPI dialog box
Options: Converter dialog box
Options: Optimization Reports dialog box
Options: Guided Auto Parallelism dialog box
Configure Analysis dialog box
Options: Profile Guided Optimization (PGO) dialog box
Profile Guided Optimization dialog box
Options: Code Coverage dialog box
Code Coverage dialog box
Code Coverage Settings dialog box
Alphabetical Option List
General Rules for Compiler Options
What Appears in the Compiler Option Descriptions
Optimization Options
Code Generation Options
Interprocedural Optimization Options
Advanced Optimization Options
Profile Guided Optimization Options
Optimization Report Options
OpenMP* Options and Parallel Processing Options
Floating-Point Options
Inlining Options
Output, Debug, and Precompiled Header Options
Preprocessor Options
Component Control Options
Language Options
Data Options
Compiler Diagnostic Options
Compatibility Options
Linking or Linker Options
Miscellaneous Options
Deprecated and Removed Compiler Options
Display Option Information
Alternate Compiler Options
Portability and GCC-Compatible Warning Options
arch
ax, Qax
EH
fasynchronous-unwind-tables
fcf-protection, Qcf-protection
fdata-sections, Gw
fexceptions
ffunction-sections, Gy
fomit-frame-pointer, Oy
Gd
Gr
GR
guard
Gv
Gz
hotpatch
m
m32, m64, Qm32, Qm64
m80387
march
masm
mauto-arch, Qauto-arch
mbranches-within-32B-boundaries, Qbranches-within-32B-boundaries
mconditional-branch, Qconditional-branch
minstruction, Qinstruction
momit-leaf-frame-pointer
mregparm
mregparm-version
mstringop-inline-threshold, Qstringop-inline-threshold
mstringop-strategy, Qstringop-strategy
mtune, tune
Qcxx-features
Qpatchable-addresses
Qsafeseh
regcall, Qregcall
x, Qx
xHost, QxHost
alias-const, Qalias-const
ansi-alias, Qansi-alias
ansi-alias-check, Qansi-alias-check
complex-limited-range, Qcomplex-limited-range
fargument-alias, Qalias-args
fargument-noalias-global
ffreestanding, Qfreestanding
fjump-tables
ftls-model
funroll-all-loops
guide, Qguide
guide-data-trans, Qguide-data-trans
guide-file, Qguide-file
guide-file-append, Qguide-file-append
guide-opts, Qguide-opts
guide-par, Qguide-par
guide-vec, Qguide-vec
ipp-link, Qipp-link
qdaal, Qdaal
qipp, Qipp
qmkl, Qmkl
qmkl-ilp64, Qmkl-ilp64
qopt-args-in-regs, Qopt-args-in-regs
qopt-assume-no-loop-carried-dep, Qopt-assume-no-loop-carried-dep
qopt-assume-safe-padding, Qopt-assume-safe-padding
qopt-block-factor, Qopt-block-factor
qopt-calloc
qopt-class-analysis, Qopt-class-analysis
qopt-dynamic-align, Qopt-dynamic-align
qopt-jump-tables, Qopt-jump-tables
qopt-malloc-options
qopt-matmul, Qopt-matmul
qopt-mem-layout-trans, Qopt-mem-layout-trans
qopt-multi-version-aggressive, Qopt-multi-version-aggressive
qopt-multiple-gather-scatter-by-shuffles, Qopt-multiple-gather-scatter-by-shuffles
qopt-prefetch, Qopt-prefetch
qopt-prefetch-distance, Qopt-prefetch-distance
qopt-prefetch-issue-excl-hint, Qopt-prefetch-issue-excl-hint
qopt-ra-region-strategy, Qopt-ra-region-strategy
qopt-streaming-stores, Qopt-streaming-stores
qopt-subscript-in-range, Qopt-subscript-in-range
qopt-zmm-usage, Qopt-zmm-usage
qoverride-limits, Qoverride-limits
qtbb, Qtbb
Qvla
scalar-rep, Qscalar-rep
simd, Qsimd
simd-function-pointers, Qsimd-function-pointers
unroll, Qunroll
unroll-aggressive, Qunroll-aggressive
use-intel-optimized-headers, Quse-intel-optimized-headers
vec, Qvec
vec-guard-write, Qvec-guard-write
vec-threshold, Qvec-threshold
vecabi, Qvecabi
finstrument-functions, Qinstrument-functions
fnsplit, Qfnsplit
Gh
GH
p
prof-data-order, Qprof-data-order
prof-dir, Qprof-dir
prof-file, Qprof-file
prof-func-groups
prof-func-order, Qprof-func-order
prof-gen, Qprof-gen
prof-hotness-threshold, Qprof-hotness-threshold
prof-src-dir, Qprof-src-dir
prof-src-root, Qprof-src-root
prof-src-root-cwd, Qprof-src-root-cwd
prof-use, Qprof-use
prof-value-profiling, Qprof-value-profiling
Qcov-dir
Qcov-file
Qcov-gen
qopt-report, Qopt-report
qopt-report-annotate, Qopt-report-annotate
qopt-report-annotate-position, Qopt-report-annotate-position
qopt-report-embed, Qopt-report-embed
qopt-report-file, Qopt-report-file
qopt-report-filter, Qopt-report-filter
qopt-report-format, Qopt-report-format
qopt-report-help, Qopt-report-help
qopt-report-names, Qopt-report-names
qopt-report-per-object, Qopt-report-per-object
qopt-report-phase, Qopt-report-phase
qopt-report-routine, Qopt-report-routine
device-math-lib
fmpc-privatize
fopenmp-device-lib
par-affinity, Qpar-affinity
par-loops, Qpar-loops
par-num-threads, Qpar-num-threads
par-runtime-control, Qpar-runtime-control
par-schedule, Qpar-schedule
par-threshold, Qpar-threshold
parallel, Qparallel
parallel-source-info, Qparallel-source-info
qopenmp, Qopenmp
qopenmp-lib, Qopenmp-lib
qopenmp-link
qopenmp-simd, Qopenmp-simd
qopenmp-stubs, Qopenmp-stubs
qopenmp-threadprivate, Qopenmp-threadprivate
Qpar-adjust-stack
fast-transcendentals, Qfast-transcendentals
fimf-absolute-error, Qimf-absolute-error
fimf-accuracy-bits, Qimf-accuracy-bits
fimf-arch-consistency, Qimf-arch-consistency
fimf-domain-exclusion, Qimf-domain-exclusion
fimf-force-dynamic-target, Qimf-force-dynamic-target
fimf-max-error, Qimf-max-error
fimf-precision, Qimf-precision
fimf-use-svml, Qimf-use-svml
fma, Qfma
fp-model, fp
fp-port, Qfp-port
fp-speculation, Qfp-speculation
fp-stack-check, Qfp-stack-check
fp-trap, Qfp-trap
fp-trap-all, Qfp-trap-all
ftz, Qftz
Ge
mp1, Qprec
pc, Qpc
prec-div, Qprec-div
prec-sqrt, Qprec-sqrt
qsimd-honor-fp-model, Qsimd-honor-fp-model
qsimd-serialize-fp-reduction, Qsimd-serialize-fp-reduction
rcd, Qrcd
fgnu89-inline
finline
finline-functions
finline-limit
inline-calloc, Qinline-calloc
inline-factor, Qinline-factor
inline-forceinline, Qinline-forceinline
inline-level, Ob
inline-max-per-compile, Qinline-max-per-compile
inline-max-per-routine, Qinline-max-per-routine
inline-max-size, Qinline-max-size
inline-max-total-size, Qinline-max-total-size
inline-min-caller-growth, Qinline-min-caller-growth
inline-min-size, Qinline-min-size
Qinline-dllimport
c
debug (Linux* and macOS)
debug (Windows*)
Fa
FA
fasm-blocks
FC
fcode-asm
Fd
FD
Fe
feliminate-unused-debug-types, Qeliminate-unused-debug-types
femit-class-debug-always
fmerge-constants
fmerge-debug-strings
Fo
Fp
FR
fsource-asm
ftrapuv, Qtrapuv
fverbose-asm
g
gdwarf
Gm
grecord-gcc-switches
gsplit-dwarf
map-opts, Qmap-opts
o
pch
pch-create
pch-dir
pch-use
pdbfile
print-multi-lib
Qpchi
Quse-msasm-symbols
RTC
S
use-asm, Quse-asm
use-msasm
V (Windows*)
Y-
Yc
Yd
Yu
Zi, Z7, ZI
Zo
ansi
check
early-template-check
fblocks
ffriend-injection
fno-gnu-keywords
fno-implicit-inline-templates
fno-implicit-templates
fno-operator-names
fno-rtti
fnon-lvalue-assign
fpermissive
fshort-enums
fsyntax-only
ftemplate-depth, Qtemplate-depth
funsigned-bitfields
funsigned-char
GZ
H (Windows*)
help-pragma, Qhelp-pragma
intel-extensions, Qintel-extensions
J
restrict, Qrestrict
std, Qstd
strict-ansi
vd
vmb
vmg
vmm
vms
x (type option)
Za
Zc
Ze
Zg
Zp
Zs
align
auto-ilp32, Qauto-ilp32
auto-p32
check-pointers, Qcheck-pointers
check-pointers-dangling, Qcheck-pointers-dangling
check-pointers-mpx, Qcheck-pointers-mpx
check-pointers-narrowing, Qcheck-pointers-narrowing
check-pointers-undimensioned, Qcheck-pointers-undimensioned
falign-functions, Qfnalign
falign-loops, Qalign-loops
falign-stack
fcommon
fextend-arguments, Qextend-arguments
fkeep-static-consts, Qkeep-static-consts
fmath-errno
fminshared
fmudflap
fpack-struct
fpascal-strings
fpic
fpie
freg-struct-return
fstack-protector
fstack-security-check
fvisibility
fvisibility-inlines-hidden
fzero-initialized-in-bss, Qzero-initialized-in-bss
GA
Gs
GS
GT
homeparams
malign-double
malign-mac68k
malign-natural
malign-power
mcmodel
mdynamic-no-pic
mlong-double
no-bss-init, Qnobss-init
noBool
Qlong-double
Qsfalign
diag, Qdiag
diag-dump, Qdiag-dump
diag-enable=power, Qdiag-enable:power
diag-error-limit, Qdiag-error-limit
diag-file, Qdiag-file
diag-file-append, Qdiag-file-append
diag-id-numbers, Qdiag-id-numbers
diag-once, Qdiag-once
fnon-call-exceptions
traceback
w
w, W
Wabi
Wall
Wbrief
Wcheck
Wcheck-unicode-security
Wcomment
Wcontext-limit, Qcontext-limit
wd, Qwd
Wdeprecated
we, Qwe
Weffc++, Qeffc++
Werror, WX
Werror-all
Wextra-tokens
Wformat
Wformat-security
Wic-pointer
Winline
WL
Wmain
Wmissing-declarations
Wmissing-prototypes
wn, Qwn
Wnon-virtual-dtor
wo, Qwo
Wp64
Wpch-messages
Wpointer-arith
Wport
wr, Qwr
Wremarks
Wreorder
Wreturn-type
Wshadow
Wsign-compare
Wstrict-aliasing
Wstrict-prototypes
Wtrigraphs
Wuninitialized
Wunknown-pragmas
Wunused-function
Wunused-variable
ww, Qww
Wwrite-strings
Bdynamic
Bstatic
Bsymbolic
Bsymbolic-functions
cxxlib
dynamic-linker
dynamiclib
F (Windows*)
F (macOS)
fixed
Fm
fuse-ld
l
L
LD
link
MD
MT
no-libgcc
nodefaultlibs
no-intel-lib, Qno-intel-lib
nostartfiles
nostdlib
pie
pthread
shared
shared-intel
shared-libgcc
static
static-intel
static-libgcc
static-libstdc++
staticlib
T
u (Linux*)
v
Wa
Wl
Wp
Xlinker
Zl
Details about Intrinsics
Naming and Usage Syntax
References
Intrinsics for All Intel® Architectures
Data Alignment, Memory Allocation Intrinsics, and Inline Assembly
Intrinsics for Managing Extended Processor States and Registers
Intrinsics for the Short Vector Random Number Generator Library
Intrinsics for Instruction Set Architecture (ISA) Instructions
Intrinsics for Intel® Advanced Matrix Extensions (Intel(R) AMX) Instructions
Intrinsics for Intel® Advanced Vector Extensions 512 (Intel® AVX-512) BF16 Instructions
Intrinsics for Intel® Advanced Vector Extensions 512 (Intel® AVX-512) 4VNNIW Instructions
Intrinsics for Intel® Advanced Vector Extensions 512 (Intel® AVX-512) 4FMAPS Instructions
Intrinsics for Intel® Advanced Vector Extensions 512 (Intel® AVX-512) VPOPCNTDQ Instructions
Intrinsics for Intel® Advanced Vector Extensions 512 (Intel® AVX-512) Additional Instructions
Intrinsics for Intel® Advanced Vector Extensions 512 (Intel® AVX-512) Instructions
Intrinsics for Later Generation Intel® Core™ Processor Instruction Extensions
Intrinsics for Intel® Advanced Vector Extensions 2 (Intel® AVX2)
Intrinsics for Intel® Advanced Vector Extensions
Intrinsics for Intel® Streaming SIMD Extensions 4 (Intel® SSE4)
Intrinsics for Intel® Supplemental Streaming SIMD Extensions 3 (SSSE3)
Intrinsics for Intel® Streaming SIMD Extensions 3 (Intel® SSE3)
Intrinsics for Intel® Streaming SIMD Extensions 2 (Intel® SSE2)
Intrinsics for Intel® Streaming SIMD Extensions (Intel® SSE)
Intrinsics for MMX™ Technology
Intrinsics for Advanced Encryption Standard Implementation
Intrinsics for Converting Half Floats
Intrinsics for Short Vector Math Library Operations (SVML)
Intrinsics for Arithmetic Operations
Intrinsics for Bit Manipulation Operations
Intrinsics for Comparison Operations
Intrinsics for Conversion Operations
Intrinsics for Load Operations
Intrinsics for Logical Operations
Intrinsics for Miscellaneous Operations
Intrinsics for Move Operations
Intrinsics for Set Operations
Intrinsics for Shift Operations
Intrinsics for Store Operations
Intrinsics for Arithmetic Operations
Intrinsics for Blend Operations
Intrinsics for Bit Manipulation Operations
Intrinsics for Broadcast Operations
Intrinsics for Comparison Operations
Intrinsics for Compression Operations
Intrinsics for Conversion Operations
Intrinsics for Expand and Load Operations
Intrinsics for Gather and Scatter Operations
Intrinsics for Insert and Extract Operations
Intrinsics for Load and Store Operations
Intrinsics for Miscellaneous Operations
Intrinsics for Move Operations
Intrinsics for Pack and Unpack Operations
Intrinsics for Permutation Operations
Intrinsics for Reduction Operations
Intrinsics for Set Operations
Intrinsics for Shuffle Operations
Intrinsics for Test Operations
Intrinsics for Typecast Operations
Intrinsics for Vector Mask Operations
Intrinsics for 3rd Generation Intel® Core™ Processor Instruction Extensions
Intrinsics for 4th Generation Intel® Core™ Processor Instruction Extensions
Intrinsics for Converting Half Floats that Map to 3rd Generation Intel® Core™ Processor Instructions
Intrinsics that Generate Random Numbers of 16/32/64 Bit Wide Random Integers
Intrinsics for Multi-Precision Arithmetic
Intrinsics that Allow Reading from and Writing to the FS Base and GS Base Registers
Intrinsics for Arithmetic Operations
Intrinsics for Arithmetic Shift Operations
Intrinsics for Blend Operations
Intrinsics for Bitwise Operations
Intrinsics for Broadcast Operations
Intrinsics for Compare Operations
Intrinsics for Fused Multiply Add Operations
Intrinsics for GATHER Operations
Intrinsics for Logical Shift Operations
Intrinsics for Insert/Extract Operations
Intrinsics for Masked Load/Store Operations
Intrinsics for Miscellaneous Operations
Intrinsics for Operations to Manipulate Integer Data at Bit-Granularity
Intrinsics for Pack/Unpack Operations
Intrinsics for Packed Move with Extend Operations
Intrinsics for Permute Operations
Intrinsics for Shuffle Operations
Intrinsics for Intel® Transactional Synchronization Extensions (Intel® TSX)
_mm256_abs_epi8/16/32
_mm256_add_epi8/16/32/64
_mm256_adds_epi8/16
_mm256_adds_epu8/16
_mm256_sub_epi8/16/32/64
_mm256_subs_epi8/16
_mm256_subs_epu8/16
_mm256_avg_epu8/16
_mm256_hadd_epi16/32
_mm256_hadds_epi16
_mm256_hsub_epi16/32
_mm256_hsubs_epi16
_mm256_madd_epi16
_mm256_maddubs_epi16
_mm256_mul_epi32
_mm256_mul_epu32
_mm256_mulhi_epi16
_mm256_mulhi_epu16
_mm256_mullo_epi16/32
_mm256_mulhrs_epi16
_mm256_sign_epi8/16/32
_mm256_mpsadbw_epu8
_mm256_sad_epu8
_mm_fmadd_pd, _mm256_fmadd_pd
_mm_fmadd_ps, _mm256_fmadd_ps
_mm_fmadd_sd
_mm_fmadd_ss
_mm_fmaddsub_pd, _mm256_fmaddsub_pd
_mm_fmaddsub_ps, _mm256_fmaddsub_ps
_mm_fmsub_pd, _mm256_fmsub_pd
_mm_fmsub_ps, _mm256_fmsub_ps
_mm_fmsub_sd
_mm_fmsub_ss
_mm_fmsubadd_pd, _mm256_fmsubadd_pd
_mm_fmsubadd_ps, _mm256_fmsubadd_ps
_mm_fnmadd_pd, _mm256_fnmadd_pd
_mm_fnmadd_ps, _mm256_fnmadd_ps
_mm_fnmadd_sd
_mm_fnmadd_ss
_mm_fnmsub_pd, _mm256_fnmsub_pd
_mm_fnmsub_ps, _mm256_fnmsub_ps
_mm_fnmsub_sd
_mm_fnmsub_ss
_mm_mask_i32gather_pd, _mm256_mask_i32gather_pd
_mm_i32gather_pd, _mm256_i32gather_pd
_mm_mask_i64gather_pd, _mm256_mask_i64gather_pd
_mm_i64gather_pd, _mm256_i64gather_pd
_mm_mask_i32gather_ps, _mm256_mask_i32gather_ps
_mm_i32gather_ps, _mm256_i32gather_ps
_mm_mask_i64gather_ps, _mm256_mask_i64gather_ps
_mm_i64gather_ps, _mm256_i64gather_ps
_mm_mask_i32gather_epi32, _mm256_mask_i32gather_epi32
_mm_i32gather_epi32, _mm256_i32gather_epi32
_mm_mask_i32gather_epi64,_mm256_mask_i32gather_epi64
_mm_i32gather_epi64,_mm256_i32gather_epi64
_mm_mask_i64gather_epi32,_mm256_mask_i64gather_epi32
_mm_i64gather_epi32,_mm256_i64gather_epi32
_mm_mask_i64gather_epi64,_mm256_mask_i64gather_epi64
_mm_i64gather_epi64,_mm256_i64gather_epi64
Intel® Transactional Synchronization Extensions (Intel® TSX) Overview
Intel® Transactional Synchronization Extensions (Intel® TSX) Programming Considerations
Intrinsics for Restricted Transactional Memory Operations
Intrinsics for Hardware Lock Elision Operations
Function Prototype and Macro Definitions
Details of Intel® Advanced Vector Extensions Intrinsics
Intel® Advanced Vector Extensions Registers
Intel® Advanced Vector Extensions Types
VEX Prefix Instruction Encoding Support for Intel® AVX
Naming and Usage Syntax
Intrinsics for Arithmetic Operations
Intrinsics for Bitwise Operations
Intrinsics for Blend and Conditional Merge Operations
Intrinsics for Compare Operations
Intrinsics for Conversion Operations
Intrinsics to Determine Minimum and Maximum Values
Intrinsics for Load and Store Operations
Intrinsics for Miscellaneous Operations
Intrinsics for Packed Test Operations
Intrinsics for Permute Operations
Intrinsics for Shuffle Operations
Intrinsics for Unpack and Interleave Operations
Support Intrinsics for Vector Typecasting Operations
Intrinsics Generating Vectors of Undefined Values
_mm256_broadcast_pd
_mm256_broadcast_ps
_mm256_broadcast_sd
_mm256_broadcast_ss, _mm_broadcast_ss
_mm256_load_pd
_mm256_load_ps
_mm256_load_si256
_mm256_loadu_pd
_mm256_loadu_ps
_mm256_loadu_si256
_mm256_maskload_pd, _mm_maskload_pd
_mm256_maskload_ps, _mm_maskload_ps
_mm256_store_pd
_mm256_store_ps
_mm256_store_si256
_mm256_storeu_pd
_mm256_storeu_ps
_mm256_storeu_si256
_mm256_stream_pd
_mm256_stream_ps
_mm256_stream_si256
_mm256_maskstore_pd, _mm_maskstore_pd
_mm256_maskstore_ps, _mm_maskstore_ps
_mm256_extractf128_pd
_mm256_extractf128_ps
_mm256_extractf128_si256
_mm256_insertf128_pd
_mm256_insertf128_ps
_mm256_insertf128_si256
_mm256_lddqu_si256
_mm256_movedup_pd
_mm256_movehdup_ps
_mm256_moveldup_ps
_mm256_movemask_pd
_mm256_movemask_ps
_mm256_round_pd
_mm256_round_ps
_mm256_set_pd
_mm256_set_ps
_mm256_set_epi8/16/32/64x
_mm256_setr_pd
_mm256_setr_ps
_mm256_setr_epi32
_mm256_set1_pd
_mm256_set1_ps
_mm256_set1_epi32
_mm256_setzero_pd
_mm256_setzero_ps
_mm256_setzero_si256
_mm256_zeroall
_mm256_zeroupper
Overview: Vectorizing Compiler and Media Accelerators
Packed Blending Intrinsics
Floating Point Dot Product Intrinsics
Packed Format Conversion Intrinsics
Packed Integer Min/Max Intrinsics
Floating Point Rounding Intrinsics
DWORD Multiply Intrinsics
Register Insertion/Extraction Intrinsics
Test Intrinsics
Packed DWORD to Unsigned WORD Intrinsic
Packed Compare for Equal Intrinsic
Cacheability Support Intrinsic
Details about Intel® Streaming SIMD Extensions Intrinsics
Writing Programs with Intel® Streaming SIMD Extensions (Intel® SSE) Intrinsics
Arithmetic Intrinsics
Logical Intrinsics
Compare Intrinsics
Conversion Intrinsics
Load Intrinsics
Set Intrinsics
Store Intrinsics
Cacheability Support Intrinsics
Integer Intrinsics
Intrinsics to Read and Write Registers
Miscellaneous Intrinsics
Macro Functions
Details about MMX™ Technology Intrinsics
The EMMS Instruction: Why You Need It
EMMS Usage Guidelines
General Support Intrinsics (MMX™ technology)
Packed Arithmetic Intrinsics (MMX™ technology)
Shift Intrinsics (MMX™ technology)
Logical Intrinsics (MMX™ technology)
Compare Intrinsics (MMX™ technology)
Set Intrinsics (MMX™ technology)
Intrinsics for Division Operations (512-bit)
Intrinsics for Division Operations
Intrinsics for Error Function Operations (512-bit)
Intrinsics for Error Function Operations
Intrinsics for Exponential Operations (512-bit)
Intrinsics for Exponential Operations
Intrinsics for Logarithmic Operations (512-bit)
Intrinsics for Logarithmic Operations
Intrinsics for Reciprocal Operations (512-bit)
Intrinsics for Root Function Operations (512-bit)
Intrinsics for Rounding Operations (512-bit)
Intrinsics for Square Root and Cube Root Operations
Intrinsics for Trigonometric Operations (512-bit)
Intrinsics for Trigonometric Operations
_mm_div_epi8/ _mm256_div_epi8
_mm_div_epi16/ _mm256_div_epi16
_mm_div_epi32/ _mm256_div_epi32
_mm_div_epi64/ _mm256_div_epi64
_mm_div_epu8/ _mm256_div_epu8
_mm_div_epu16/ _mm256_div_epu16
_mm_div_epu32/ _mm256_div_epu32
_mm_div_epu64/ _mm256_div_epu64
_mm_rem_epi8/ _mm256_rem_epi8
_mm_rem_epi16/ _mm256_rem_epi16
_mm_rem_epi32/ _mm256_rem_epi32
_mm_rem_epi64/ _mm256_rem_epi64
_mm_rem_epu8/ _mm256_rem_epu8
_mm_rem_epu16/ _mm256_rem_epu16
_mm_rem_epu32/ _mm256_rem_epu32
_mm_rem_epu64/ _mm256_rem_epu64
_mm_exp2_pd, _mm256_exp2_pd
_mm_exp2_ps, _mm256_exp2_ps
_mm_exp_pd, _mm256_exp_pd
_mm_exp_ps, _mm256_exp_ps
_mm_exp10_pd, _mm256_exp10_pd
_mm_exp10_ps, _mm256_exp10_ps
_mm_expm1_pd, _mm256_expm1_pd
_mm_expm1_ps, _mm256_expm1_ps
_mm_cexp_ps, _mm256_cexp_ps
_mm_pow_pd, _mm256_pow_pd
_mm_pow_ps, _mm256_pow_ps
_mm_hypot_pd, _mm256_hypot_pd
_mm_hypot_ps, _mm256_hypot_ps
_mm_log2_pd, _mm256_log2_pd
_mm_log2_ps, _mm256_log2_ps
_mm_log10_pd, _mm256_log10_pd
_mm_log10_ps, _mm256_log10_ps
_mm_log_pd, _mm256_log_pd
_mm_log_ps, _mm256_log_ps
_mm_logb_pd, _mm256_logb_pd
_mm_logb_ps, _mm256_logb_ps
_mm_log1p_pd, _mm256_log1p_pd
_mm_log1p_ps, _mm256_log1p_ps
_mm_clog_ps, _mm256_clog_ps
_mm_acos_pd, _mm256_acos_pd
_mm_acos_ps, _mm256_acos_ps
_mm_acosh_pd, _mm256_acosh_pd
_mm_acosh_ps, _mm256_acosh_ps
_mm_asin_pd, _mm256_asin_pd
_mm_asin_ps, _mm256_asin_ps
_mm_asinh_pd, _mm256_asinh_pd
_mm_asinh_ps, _mm256_asinh_ps
_mm_atan_pd, _mm256_atan_pd
_mm_atan_ps, _mm256_atan_ps
_mm_atan2_pd, _mm256_atan2_pd
_mm_atan2_ps, _mm256_atan2_ps
_mm_atanh_pd, _mm256_atanh_pd
_mm_atanh_ps, _mm256_atanh_ps
_mm_cos_pd, _mm256_cos_pd
_mm_cos_ps, _mm256_cos_ps
_mm_cosd_pd, _mm256_cosd_pd
_mm_cosd_ps, _mm256_cosd_ps
_mm_cosh_pd, _mm256_cosh_pd
_mm_cosh_ps, _mm256_cosh_ps
_mm_sin_pd, _mm256_sin_pd
_mm_sin_ps, _mm256_sin_ps
_mm_sind_pd, _mm256_sind_pd
_mm_sind_ps, _mm256_sind_ps
_mm_sinh_pd, _mm256_sinh_pd
_mm_sinh_ps, _mm256_sinh_ps
_mm_tan_pd, _mm256_tan_pd
_mm_tan_ps, _mm256_tan_ps
_mm_tand_pd, _mm256_tand_pd
_mm_tand_ps, _mm256_tand_ps
_mm_tanh_pd, _mm256_tanh_pd
_mm_tanh_ps, _mm256_tanh_ps
_mm_sincos_pd, _mm256_sincos_pd
_mm_sincos_ps, _mm256_sincos_ps
Create Libraries
Use Intel Shared Libraries
Using Shared Libraries on macOS
Manage Libraries
Redistribute Libraries When Deploying Applications
Resolve References to Shared Libraries
Intel's Memory Allocator Library
SIMD Data Layout Templates
Intel® C++ Class Libraries
Intel's C++ Asynchronous I/O Extensions for Windows
IEEE 754-2008 Binary Floating-Point Conformance Library
Intel's Numeric String Conversion Library
Terms and Syntax
Rules for Operators
Assignment Operator
Logical Operators
Addition and Subtraction Operators
Multiplication Operators
Shift Operators
Comparison Operators
Conditional Select Operators
Debug Operations
Unpack Operators
Pack Operators
Clear MMX™ State Operator
Integer Functions for Streaming SIMD Extensions
Conversions between Fvec and Ivec
Fvec Syntax and Notation
Data Alignment
Conversions
Constructors and Initialization
Arithmetic Operators
Minimum and Maximum Operators
Logical Operators
Compare Operators
Conditional Select Operators for Fvec Classes
Cacheability Support Operators
Debug Operations
Load and Store Operators
Unpack Operators
Move Mask Operators
aio_read
aio_write
Example for aio_read and aio_write Functions
aio_suspend
Example for aio_suspend Function
aio_error
aio_return
Example for aio_error and aio_return Functions
aio_fsync
aio_cancel
Example for aio_cancel Function
lio_listio
Example for lio_listio Function
Asynchronous I/O Function Errors
Intel® IEEE 754-2008 Binary Floating-Point Conformance Library and Usage
Function List
Homogeneous General-Computational Operations Functions
General-Computational Operations Functions
Quiet-Computational Operations Functions
Signaling-Computational Operations Functions
Non-Computational Operations Functions
alloc_section
block_loop/noblock_loop
code_align
distribute_point
inline, noinline, forceinline
intel omp task
intel omp taskq
ivdep
loop_count
nofusion
novector
omp simd early_exit
optimize
optimization_level
optimization_parameter
parallel/noparallel
prefetch/noprefetch
simd
simdoff
unroll/nounroll
unroll_and_jam/nounroll_and_jam
unused
vector
Compilation Overview
Supported Environment Variables
Pass Options to the Linker
Linking Tools and Options
Specify Alternate Tools and Paths
Use Configuration Files
Use Response Files
Global Symbols and Visibility Attributes for Linux* and macOS
Save Compiler Information in Your Executable
Link Debug Information
OpenMP* Support
Automatic Parallelization
Vectorization
Guided Auto Parallelism
Profile-Guided Optimization
High-Level Optimization (HLO)
Interprocedural Optimization
Processor Targeting
Methods to Optimize Code Size
Intel® C++ Compiler Classic Math Library
Automatically-Aligned Dynamic Allocation
Pointer Checker
GAP Message (Diagnostic ID 30506)
GAP Message (Diagnostic ID 30513)
GAP Message (Diagnostic ID 30515)
GAP Message (Diagnostic ID 30519)
GAP Message (Diagnostic ID 30521)
GAP Message (Diagnostic ID 30522)
GAP Message (Diagnostic ID 30523)
GAP Message (Diagnostic ID 30525)
GAP Message (Diagnostic ID 30526)
GAP Message (Diagnostic ID 30528)
GAP Message (Diagnostic ID 30531)
GAP Message (Diagnostic ID 30532)
GAP Message (Diagnostic ID 30533)
GAP Message (Diagnostic ID 30534)
GAP Message (Diagnostic ID 30535)
GAP Message (Diagnostic ID 30536)
GAP Message (Diagnostic ID 30537)
GAP Message (Diagnostic ID 30538)
GAP Message (Diagnostic ID 30753)
GAP Message (Diagnostic ID 30754)
GAP Message (Diagnostic ID 30755)
GAP Message (Diagnostic ID 30756)
GAP Message (Diagnostic ID 30757)
GAP Message (Diagnostic ID 30758)
GAP Message (Diagnostic ID 30759)
GAP Message (Diagnostic ID 30760)
Checking Bounds
Checking for Dangling Pointers
Checking Arrays
Working with Enabled and Non-Enabled Modules
Storing Bounds Information
Passing and Returning Bounds
Checking Runtime Library Functions
Writing a Wrapper
Checking Custom Memory Allocators
Checking Multi-Threaded Code
How the Compiler Defines Bounds Information for Pointers
Finding and Reporting Out-of-Bounds Errors
Visible to Intel only — GUID: GUID-A9C3B12F-7A9A-4C8D-A6CD-9974ABC570E9
Details of Intel® Advanced Vector Extensions Intrinsics
Intel® Advanced Vector Extensions (Intel® AVX) intrinsics map directly to Intel® AVX instructions and other enhanced 128-bit single-instruction multiple data processing (SIMD) instructions. Intel® AVX instructions are architecturally similar to extensions of the existing Intel® 64 architecture-based vector streaming SIMD portions of Intel® Streaming SIMD Extensions (Intel® SSE) instructions, and double-precision floating-point portions of Intel® Streaming SIMD Extensions 2 (Intel® SSE2) instructions. However, Intel® AVX introduces the following architectural enhancements:
- Support for 256-bit wide vectors and SIMD register set.
- Instruction syntax support three and four operand syntax, to improve instruction programming flexibility and efficiency for new instruction extensions.
- Enhancement of legacy 128-bit SIMD instruction extensions to support three-operand syntax and to simplify compiler vectorization of high-level language expressions.
- Instruction encoding format using a new prefix (referred to as VEX) to provide compact, efficient encoding for three-operand syntax, vector lengths, compaction of legacy SIMD prefixes and REX functionality.
- Intel® AVX data types allow packing of up to 32 elements in a register if bytes are used. The number of elements depends upon the element type: eight single-precision floating point types or four double-precision floating point types.
Intel® Advanced Vector Extensions Registers
Intel® AVX adds 16 registers (YMM0-YMM15), each 256 bits wide, aliased onto the 16 SIMD (XMM0-XMM15) registers. The Intel® AVX new instructions operate on the YMM registers. Intel® AVX extends certain existing instructions to operate on the YMM registers, defining a new way of encoding up to three sources and one destination in a single instruction.
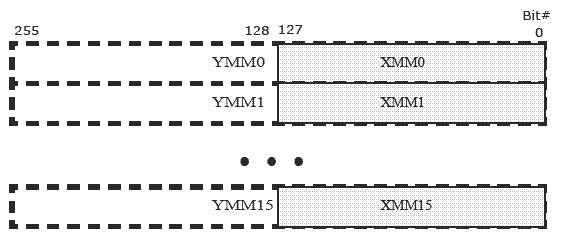
Because each of these registers can hold more than one data element, the processor can process more than one data element simultaneously. This processing capability is also known as single-instruction multiple data processing (SIMD).
For each computational and data manipulation instruction in the new extension sets, there is a corresponding C intrinsic that implements that instruction directly. This frees you from managing registers and assembly programming. Further, the compiler optimizes the instruction scheduling so that your executable runs faster.
Intel® Advanced Vector Extensions Types
The Intel® AVX intrinsic functions use three new C data types as operands, representing the new registers used as operands to the intrinsic functions. These are __m256, __m256d, and __m256i data types.
The __m256 data type is used to represent the contents of the extended SSE register, the YMM register, used by the Intel® AVX intrinsics. The __m256 data type can hold eight 32-bit floating-point values.
The __m256d data type can hold four 64-bit double precision floating-point values.
The __m256i data type can hold thirty-two 8-bit, sixteen 16-bit, eight 32-bit, or four 64-bit integer values.
The compiler aligns the __m256, __m256d, and __m256i local and global data to 32-byte boundaries on the stack. To align integer, float, or double arrays, use the __declspec(align) statement.
The Intel® AVX intrinsics also use Intel® SSE2 data types like __m128, __m128d, and __m128i for some operations. See Details of Intrinsics topic for more information.
VEX Prefix Instruction Encoding Support for Intel® AVX
Intel® AVX introduces a new prefix, referred to as VEX, in the Intel® 64 and IA-32 instruction encoding format. Instruction encoding using the VEX prefix provides several capabilities:
- direct encoding of a register operand within the VEX prefix.
- efficient encoding of instruction syntax operating on 128-bit and 256-bit register sets.
- compaction of REX prefix functionality.
- compaction of SIMD prefix functionality and escape byte encoding.
- providing relaxed memory alignment requirements for most VEX-encoded SIMD numeric and data processing instruction semantics with memory operand as compared to instructions encoded using SIMD prefixes.
The VEX prefix encoding applies to SIMD instructions operating on YMM registers, XMM registers, and in some cases with a general-purpose register as one of the operands. The VEX prefix is not supported for instructions operating on MMX™ or x87 registers.
It is recommended to use Intel® AVX intrinsics with option [Q]xAVX, because their corresponding instructions are encoded with the VEX-prefix. The [Q]xAVX option forces other packed instructions to be encoded with VEX too. As a result there are fewer performance stalls due to Intel® AVX to legacy Intel® SSE code transitions.
Naming and Usage Syntax
Most Intel® AVX intrinsic names use the following notational convention:
_mm256_<intrin_op>_<suffix>(<data type> <parameter1>, <data type> <parameter2>, <data type> <parameter3>)
The following table explains each item in the syntax.
| _mm256/_mm128 | Prefix representing the size of the result. Usually, this corresponds to the Intel® AVX vector register size of 256 bits, but certain comparison and conversion intrinsics yield a 128-bit result. |
| <intrin_op> | Indicates the basic operation of the intrinsic; for example, add for addition and sub for subtraction. |
| <suffix> | Denotes the type of data the instruction operates on. The first one or two letters of each suffix denote whether the data is packed (p), extended packed (ep), or scalar (s). The remaining letters and numbers denote the type, with notation as follows:
|
| <data type> | Parameter data types: __m256, __m256d, __m256i, __m128, __m128d, __m128i, const, int, etc. |
| <parameter1> | Represents a source vector register: m1/s1/a |
| <parameter2> | Represents another source vector register: m2/s2/b |
| <parameter3> | Represents an integer value: mask/select/offset The third parameter is an integer value whose bits represent a conditionality based on which the intrinsic performs an operation. |
Example Usage
extern __m256d _mm256_add_pd(__m256d m1, __m256d m2);where,
- add
- indicates that an addition operation must be performed
- pd
- indicates packed double-precision floating-point value
The packed values are represented in right-to-left order, with the lowest value used for scalar operations. Consider the following example operation:
double a[4] = {1.0, 2.0, 3.0, 4.0};
__m256d t = _mm256_load_pd(a);
The result is the following:
__m256d t = _mm256_set_pd(4.0, 3.0, 2.0, 1.0);
In other words, the YMM register that holds the value t appears as follows:

The " scalar " element is 1.0. Due to the nature of the instruction, some intrinsics require their arguments to be immediates (constant integer literals).
Parent topic: Intrinsics for Intel® Advanced Vector Extensions