Visible to Intel only — GUID: onu1619702466280
Ixiasoft
1. About the Video and Vision Processing Suite
2. Getting Started with the Video and Vision Processing IPs
3. Video and Vision Processing IPs Functional Description
4. Video and Vision Processing IP Interfaces
5. Video and Vision Processing IP Registers
6. Video and Vision Processing IPs Software Programming Model
7. Protocol Converter Intel® FPGA IP
8. 3D LUT Intel® FPGA IP
9. AXI-Stream Broadcaster Intel® FPGA IP
10. Bits per Color Sample Adapter Intel FPGA IP
11. Chroma Key Intel® FPGA IP
12. Chroma Resampler Intel® FPGA IP
13. Clipper Intel® FPGA IP
14. Clocked Video Input Intel® FPGA IP
15. Clocked Video to Full-Raster Converter Intel® FPGA IP
16. Clocked Video Output Intel® FPGA IP
17. Color Space Converter Intel® FPGA IP
18. Deinterlacer Intel® FPGA IP
19. FIR Filter Intel® FPGA IP
20. Frame Cleaner Intel® FPGA IP
21. Full-Raster to Clocked Video Converter Intel® FPGA IP
22. Full-Raster to Streaming Converter Intel® FPGA IP
23. Genlock Controller Intel® FPGA IP
24. Generic Crosspoint Intel® FPGA IP
25. Genlock Signal Router Intel® FPGA IP
26. Guard Bands Intel® FPGA IP
27. Interlacer Intel® FPGA IP
28. Mixer Intel® FPGA IP
29. Pixels in Parallel Converter Intel® FPGA IP
30. Scaler Intel® FPGA IP
31. Stream Cleaner Intel® FPGA IP
32. Switch Intel® FPGA IP
33. Tone Mapping Operator Intel® FPGA IP
34. Test Pattern Generator Intel® FPGA IP
35. Video and Vision Monitor Intel FPGA IP
36. Video Frame Buffer Intel® FPGA IP
37. Video Frame Reader Intel FPGA IP
38. Video Frame Writer Intel FPGA IP
39. Video Streaming FIFO Intel® FPGA IP
40. Video Timing Generator Intel® FPGA IP
41. Warp Intel® FPGA IP
42. Design Security
43. Document Revision History for Video and Vision Processing Suite User Guide
23.4.1. Achieving Genlock Controller Free Running (for Initialization or from Lock to Reference Clock N)
23.4.2. Locking to Reference Clock N (from Genlock Controller IP free running)
23.4.3. Setting the VCXO hold over
23.4.4. Restarting the Genlock Controller IP
23.4.5. Locking to Reference Clock N New (from Locking to Reference Clock N Old)
23.4.6. Changing to Reference Clock or VCXO Base Frequencies (switch between p50 and p59.94 video formats and vice-versa)
23.4.7. Disturbing a Reference Clock (a cable pull)
41.3.1. Block Cache Tool
41.3.2. Warp IP Interfaces
41.3.3. Warp IP Latency
41.3.4. External Memory for Warp IP
Memory Space Allocation in External Memory
Bandwidth to External Memory
Total Warp IP Memory Traffic
Peak Memory Bandwidth Approximation for Video Streams
Peak Memory Bandwidth Approximation for Coefficient Streams
Peak Memory Bandwidth Approximation for Cache Loads
Memory Interface Bandwidth Requirements
Example system sharing access to memory
Multiple Warp IPs sharing access to memory
Visible to Intel only — GUID: onu1619702466280
Ixiasoft
41.3.4. External Memory for Warp IP
The IP requires access to two separate areas of external memory: one for its input and output video buffers and one for its coefficient tables. The processor system running the Warp Software API must be able to access the coefficient tables but does not need access to the buffer area.
Memory Space Allocation in External Memory
| Buffer Space Configuration | Region Size (MB) | Memory Region Required | Alignment (multiples of) |
|---|---|---|---|
| SD buffer size (1024x1024) | 24 | 0x0180_0000 | 0x0200_0000 |
| HD buffer size (2048x2048) | 96 | 0x0600_0000 | 0x0800_0000 |
| UHD buffer size (4096x4096) | 384 | 0x1800_0000 | 0x2000_0000 |
| Buffer Space Configuration | Region Size (MB) | Memory Region Required | Alignment (multiples of) |
|---|---|---|---|
| SD buffer size (1024x1024) | 16 | 0x0100_0000 | 0x0100_0000 |
| HD buffer size (2048x2048) | 64 | 0x0400_0000 | 0x0400_0000 |
| UHD buffer size (4096x4096) | 256 | 0x1000_0000 | 0x1000_0000 |
The IP passes the base address of the memory region allocated to the frame buffers to the software API using the ram_addr element in the structure.
The memory region that the coefficient tables require is related to the number of warp engines, the resolution of the images, and the type of warp. The IP only requires this memory region when you turn off Use easy warp.
| Warp Engines | Region Size (MB) | Memory Region Required | Alignment (multiples of) |
|---|---|---|---|
| 1 | 16 | 0x0100_0000 | 0x0100_0000 |
| 2 | 32 | 0x0200_0000 | 0x0200_0000 |
Bandwidth to External Memory
The performance of the interface from the Warp IP to the external memory is important for the correct operation of a system using the Warp IP.
The Warp IP generates a substantial amount of memory traffic. It has up to four video streams passing to and from external memory. In addition, each engine has three read streams to access the coefficient tables. All these streams combine to make Warp IP memory accesses complex. The streams affect how much efficiency you can obtain when accessing memory such as DDR4.
The Warp IP memory controller mitigates potential inefficiencies caused by these complex access patterns. It uses burst lengths of 8 beats for all its read and write accesses to improve the burst performance of DDR4 memory. It also attempts to cluster individual read and write bursts together to eliminate some of the issues with read and write turnaround dead time at the DDR4 interface.
These memory access patterns depend on the image transform that you apply. Some complex image transforms may reduce memory traffic because of the skip region functionality. When Use single memory bounce is off, one of the worst transforms for generated memory traffic is a unity warp that gives a 1:1 mapping between input and output pixels. When Use single memory bounce is on, memory traffic is proportional to the amount of compression in the vertical direction of the transform. The higher the amount of compression in the transform vertically, the higher the memory bandwidth.
The operation of the Warp IP is easier to predict when it is the only user of the DDR4 memory in a system. Ensure the Warp IP is the only high bandwidth user of the DDR4 memory in a system. When other high bandwidth accesses are made to the memory at the same time as the Warp IP, ensure that any interactions don’t adversely affect performance.
Total Warp IP Memory Traffic
Three different configurations of the warp IP affect the way it connects to the external memory and hence affect the total memory traffic:
- When Use easy warp is on
- Use easy warp is off and Use single memory bounce is either on or off.
Figure 106. External Memory Data Streams
The figure shows a schematic view of all the possible data streams the IP uses. Depending on the settings of Use easy warp and Use single memory bounce, the IP does not require all of these streams.
| Data Stream | Use easy warp on | Use single memory bounce on | Use single memory bounce off |
|---|---|---|---|
| Input video | Active | Active | Active |
| Cache loads | Active | Active | |
| Warped image | Active | ||
| Coefficient reads | Active | Active | |
| Output video | Active | Active |
The bandwidth for each data stream is:
- A video stream (input video, warped image and output video)
- A coefficient stream (coefficient reads)
- Cache loads (a scaled version of a video stream).
Peak Memory Bandwidth Approximation for Video Streams
The equation calculates the peak bandwidth (in bits per second) for the video streams passing through the warp (where number_of_lines includes blanking). Each pixel of data is transferred to or from external memory as a 32bit word.
Peak bandwidth = 32 * pixels_per_line * number_of_lines * frame_rate
| Resolution | Frame Rate (fps) | Peak Data Rate (Gbps) |
|---|---|---|
| 3840x2160 (2250 lines) | 60 | 16.6 |
| 3840x2160 (2250 lines) | 30 | 8.3 |
| 1920x1080 (1125 lines) | 60 | 4.2 |
Peak Memory Bandwidth Approximation for Coefficient Streams
You can approximate the memory bandwidth required by the coefficient streams as 9% of a video stream.
| Resolution | Frame Rate (fps) | Peak Data Rate (Gbps) |
|---|---|---|
| 3840x2160 | 60 | 1.5 |
| 3840x2160 | 30 | 0.75 |
| 1920x1080 | 60 | 0.4 |
Peak Memory Bandwidth Approximation for Cache Loads
The memory bandwidth required by the IP for the cache loads is closely linked to the warp transform that the IP applies. The memory bandwidth is proportional to the bandwidth required by a standard video stream. It is also affected by Use single memory bounce.
When Use single memory bounce is off, the worst-case bandwidth required for cache loads is experienced for a 1:1 or unity warp and is approximately 25% higher than a normal video stream. The unity warp gives an upper bound for the bandwidth. Other transforms give lower.
When Use single memory bounce is on, the amount of vertical compression in the transform that the IP performs affects the bandwidth required for cache loads. A 1:1 or unity warp has a 1:1 vertical compression. The resultant cache load bandwidth is equivalent to the bandwidth for a standard video stream. In contrast, a 53 degree vertical keystone warp has a vertical compression approaching 2:1 in some regions. The maximum cache load bandwidth for this warp is two times the standard video stream bandwidth. The 2:1 ratio provides an upper bound for the cache load bandwidth for recommended operation.
The recommended 2:1 compression limit comes from the limitations of the low pass filtering that takes place in the bicubic pixel interpolation process when generating output pixels. However, you can generate transforms that have a compression ratio of greater than 2:1, which can potentially affect the single memory bounce memory bandwidth and reduce the final picture quality.
Memory Interface Bandwidth Requirements
| Resolution | Frame Rate (fps) | Maximum Burst Data Rate (Gbps) |
| 3840x2160 | 60 | 34 |
| 3840x2160 | 30 | 17 |
| 1920x1080 | 60 | 8.5 |
| Resolution | Frame Rate (fps) | Maximum Burst Data Rate (Gbps) |
|---|---|---|
| 3840x2160 | 60 | 51.3 |
| 3840x2160 | 30 | 25.7 |
| 1920x1080 | 60 | 8.5 |
| Resolution | Frame Rate (fps) | Maximum Burst Data Rate (Gbps) |
|---|---|---|
| 3840x2160 | 60 | 72 |
| 3840x2160 | 30 | 36 |
| 1920x1080 | 60 | 18 |
Intel references these burst data rates to the memory interface of the IP. The total data rates available are affected by other factors outside of the IP such as the performance of the interconnect fabric and the efficiency of the memory controller.
Example system sharing access to memory
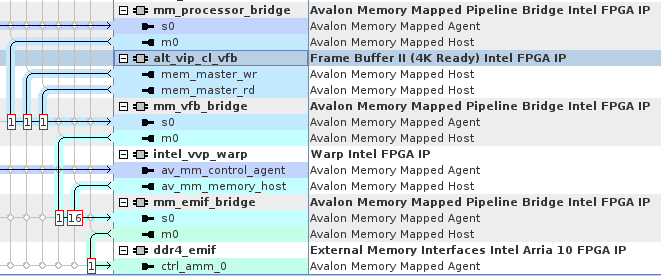
In this example system the Warp IP shares the DDR4 interface with a frame buffer in a system that processes UHD frames at 60 fps. The system runs on an Intel Arria 10 GX Development Kit with the DDR4 EMIF running a 2,133 MHz interface to a DDR4 memory. This system has four memory-mapped hosts accessing the memory: processor, frame buffer read, frame buffer write, and warp.
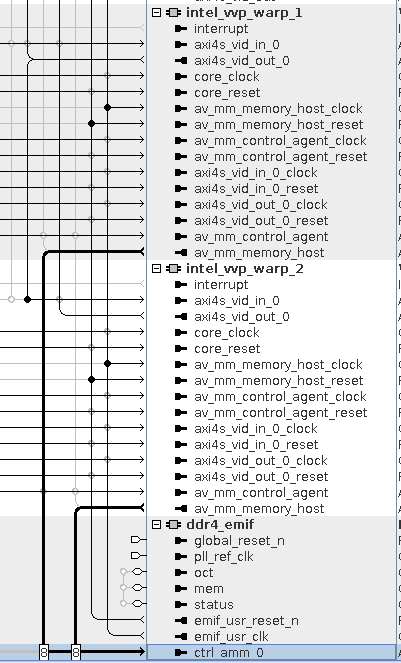
Figure 107. Warp and Video Frame Buffer Platform DesignerThe figure shows the Platform Designer connectivity where the Frame Buffer II component is sharing access to the DDR4 EMIF with the Warp IP. The Frame Buffer is part of the same video processing pipeline as the Warp IP. For clarity, the figure only shows the Avalon memory-mapped Interfaces and Show Arbitration Shares is on.
For this system to work:
- Configure Frame Buffer to use bursts of 32 beats for read and write.
- Configure Frame Buffer to use read and write FIFO depths of 256
- Set the arbitration weighting at the front end of the DDR4 EMIF to 16:1 in favor of the Warp IP (versus the processor and the Frame Buffer’s read and write interfaces connected through the mm_vfb_bridge component).
- Set the Maximum pending read transactions parameter in the pipelined transfers section of the Avalon memory-mapped ports to be at 8.
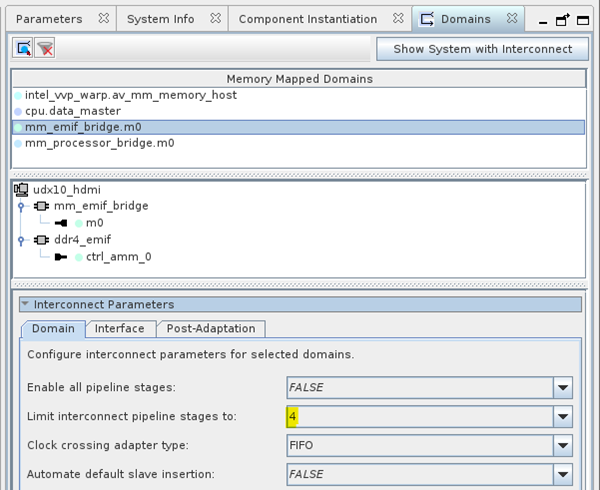
- Set Limit interconnect pipeline stages to for the domain at the front end of the DDR4 EMIF to 4. This limit helps to meet timing on the memory interface clock domain.
Memory accesses from the processor may adversely affect the performance of the rest of the system. If the performance is affected, increase the arbitration weightings at the mm_vfb_bridge component to be 1:2:2 or higher in favor of the Frame Buffer’s read and write interfaces. Alternatively, implement a fixed priority arbitration scheme at the mm_vfb_bridge to reduce the effect of the processor’s memory accesses.
Figure 108. Video Frame Buffer Parameterization

Figure 109. Maximum Pending Read Transactions
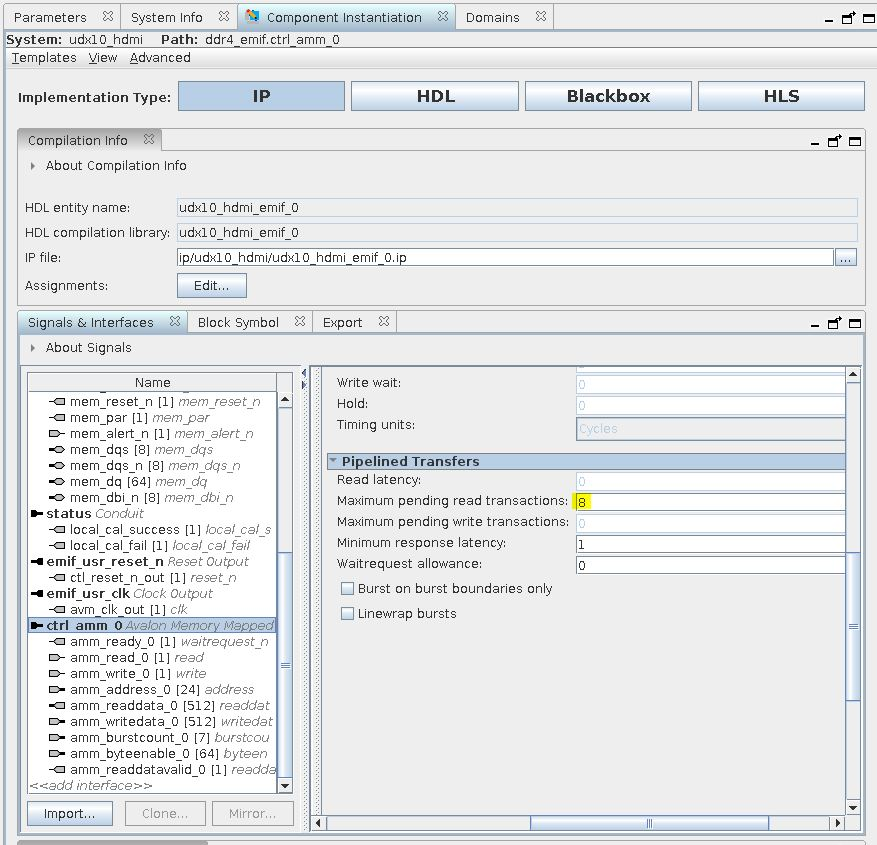
Figure 110. Parameterizing interconnect pipeline stages
Multiple Warp IPs sharing access to memory
Figure 111. Multiple Warp IPs sharing access to memory The figure shows an example with two Warp IPs that share a DDR4 interface. To match the burst access patterns of the Warp IP, set the arbitration values at the combining interface to 8.