Developer Guide
Intel® oneAPI DPC++/C++ Compiler Handbook for FPGAs
Visible to Intel only — GUID: GUID-195C1602-FFCD-470D-80BA-440D21EA70B6
Visible to Intel only — GUID: GUID-195C1602-FFCD-470D-80BA-440D21EA70B6
Double Buffering Host Utilizing Kernel Invocation Queue
Double buffering in SYCL* host application allows SYCL runtime environment to coalesce memory transfers and kernel execution.
In an application where the FPGA kernel is executed multiple times, the host must perform the following processing and buffer transfers before each kernel invocation.
- The output data from the previous invocation must be transferred from device to host and then processed by the host. Examples of this processing include:
- Copying the data to another location
- Rearranging the data
- Verifying it in some way
- The input data for the next invocation must be processed by the host and then transferred to the device. Examples of this processing include:
- Copying the data from another location
- Rearranging the data for kernel consumption
- Generating the data in some way
Without double buffering, host processing and buffer transfers occur between kernel executions. Therefore, there is a gap in time between kernel executions, which you can refer as kernel downtime (See Figure 1). If these operations overlap with kernel execution, the kernels can execute back-to-back with minimal downtime, thereby increasing overall application performance.
Determine When is Double Buffering Possible
Consider the following illustration:
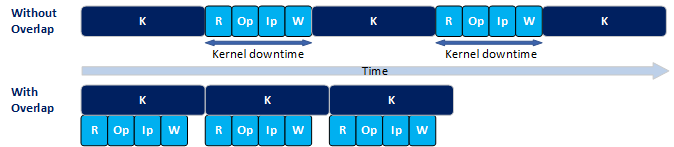
Following are the definitions of the required variables:
- R: Time to transfer the kernel's output buffer from device to host.
- Op: Host-side processing time of kernel output data (output processing)
- Ip: Host-side processing time for kernel input data (input processing)
- W: Time to transfer the kernel's input buffer from host to device.
- K: Kernel execution time
In general, R, Op, Ip, and W operations must all complete before the next kernel is launched. To maximize performance, while one kernel is executing on the device, these operations should execute simultaneously on the host and operate on a second set of buffer locations. They should complete before the current kernel completes, thus allowing the next kernel to be launched immediately with no downtime. In general, to maximize performance, the host must launch a new kernel every K.
This leads to the following constraint:
R + Op + Ip + W <= K, to minimize kernel downtime
If the above constraint is not satisfied, a performance improvement may still be observed because of some overlap (perhaps not complete overlap) is still possible.
Measure the Impact of Double Buffering
You must get a sense of the kernel downtime to identify the degree to which this technique can help improve performance.
This can be done by querying the total kernel execution time from the runtime and comparing it to the overall application execution time. In an application where kernels execute with minimal downtime, these two numbers are close. However, if kernels have a lot of downtime, overall execution time notably exceeds kernel execution time.
Hardware Kernel Invocation Queue While Double Buffering Example
To utilize hardware kernel invocation queue while double buffering, write your host code as shown in the following code snippet:
main() { ... initialize_input(input_buf[0]); initialize_input(input_buf[1]); simple_kernel(device_queue, input_buf[0], output_buf[0]); for (int i = 1; i < TIMES; i++) { simple_kernel(device_queue, input_buf[i%2], output_buf[i%2]); // Launch the next kernel // Process output from previous kernel. // This will block on kernel completion. check_output(output_buf[(i-1)%2]); // Generate input for the next kernel. initialize_input(input_buf[(i-1)%2]); } ... }
The following is the example function definition for initialize_input():
void initialize_input (buffer<cl_float, 1> &inBuffer){ accessor buf_acc(inBuffer, write_only, no_init); for (int i = 0; i < N; i++) { buf_acc[i] = rand(); } }
For additional information, refer to the FPGA tutorial sample "Double Buffering" on GitHub.