Visible to Intel only — GUID: GUID-F796E448-400B-4F1A-86FD-100949A0F5F4
Intel oneAPI DPC++/C++ Compiler Handbook for FPGAs Overview
Introduction To FPGA Design Concepts
Intel oneAPI FPGA Development
Getting Started with the Intel oneAPI DPC++/C++ Compiler for Intel FPGA Development
Defining a Kernel for FPGAs
Debugging and Verifying Your Design
Analyzing Your Design
Optimizing Your Kernel
Optimizing Your Host Application
Integrating Your Kernel into DSP Builder for Intel FPGAs
Integrating Your RTL IP Core Into a System
RTL IP Core Kernel Interfaces
Loops
Pipes
Data Types and Arithmetic Operations
Parallelism
Memories and Memory Operations
Libraries
Additional FPGA Acceleration Flow Considerations
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the Intel oneAPI DPC++/C++ Compiler Handbook for Intel FPGAs
Notices and Disclaimers
Set the Environment Variables and Launch Visual Studio* Code
Create an FPGA Visual Studio* Code Project
Enable Code Completion in a Visual Studio* Code Project
Configure Running and Debugging in a Visual Studio* Code Project
Debugging Your Kernel in Visual Studio* Code with a Native Debugger
Generate and View the FPGA Optimization Report
Build and Run the FPGA Hardware Image
Throughput
Resource Use
System-level Profiling Using the Intercept Layer for OpenCL™ Applications
Multithreaded Host Application
Utilizing Hardware Kernel Invocation Queue
Double Buffering Host Utilizing Kernel Invocation Queue
N-Way Buffering to Overlap Kernel Execution
Prepinning Memory
Simple Host-Device Streaming
Buffered Host-Device Streaming
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Improve fMAX/II with Shannonization
Optimize Inner Loop Throughput
Improve Loop Performance by Caching Data in On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Specify Schedule fMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Allow Wide Memory Initialization (-Xsallow-wide-device-globals)
Specify Schedule fMAX Target for Kernels (scheduler_target_fmax_mhz)
Specify a Workgroup Size (max_work_group_size/reqd_work_group_size)
Specify Number of SIMD Work Items (num_simd_work_items)
Omit Hardware that Generates and Dispatches Kernel IDs (max_global_work_dim)
Omit Hardware that Supports Global Work Offsets (no_global_work_offset)
Reduce Kernel Area and Latency (use_stall_enable_clusters)
Visible to Intel only — GUID: GUID-F796E448-400B-4F1A-86FD-100949A0F5F4
Optimize Inner Loop Throughput
In this topic, you learn how to optimize throughput of an inner loop with a low trip count. A low trip count is relative. For understanding the concept, consider low to be on the order of 100 or fewer iterations.
NOTE:
Prior to reading the rest of this topic, you must review Maximum Frequency (fMAX) and Optimize Loops With Loop Speculation.
Consider the following example code snippet:
for (int i; i < kOuterLoopBound; i++) {
int inner_loop_iterations = InputPipe::read() % kInnerLoopBound;
for (int j; j < inner_loop_iterations; j++) {
/* ... */
}
}Before you optimize the inner loops with low trip counts, assume the following:
- kOuterLoopBound is a number greater than one million.
- kInnerLoopBound is 3. Because the value of InputPipe::read() is dynamic, we know the value of inner_loop_iterations is in the range (0, 3).
- II of the inner loop is 1, which means that a new inner loop iteration can start every cycle. This means that the outer loop II is dynamic and depends on how many inner loop iterations the previous outer loop iteration must start.
A possible timing diagram for this loop structure is shown in the following figure, where the numbers in the squares are the values of i and j, respectively:
Timing Diagram for the Loop
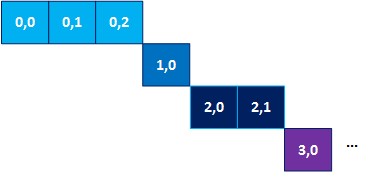
In general, the Intel® oneAPI DPC++/C++ Compiler optimizes loops for throughput with the assumption that the loop has a high trip count. These optimizations include (but are not limited to) speculating iterations and inserting pipeline registers in the circuit that starts loops. The next two sections describe how these optimizations can substantially decrease throughput and how you can disable them to improve your design when applied to inner loops with low trip counts.
Speculated Iterations
Loop Speculation enables loop iterations to be initiated before determining whether they should have been initiated. Speculated iterations are the iterations of a loop that launch before the exit condition computation has been completed. This is beneficial when the computation of the exit condition is preventing effective loop pipelining. However, when an inner loop has a low trip count, speculating iterations result in a relatively high proportion of invalid loop iterations.
For example, consider that the compiler speculated two inner loop iterations for the code above. In that case, the timing diagram appears as shown in the following diagram, where the orange blocks with the S denote an invalid speculated iteration:
Timing Diagram with Invalid Speculated Iteration
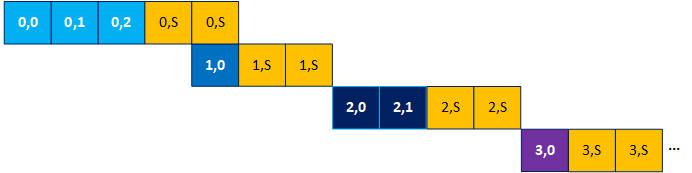
In this case where the inner loop iteration count is in the range (0,3), speculating two iterations can cause up to a 3x reduction in the design's throughput. This happens when each outer loop iteration launches one inner loop iteration (inner_loop_iterations is always 1), but two iterations are speculated. For this reason, Intel® advises to force the compiler to not speculate iterations for inner loops with known small trip counts using the [[intel::speculated_iterations(0)]] attribute.
Dynamic Trip Counts
As mentioned earlier, the compiler's default behavior is to optimize loops for throughput. However, as you saw in the previous section, loops with low trip counts have unique throughput characteristics that lead to the compiler making different optimizations. The compiler attempts its best to determine if a loop has a high or low trip count and optimizes accordingly. However, in some circumstances, you may need to provide it with more information to make a better decision.
In the previous section, this additional information was the speculated_iterations attribute. However, it is not just speculated iterations that cause delays in the launching of inner loops. The compiler uses other heuristics. For example, the compiler may attempt to improve the fMAX of a loop circuit by adding a pipeline register on the circuit path that starts a loop, which results in a one-cycle delay in starting the loop. For outer loops with large trip counts, this one cycle delay is negligible. However, for inner loops with small trip counts, this one cycle delay can cause throughput degradation. Like the speculated iteration case discussed in the previous section, this one cycle delay can result in up to a 2x reduction in the design's throughput.
If the inner loop bounds are known to the compiler, it decides whether to turn on/off this delay register depending on the (known) trip count. However, in the code snippet above, the inner loop's trip count is not a constant (inner_loop_iterations is a random number at runtime). In cases like this, Intel recommends explicitly bounding the trip count of the inner loop. This is illustrated in the example code snippet in the following, where j < kInnerLoopBound exit condition is added to the inner loop. This gives the compiler more explicit information about the loop's trip count and allows it to optimize accordingly.
for (int i; i < kOuterLoopBound; i++) {
int inner_loop_iterations = InputPipe::read() % kInnerLoopBound;
for (int j; j < inner_loop_iterations && j < kInnerLoopBound; j++) {
/* ... */
}
}
NOTE:
For additional information, refer to the FPGA tutorial sample "Optimize Inner Loop" on GitHub.
Parent topic: Loops