Visible to Intel only — GUID: GUID-C43D99D4-E22C-4F8B-8469-CEC8A72EDC7C
Intel oneAPI DPC++/C++ Compiler Handbook for FPGAs Overview
Introduction To FPGA Design Concepts
Intel oneAPI FPGA Development
Getting Started with the Intel oneAPI DPC++/C++ Compiler for Intel FPGA Development
Defining a Kernel for FPGAs
Debugging and Verifying Your Design
Analyzing Your Design
Optimizing Your Kernel
Optimizing Your Host Application
Integrating Your Kernel into DSP Builder for Intel FPGAs
Integrating Your RTL IP Core Into a System
RTL IP Core Kernel Interfaces
Loops
Pipes
Data Types and Arithmetic Operations
Parallelism
Memories and Memory Operations
Libraries
Additional FPGA Acceleration Flow Considerations
FPGA Optimization Flags, Attributes, Pragmas, and Extensions
Quick Reference
Additional Information
Document Revision History for the Intel oneAPI DPC++/C++ Compiler Handbook for Intel FPGAs
Notices and Disclaimers
Set the Environment Variables and Launch Visual Studio* Code
Create an FPGA Visual Studio* Code Project
Enable Code Completion in a Visual Studio* Code Project
Configure Running and Debugging in a Visual Studio* Code Project
Debugging Your Kernel in Visual Studio* Code with a Native Debugger
Generate and View the FPGA Optimization Report
Build and Run the FPGA Hardware Image
Throughput
Resource Use
System-level Profiling Using the Intercept Layer for OpenCL™ Applications
Multithreaded Host Application
Utilizing Hardware Kernel Invocation Queue
Double Buffering Host Utilizing Kernel Invocation Queue
N-Way Buffering to Overlap Kernel Execution
Prepinning Memory
Simple Host-Device Streaming
Buffered Host-Device Streaming
Refactor the Loop-Carried Data Dependency
Relax Loop-Carried Dependency
Transfer Loop-Carried Dependency to Local Memory
Minimize the Memory Dependencies for Loop Pipelining
Unroll Loops
Fuse Loops to Reduce Overhead and Improve Performance
Optimize Loops With Loop Speculation
Remove Loop Bottlenecks
Improve fMAX/II with Shannonization
Optimize Inner Loop Throughput
Improve Loop Performance by Caching Data in On-Chip Memory
Global Memory Bandwidth Use Calculation
Manual Partition of Global Memory
Partitioning Buffers Across Different Memory Types (Heterogeneous Memory)
Partitioning Buffers Across Memory Channels of the Same Memory Type
Ignoring Dependencies Between Accessor Arguments
Contiguous Memory Accesses
Static Memory Coalescing
Specify Schedule fMAX Target for Kernels (-Xsclock=<clock target>)
Create a 2xclock Interface (-Xsuse-2xclock)
Disable Burst-Interleaving of Global Memory (-Xsno-interleaving)
Force Ring Interconnect for Global Memory (-Xsglobal-ring)
Force a Single Store Ring to Reduce Area (-Xsforce-single-store-ring)
Force Fewer Read Data Reorder Units to Reduce Area (-Xsnum-reorder)
Disable Hardware Kernel Invocation Queue (-Xsno-hardware-kernel-invocation-queue)
Modify the Handshaking Protocol Between Clusters (-Xshyper-optimized-handshaking)
Disable Automatic Fusion of Loops (-Xsdisable-auto-loop-fusion)
Fuse Adjacent Loops With Unequal Trip Counts (-Xsenable-unequal-tc-fusion)
Pipeline Loops in Non-task Kernels (-Xsauto-pipeline)
Control Semantics of Floating-Point Operations (-fp-model=<value>)
Modify the Rounding Mode of Floating-point Operations (-Xsrounding=<rounding_type>)
Global Control of Exit FIFO Latency of Stall-free Clusters (-Xssfc-exit-fifo-type=<value>)
Enable the Read-Only Cache for Read-Only Accessors (-Xsread-only-cache-size=<N>)
Control Hardware Implementation of the Supported Data Types and Math Operations (-Xsdsp-mode=<option>)
Generate Register Map Wrapper (-Xsregister-map-wrapper-type)
Allow Wide Memory Initialization (-Xsallow-wide-device-globals)
Specify Schedule fMAX Target for Kernels (scheduler_target_fmax_mhz)
Specify a Workgroup Size (max_work_group_size/reqd_work_group_size)
Specify Number of SIMD Work Items (num_simd_work_items)
Omit Hardware that Generates and Dispatches Kernel IDs (max_global_work_dim)
Omit Hardware that Supports Global Work Offsets (no_global_work_offset)
Reduce Kernel Area and Latency (use_stall_enable_clusters)
Visible to Intel only — GUID: GUID-C43D99D4-E22C-4F8B-8469-CEC8A72EDC7C
N-Way Buffering to Overlap Kernel Execution
N-way buffering is a generalization of the double buffering optimization technique. This system-level optimization enables kernel execution to occur in parallel with host-side processing and buffer transfers between host and device, improving application performance. N-way buffering can achieve this overlap even when the host-processing time exceeds kernel execution time.
In an application where the FPGA kernel is executed multiple times, the host must perform the following processing and buffer transfers before each kernel invocation.
- The output data from the previous invocation must be transferred from the device to the host and then processed by the host. Examples of this processing include the following:
- Copying the data to another location
- Rearranging the data
- Verifying it in some way
- The input data for the next invocation must be processed by the host and then transferred to the device. Examples of this processing include:
- Copying the data from another location
- Rearranging the data for kernel consumption
- Generating the data in some way
Without the N-way buffering, host processing and buffer transfers occur between kernel executions. Therefore, there is a gap in time between kernel executions, which you can refer as kernel downtime (See Figure 1). If these operations overlap with kernel execution, the kernels can execute back-to-back with minimal downtime, thereby increasing the overall application performance.
Determine When is N-Way Buffering Possible
N-way buffering is frequently referred to as double buffering in the most common case where N=2.
Consider the following illustration:
N-Way Buffering Host
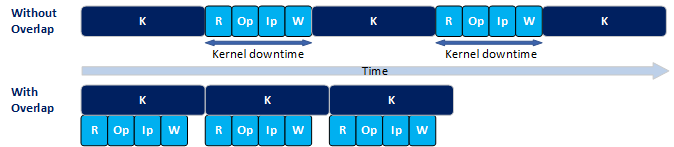
The following are the definitions of the required variables:
- R: Time to transfer the kernel's output buffer from device to host.
- Op: Host-side processing time of kernel output data (output processing).
- Ip: Host-side processing time for kernel input data (input processing).
- W: Time to transfer the kernel's input buffer from host to device.
- K: Kernel execution time
- N: The number of buffer sets used.
- C: The number of host-side CPU cores.
In general, R, Op, Ip, and W operations must all complete before the next kernel is launched. To maximize performance, while one kernel is executing on the device, these operations must run in parallel and operate on a separate set of buffer locations. They must complete before the current kernel completes, thus allowing the next kernel to be launched immediately with no downtime. In general, to maximize performance, the host must launch a new kernel every K.
If these host-side operations are executed serially, this leads to the following constraint:
R + Op + Ip + W <= K, to minimize kernel downtime
In the above example, if the constraint is satisfied, the application requires two sets of buffers. In this case, N=2. However, the above constraint may not be satisfied in some applications if host-processing takes longer than the kernel execution time.
NOTE:
A performance improvement may still be observed because kernel downtime may still be reduced (though perhaps not maximally reduced).
In this case, to further improve performance, reduce host-processing time through multithreading. Instead of executing the above operations serially, perform the input and output-processing operations in parallel using two threads, leading to the following constraint:
Max (R+Op, Ip+W) <= K R + W <= K, to minimize kernel downtime
If the above constraint is still unsatisfied, the technique can be extended beyond two sets of buffers to N sets of buffers to help improve the degree of overlap. In this case, the constraint becomes:
Max (R + Op, Ip + W) <= (N-1)*K R + W <= K, to minimize kernel downtime.
The idea of N-way buffering is to prepare N sets of kernel input buffers, launch N kernels, and when the first kernel completes, begin the subsequent host-side operations. These operations may take a long time (longer than K), but they do not cause kernel downtime because an additional N-1 kernels have already been queued and can launch immediately. By the time these first N kernels complete, the aforementioned host-side operations would have also completed, and the N+1 kernel can be launched with no downtime. As additional kernels complete, corresponding host-side operations are launched on the host, using multiple threads in a parallel fashion. Although the host operations take longer than K, if N is chosen correctly, they complete with a period of K, which is required to ensure you can launch a new kernel every K. To reiterate, this scheme requires multi-threaded host-operations because the host must perform processing for up to N kernels in parallel to keep up.
Use the above formula to calculate the N required to minimize downtime. However, there are some practical limits:
- N sets of buffers are required on both the host and device. Therefore, both must have the capacity for this many buffers.
- If the input and output processing operations are launched in separate threads, then (N-1)*2 cores are required so that C can become the limiting factor.
Measure the Impact of N-Way Buffering
You must get a sense of the kernel downtime to identify the degree to which this technique can help improve performance.
You can do this by querying the total kernel execution time from the runtime and comparing it to the overall application execution time. In an application where kernels execute with minimal downtime, these two numbers are close. However, if kernels have a lot of downtime, overall execution time notably exceeds the kernel execution time.
NOTE:
For additional information, refer to the FPGA tutorial sample "N-Way Buffering" on GitHub.
Parent topic: Optimizing Your Host Application