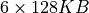A newer version of this document is available. Customers should click here to go to the newest version.
Intel® Xe GPU Architecture
The Intel® Xe GPU family consists of a series of microarchitectures, ranging from integrated/low power (Xe-LP), to enthusiast/high performance gaming (Xe-HPG), data center/AI (Xe-HP) and high performance computing (Xe-HPC).

This chapter introduces Xe GPU family microarchitectures and configuration parameters.
Xe-LP Execution Units (EUs)
An Execution Unit (EU) is the smallest thread-level building block of the Intel® Iris® Xe-LP GPU architecture. Each EU is simultaneously multithreaded (SMT) with seven threads. The primary computation unit consists of a 8-wide Single Instruction Multiple Data (SIMD) Arithmetic Logic Units (ALU) supporting SIMD8 FP/INT operations and a 2-wide SIMD ALU supporting SIMD2 extended math operations. Each hardware thread has 128 general-purpose registers (GRF) of 32B wide.
Xe-LP EU supports diverse data types FP16, INT16 and INT8 for AI applications. The below table shows the EU operation throughput of Xe-LP GPU for various data types.
FP32 |
FP16 |
INT32 |
INT16 |
INT 8 |
|---|---|---|---|---|
8 |
16 |
8 |
16 |
32 (DP4A) |
Xe-LP Dual Subslices
Each Xe-LP Dual Subslice (DSS) consists of an EU array of 16 EUs, an instruction cache, a local thread dispatcher, Shared Local Memory (SLM), and a data port of 128B/cycle. It is called dual subslice because the hardware can pair two EUs for SIMD16 executions.
The SLM consists of 128KB low latency and high bandwidth memory accessible from the EUs in the subslice. One important usage of SLM is to share atomic data and signals among the concurrent work-items executing in a subslice. For this reason, if a kernel’s work-group contains synchronization operations, all work-items of the work-group must be allocated to a single subslice so that they have shared access to the same 128KB SLM. The work-group size must be chosen carefully to maximize the occupancy and utilization of the subslice. In contrast, if a kernel does not access SLM, its work-items can be dispatched across multiple subslices.
The following table summarizes the computing capacity of a Intel® Iris® Xe-LP subslice.
EUs |
Threads |
Operations |
|---|---|---|
16 |
|
|
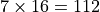
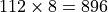
Xe-LP Slice
Each Xe-LP slice consists of six (dual) subslices for a total of 96 EUs, up to 16MB L2 cache, 128B/cycle bandwidth to L2 and 128B/cycle bandwidth to memory.

Xe-Core
Unlike the Xe-LP and prior generations of Intel GPUs that used the Execution Unit (EU) as a compute unit, Xe-HPG and Xe-HPC use the Xe-core. This is similar to an Xe-LP dual subslice.
An Xe-core contains vector and matrix ALUs, which are referred to as vector and matrix engines.
An Xe-core of the Xe-HPC GPU contains 8 vector and 8 matrix engines, alongside a large 512KB L1 cache/SLM. It powers the Intel® Data Center GPU Max Series. Each vector engine is 512 bit wide supporting 16 FP32 SIMD operations with fused FMAs. With 8 vector engines, the Xe-core delivers 512 FP16, 256 FP32 and 128 FP64 operations/cycle. Each matrix engine is 4096 bit wide. With 8 matrix engines, the Xe-core delivers 8192 int8 and 4096 FP16/BF16 operations/cycle. The Xe-core provides 1024B/cycle load/store bandwidth to the memory system.

Xe-Slice
An Xe-slice contains 16 Xe-core for a total of 8MB L1 cache, 16 ray tracing units and 1 hardware context.

Xe-Stack
An Xe-stack contains up to 4 Xe-slice: 64 Xe-cores, 64 ray tracing units, 4 hardware contexts, 4 HBM2e controllers, 1 media engine, and 8 Xe-Links of high speed coherent fabric. It also contains a shared L2 cache.

Xe-HPC 2-Stack Data Center GPU Max
An Xe-HPC 2-stack Data Center GPU Max, previously code named Ponte Vecchio or PVC, consists of up to 2 stacks:: 8 slices, 128 Xe-cores, 128 ray tracing units, 8 hardware contexts, 8 HBM2e controllers, and 16 Xe-Links.

Xe-HPG GPU
Xe-HPG is the enthusiast or high performance gaming variant of the Xe architecture. The microarchitecture is focused on graphics performance and supports hardware-accelerated ray tracing.
An Xe-core of the Xe-HPG GPU contains 16 vector and 16 matrix engines. It powers the Intel® Arc GPUs. Each vector engine is 256 bit wide, supporting 8 FP32 SIMD operations with fused FMAs. With 16 vector engines, the Xe-core delivers 256 FP32 operations/cycle. Each matrix engine is 1024 bit wide. With 16 matrix engines, the Xe-core delivers 4096 int8 and 2048 FP16/BF16 operations/cycle. The Xe-core provides 512B/cycle load/store bandwidth to the memory system.
An Xe-HPG GPU consists of 8 Xe-HPG-slice, which contains up to 4 Xe-HPG-cores for a total of 4096 FP32 ALU units/shader cores.
Xe- Intel® Data Center GPU Flex Series
Intel® Data Center GPU Flex Series come in two configurations. The 150W option has 32 Xe-cores on a PCIe Gen4 card. The 75W option has two GPUs for 16 Xe-cores (8 Xe-cores per GPU). Both configurations come with 4 Xe media engines, the industry’s first AV1 hardware encoder and accelerator for data center, GDDR6 memory, ray tracing units, and built-in XMX AI acceleration.
Intel® Data Center GPU Flex Series are derivatives of the Xe-HPG GPUs. An Intel® Data Center GPU Flex 170 consists of 8 Xe-HPG-slices for a total of 32 Xe-cores with 4096 FP32 ALU units/shader cores.
Targeting data center cloud gaming, media streaming and video analytics applications, Intel® Data Center GPU Flex Series provide hardware accelerated AV1 encoder, delivering a 30% bit-rate improvement without compromising on quality. It supports 8 simultaneous 4K streams or more than 30 1080p streams per card. AI models can be applied to the decoded streams utilizing Intel® Data Center GPU Flex Series’ Xe-cores.
Media streaming and delivery software stacks lean on Intel® Video Processing Library (Intel VPL) to decode and encode acceleration for all the major codecs including AV1. Media distributors can choose from the two leading media frameworks FFMPEG or GStreamer, both enabled for acceleration with Intel VPL on Intel CPUs and GPUs.
In parallel to Intel VPL accelerating decoding and encoding of media streams, oneDNN (oneAPI Deep Neural Network library) delivers AI optimized kernels enabled to accelerate inference modes in TensorFlow or PyTorch frameworks, or with the OpenVINO model optimizer and inference engine to further accelerate inference and speed customer deployment of their workloads.
Terminology and Configuration Summary
The following table maps legacy GPU terminologies (used in Generation 9 through Generation 12 Intel® CoreTM architectures) to their new names in the Intel® Iris® Xe GPU (Generation 12.7 and newer) architecture paradigm.
Old Term |
New Intel Term |
Generic Term |
New Abbreviation |
|---|---|---|---|
Execution Unit (EU) |
Xe Vector Engine |
Vector Engine |
XVE |
Systolic/”DPAS part of EU” |
Xe Matrix eXtension |
Matrix Engine |
XMX |
Subslice (SS) or Dual Subslice (DSS) |
Xe-core |
NA |
XC |
Slice |
Render Slice / Compute Slice |
Slice |
SLC |
Tile |
Stack |
Stack |
STK |
The following table lists the hardware characteristics across the Xe family GPUs.
Architecture |
Xe-LP (TGL) |
Xe-HPG (Arc A770) |
Xe-HPG (Data Center GPU Flex 170) |
Xe-HPC (Data Center GPU Max 1550) |
|---|---|---|---|---|
Slice count |
1 |
8 |
8 |
4 x 2 |
XC (DSS/SS) count |
6 |
32 |
32 |
64 x 2 |
XVE (EU) / XC |
16 |
16 |
16 |
8 |
XVE count |
96 |
512 |
512 |
512 x 2 |
Threads / XVE |
7 |
8 |
8 |
8 |
Thread count |
672 |
4096 |
4096 |
4096 x 2 |
FLOPs / clk - single precision, MAD |
1536 |
8192 |
8192 |
16384 x 2 |
FLOPs / clk - double precision, MAD |
NA |
NA |
NA |
16384 x 2 |
FLOPs / clk - FP16 DP4AS |
NA |
65536 |
65536 |
262144 x 2 |
GTI bandwidth bytes / unslice-clk |
r:128, w:128 |
r:512, w:512 |
r:512, w:512 |
r:1024, w:1024 |
LL cache size |
3.84MB |
16MB |
16MB |
up to 408MB |
SLM size |
|
|
|
|
FMAD, SP (ops / XVE / clk) |
8 |
8 |
8 |
16 |
SQRT, SP (ops / XVE / clk) |
2 |
2 |
2 |
4 |