Visible to Intel only — GUID: nkg1517866511623
Ixiasoft
1. Introduction to Standard Edition Best Practices Guide
2. Reviewing Your Kernel's report.html File
3. OpenCL Kernel Design Best Practices
4. Profiling Your Kernel to Identify Performance Bottlenecks
5. Strategies for Improving Single Work-Item Kernel Performance
6. Strategies for Improving NDRange Kernel Data Processing Efficiency
7. Strategies for Improving Memory Access Efficiency
8. Strategies for Optimizing FPGA Area Usage
A. Additional Information
2.1. High Level Design Report Layout
2.2. Reviewing the Report Summary
2.3. Reviewing Loop Information
2.4. Reviewing Area Information
2.5. Verifying Information on Memory Replication and Stalls
2.6. Optimizing an OpenCL Design Example Based on Information in the HTML Report
2.7. HTML Report: Area Report Messages
2.8. HTML Report: Kernel Design Concepts
3.1. Transferring Data Via Channels or OpenCL Pipes
3.2. Unrolling Loops
3.3. Optimizing Floating-Point Operations
3.4. Allocating Aligned Memory
3.5. Aligning a Struct with or without Padding
3.6. Maintaining Similar Structures for Vector Type Elements
3.7. Avoiding Pointer Aliasing
3.8. Avoid Expensive Functions
3.9. Avoiding Work-Item ID-Dependent Backward Branching
4.3.4.1. High Stall Percentage
4.3.4.2. Low Occupancy Percentage
4.3.4.3. Low Bandwidth Efficiency
4.3.4.4. High Stall and High Occupancy Percentages
4.3.4.5. No Stalls, Low Occupancy Percentage, and Low Bandwidth Efficiency
4.3.4.6. No Stalls, High Occupancy Percentage, and Low Bandwidth Efficiency
4.3.4.7. Stalling Channels
4.3.4.8. High Stall and Low Occupancy Percentages
7.1. General Guidelines on Optimizing Memory Accesses
7.2. Optimize Global Memory Accesses
7.3. Performing Kernel Computations Using Constant, Local or Private Memory
7.4. Improving Kernel Performance by Banking the Local Memory
7.5. Optimizing Accesses to Local Memory by Controlling the Memory Replication Factor
7.6. Minimizing the Memory Dependencies for Loop Pipelining
Visible to Intel only — GUID: nkg1517866511623
Ixiasoft
4.2.1.1. Tool Tip Options
To obtain additional information about the kernel source code, hover your mouse over channel accesses in the code to activate the tool tip.
Figure 65. The GUI: Source Code Tab Tool Tip
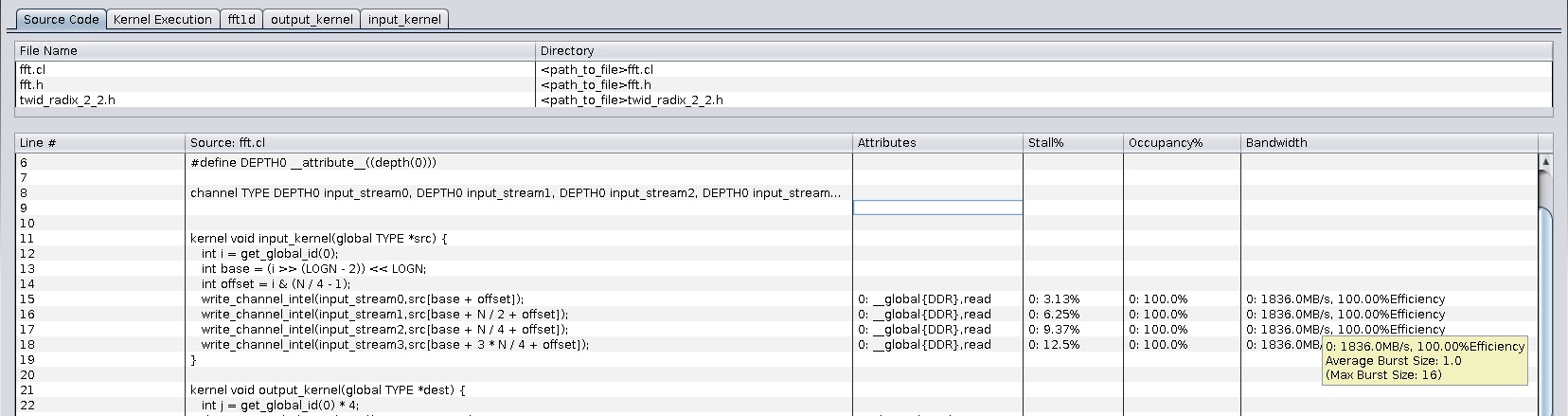
Attention: If your kernel undergoes memory optimization that consolidates hardware resources that implement multiple memory operations, statistical data might not be available for each memory operation. One set of statistical data will map to the point of consolidation in hardware.
| Column | Tool Tip | Description | Example Message | Access Type |
|---|---|---|---|---|
| Attributes | Cache Hits | The number of memory accesses using the cache. A high cache hit rate reduces memory bandwidth utilization. |
Cache Hit%=30% | Global memory |
| Unaligned Access | The percentage of unaligned memory accesses. A high unaligned access percentage signifies inefficient memory accesses. Consider modifying the access patterns in the kernel code to improve efficiency. |
Unaligned Access%=20% | Global memory | |
| Statically Coalesced | Indication of whether the load or store memory operation is statically coalesced. Generally, static memory coalescing merges multiple memory accesses that access consecutive memory addresses into a single wide access. |
Coalesced | Global or local memory | |
| Occupancy% | Activity | The percentage of time a predicated channel or memory instruction is enabled (that is, when conditional execution is true).
Note: The activity percentage might be less than the occupancy of the instruction.
|
Activity=20% | Global or local memory, and channels |
| Bandwidth | Burst Size | The average burst size of the memory operation. If the memory system does not support burst mode (for example, on-chip RAM), no burst information will be available. |
Average Burst Size=7.6 (Max Burst=16) |
Global memory |