A newer version of this document is available. Customers should click here to go to the newest version.
Efficiently Implementing Fourier Correlation Using oneAPI Math Kernel Library (oneMKL)
Now that straightforward use of oneMKL kernel functions has been covered, let’s look at a more complex mathematical operation: cross-correlation. Cross-correlation has many applications, e.g.: measuring the similarity of two 1D signals, finding the best translation to overlay similar images, volumetric medical image segmentation, etc.
Consider the following simple signals, represented as vectors of ones and zeros:
Signal 1: 0 0 0 0 0 1 1 0
Signal 2: 0 0 1 1 0 0 0 0The signals are treated as circularly shifted versions of each other, so shifting the second signal three elements relative to the first signal will give the maximum correlation score of two:
Signal 1: 0 0 0 0 0 1 1 0
Signal 2: 0 0 1 1 0 0 0 0
Correlation: (1 * 1) + (1 * 1) = 2Shifts of two or four elements give a correlation score of one. Any other shift gives a correlation score of zero. This is computed as follows:
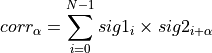
where 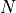 is the number of elements in the signal vectors and
is the number of elements in the signal vectors and  is the shift of
is the shift of  relative to
relative to  .
.
Real signals contain more data (and noise) but the principle is the same whether you are aligning 1D signals, overlaying 2D images, or performing 3D volumetric image registration. The goal is to find the translation that maximizes correlation. However, the brute force summation shown above requires multiplications and additions for every shifts. In 1D, 2D, and 3D, the problem is  ,
, 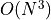 , and
, and 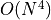 , respectively.
, respectively.
The Fourier correlation algorithm is a much more efficient way to perform this computation because it takes advantage of the 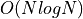 of the Fourier transform:
of the Fourier transform:
corr = IDFT(DFT(sig1) * CONJG(DFT(sig2)))where DFT is the discrete Fourier transform, IDFT is the inverse DFT, and CONJG is the complex conjugate. The Fourier correlation algorithm can be composed using oneMKL, which contains optimized forward and backward transforms and complex conjugate multiplication functions. Therefore, the entire computation can be performed on the accelerator device.
In many applications, only the final correlation result matters, so this is all that has to be transferred from the device back to the host.
In the following example, two artificial signals will be created on the device, transformed in-place, and then correlated. The host will retrieve the final result and report the optimal translation and correlation score. Conventional wisdom suggests that buffering would give the best performance because it provides explicit control over data movement between the host and the device.
To test this hypothesis, let’s generate two input signals:
// Create buffers for signal data. This will only be used on the device.
sycl::buffer<float> sig1_buf{N + 2};
sycl::buffer<float> sig2_buf{N + 2};
// Declare container to hold the correlation result (computed on the device,
// used on the host)
std::vector<float> corr(N + 2);
Random noise is often added to signals to prevent overfitting during neural network training, to add visual effects to images, or to improve the detectability of signals obtained from suboptimal detectors, etc. The buffers are initialized with random noise using a simple random number generator in oneMKL:
// Open new scope to trigger update of correlation result
{
sycl::buffer<float> corr_buf(corr);
// Initialize the input signals with artificial data
std::uint32_t seed = (unsigned)time(NULL); // Get RNG seed value
oneapi::mkl::rng::mcg31m1 engine(Q, seed); // Initialize RNG engine
// Set RNG distribution
oneapi::mkl::rng::uniform<float, oneapi::mkl::rng::uniform_method::standard>
rng_distribution(-0.00005, 0.00005);
oneapi::mkl::rng::generate(rng_distribution, engine, N, sig1_buf); // Noise
oneapi::mkl::rng::generate(rng_distribution, engine, N, sig2_buf);
Notice that a new scope is opened and a buffer, corr_buf, is declared for the correlation result. When this buffer goes out of scope, corr will be updated on the host.
An artificial signal is placed at opposite ends of each buffer, similar to the trivial example above:
Q.submit([&](sycl::handler &h) {
sycl::accessor sig1_acc{sig1_buf, h, sycl::write_only};
sycl::accessor sig2_acc{sig2_buf, h, sycl::write_only};
h.single_task<>([=]() {
sig1_acc[N - N / 4 - 1] = 1.0;
sig1_acc[N - N / 4] = 1.0;
sig1_acc[N - N / 4 + 1] = 1.0; // Signal
sig2_acc[N / 4 - 1] = 1.0;
sig2_acc[N / 4] = 1.0;
sig2_acc[N / 4 + 1] = 1.0;
});
}); // End signal initialization
Now that the signals are ready, let’s transform them using the DFT functions in oneMKL:
// Initialize FFT descriptor
oneapi::mkl::dft::descriptor<oneapi::mkl::dft::precision::SINGLE,
oneapi::mkl::dft::domain::REAL>
transform_plan(N);
transform_plan.commit(Q);
// Perform forward transforms on real arrays
oneapi::mkl::dft::compute_forward(transform_plan, sig1_buf);
oneapi::mkl::dft::compute_forward(transform_plan, sig2_buf);
A single-precision, real-to-complex forward transform is committed to the SYCL queue, then an in-place DFT is performed on the data in both buffers. The result of 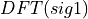 must now be multiplied by
must now be multiplied by  . This could be done with a hand-coded kernel:
. This could be done with a hand-coded kernel:
Q.submit([&](sycl::handler &h)
{
sycl::accessor sig1_acc{sig1_buf, h, sycl::read_only};
sycl::accessor sig2_acc{sig2_buf, h, sycl::read_only};
sycl::accessor corr_acc{corr_buf, h, sycl::write_only};
h.parallel_for<>(sycl::range<1>{N/2}, [=](auto idx)
{
corr_acc[idx*2+0] = sig1_acc[idx*2+0] * sig2_acc[idx*2+0] +
sig1_acc[idx*2+1] * sig2_acc[idx*2+1];
corr_acc[idx*2+1] = sig1_acc[idx*2+1] * sig2_acc[idx*2+0] -
sig1_acc[idx*2+0] * sig2_acc[idx*2+1];
});
});However, this basic implementation is unlikely to give optimal cross-architecture performance. Fortunately, the oneMKL function, oneapi::mkl::vm::mulbyconj, can be used for this step. The mulbyconj function expects std::complex<float> input, but the buffers were initialized as the float data type. Even though they contain complex data after the forward transform, the buffers will have to be recast:
auto sig1_buf_cplx =
sig1_buf.template reinterpret<std::complex<float>, 1>((N + 2) / 2);
auto sig2_buf_cplx =
sig2_buf.template reinterpret<std::complex<float>, 1>((N + 2) / 2);
auto corr_buf_cplx =
corr_buf.template reinterpret<std::complex<float>, 1>((N + 2) / 2);
oneapi::mkl::vm::mulbyconj(Q, N / 2, sig1_buf_cplx, sig2_buf_cplx,
corr_buf_cplx);
The IDFT step completes the computation:
// Perform backward transform on complex correlation array
oneapi::mkl::dft::compute_backward(transform_plan, corr_buf);
When the scope that was opened at the start of this example is closed, the buffer holding the correlation result goes out of scope, forcing an update of the host container. This is the only data transfer between the host and the device.
The complete Fourier correlation implementation using explicit buffering is included below:
#include <CL/sycl.hpp>
#include <iostream>
#include <mkl.h>
#include <oneapi/mkl/dfti.hpp>
#include <oneapi/mkl/rng.hpp>
#include <oneapi/mkl/vm.hpp>
int main(int argc, char **argv) {
unsigned int N = (argc == 1) ? 32 : std::stoi(argv[1]);
if ((N % 2) != 0)
N++;
if (N < 32)
N = 32;
// Initialize SYCL queue
sycl::queue Q(sycl::default_selector_v);
std::cout << "Running on: "
<< Q.get_device().get_info<sycl::info::device::name>() << std::endl;
// Create buffers for signal data. This will only be used on the device.
sycl::buffer<float> sig1_buf{N + 2};
sycl::buffer<float> sig2_buf{N + 2};
// Declare container to hold the correlation result (computed on the device,
// used on the host)
std::vector<float> corr(N + 2);
// Open new scope to trigger update of correlation result
{
sycl::buffer<float> corr_buf(corr);
// Initialize the input signals with artificial data
std::uint32_t seed = (unsigned)time(NULL); // Get RNG seed value
oneapi::mkl::rng::mcg31m1 engine(Q, seed); // Initialize RNG engine
// Set RNG distribution
oneapi::mkl::rng::uniform<float, oneapi::mkl::rng::uniform_method::standard>
rng_distribution(-0.00005, 0.00005);
oneapi::mkl::rng::generate(rng_distribution, engine, N, sig1_buf); // Noise
oneapi::mkl::rng::generate(rng_distribution, engine, N, sig2_buf);
Q.submit([&](sycl::handler &h) {
sycl::accessor sig1_acc{sig1_buf, h, sycl::write_only};
sycl::accessor sig2_acc{sig2_buf, h, sycl::write_only};
h.single_task<>([=]() {
sig1_acc[N - N / 4 - 1] = 1.0;
sig1_acc[N - N / 4] = 1.0;
sig1_acc[N - N / 4 + 1] = 1.0; // Signal
sig2_acc[N / 4 - 1] = 1.0;
sig2_acc[N / 4] = 1.0;
sig2_acc[N / 4 + 1] = 1.0;
});
}); // End signal initialization
clock_t start_time = clock(); // Start timer
// Initialize FFT descriptor
oneapi::mkl::dft::descriptor<oneapi::mkl::dft::precision::SINGLE,
oneapi::mkl::dft::domain::REAL>
transform_plan(N);
transform_plan.commit(Q);
// Perform forward transforms on real arrays
oneapi::mkl::dft::compute_forward(transform_plan, sig1_buf);
oneapi::mkl::dft::compute_forward(transform_plan, sig2_buf);
// Compute: DFT(sig1) * CONJG(DFT(sig2))
auto sig1_buf_cplx =
sig1_buf.template reinterpret<std::complex<float>, 1>((N + 2) / 2);
auto sig2_buf_cplx =
sig2_buf.template reinterpret<std::complex<float>, 1>((N + 2) / 2);
auto corr_buf_cplx =
corr_buf.template reinterpret<std::complex<float>, 1>((N + 2) / 2);
oneapi::mkl::vm::mulbyconj(Q, N / 2, sig1_buf_cplx, sig2_buf_cplx,
corr_buf_cplx);
// Perform backward transform on complex correlation array
oneapi::mkl::dft::compute_backward(transform_plan, corr_buf);
clock_t end_time = clock(); // Stop timer
std::cout << "The 1D correlation (N = " << N << ") took "
<< float(end_time - start_time) / CLOCKS_PER_SEC << " seconds."
<< std::endl;
} // Buffer holding correlation result is now out of scope, forcing update of
// host container
// Find the shift that gives maximum correlation value
float max_corr = 0.0;
int shift = 0;
for (unsigned int idx = 0; idx < N; idx++) {
if (corr[idx] > max_corr) {
max_corr = corr[idx];
shift = idx;
}
}
int _N = static_cast<int>(N);
shift =
(shift > _N / 2) ? shift - _N : shift; // Treat the signals as circularly
// shifted versions of each other.
std::cout << "Shift the second signal " << shift
<< " elements relative to the first signal to get a maximum, "
"normalized correlation score of "
<< max_corr / N << "." << std::endl;
}
The Fourier correlation algorithm will now be reimplemented using Unified Shared Memory (USM) to compare to explicit buffering. Only the differences in the two implementations will be highlighted. First, the signal and correlation arrays are allocated in USM, then initialized with artificial data:
// Initialize signal and correlation arrays
auto sig1 = sycl::malloc_shared<float>(N + 2, sycl_device, sycl_context);
auto sig2 = sycl::malloc_shared<float>(N + 2, sycl_device, sycl_context);
auto corr = sycl::malloc_shared<float>(N + 2, sycl_device, sycl_context);
// Initialize input signals with artificial data
std::uint32_t seed = (unsigned)time(NULL); // Get RNG seed value
oneapi::mkl::rng::mcg31m1 engine(Q, seed); // Initialize RNG engine
// Set RNG distribution
oneapi::mkl::rng::uniform<float, oneapi::mkl::rng::uniform_method::standard>
rng_distribution(-0.00005, 0.00005);
// Warning: These statements run on the device.
auto evt1 =
oneapi::mkl::rng::generate(rng_distribution, engine, N, sig1); // Noise
auto evt2 = oneapi::mkl::rng::generate(rng_distribution, engine, N, sig2);
evt1.wait();
evt2.wait();
// Warning: These statements run on the host, so sig1 and sig2 will have to be
// updated on the device.
sig1[N - N / 4 - 1] = 1.0;
sig1[N - N / 4] = 1.0;
sig1[N - N / 4 + 1] = 1.0; // Signal
sig2[N / 4 - 1] = 1.0;
sig2[N / 4] = 1.0;
sig2[N / 4 + 1] = 1.0;
The rest of the implementation is largely the same except that pointers to USM are passed to the oneMKL functions instead of SYCL buffers:
// Perform forward transforms on real arrays
evt1 = oneapi::mkl::dft::compute_forward(transform_plan, sig1);
evt2 = oneapi::mkl::dft::compute_forward(transform_plan, sig2);
// Compute: DFT(sig1) * CONJG(DFT(sig2))
oneapi::mkl::vm::mulbyconj(
Q, N / 2, reinterpret_cast<std::complex<float> *>(sig1),
reinterpret_cast<std::complex<float> *>(sig2),
reinterpret_cast<std::complex<float> *>(corr), {evt1, evt2})
.wait();
// Perform backward transform on complex correlation array
oneapi::mkl::dft::compute_backward(transform_plan, corr).wait();
It is also necessary to free the allocated memory:
sycl::free(sig1, sycl_context);
sycl::free(sig2, sycl_context);
sycl::free(corr, sycl_context);
The USM implementation has a more familiar syntax. It is also conceptually simpler because it relies on implicit data transfer handled by the SYCL runtime. However, a programmer error hurts performance.
Notice the warning messages in the previous code snippets. The oneMKL random number generation engine is initialized on the device, so sig1 and sig2 are initialized with random noise on the device. Unfortunately, the code adding the artificial signal runs on the host, so the SYCL runtime has to make the host and device data consistent. The signals used in Fourier correlation are usually large, especially in 3D imaging applications, so unnecessary data transfer degrades performance.
Updating the signal data directly on the device keeps the data consistent, thereby avoiding the unnecessary data transfer:
Q.single_task<>([=]() {
sig1[N - N / 4 - 1] = 1.0;
sig1[N - N / 4] = 1.0;
sig1[N - N / 4 + 1] = 1.0; // Signal
sig2[N / 4 - 1] = 1.0;
sig2[N / 4] = 1.0;
sig2[N / 4 + 1] = 1.0;
}).wait();
The explicit buffering and USM implementations now have equivalent performance, indicating that the SYCL runtime is good at avoiding unnecessary data transfers (provided the programmer pays attention to data consistency).
The complete Fourier correlation implementation in USM is included below:
#include <CL/sycl.hpp>
#include <iostream>
#include <mkl.h>
#include <oneapi/mkl/dfti.hpp>
#include <oneapi/mkl/rng.hpp>
#include <oneapi/mkl/vm.hpp>
int main(int argc, char **argv) {
unsigned int N = (argc == 1) ? 32 : std::stoi(argv[1]);
if ((N % 2) != 0)
N++;
if (N < 32)
N = 32;
// Initialize SYCL queue
sycl::queue Q(sycl::default_selector_v);
auto sycl_device = Q.get_device();
auto sycl_context = Q.get_context();
std::cout << "Running on: "
<< Q.get_device().get_info<sycl::info::device::name>() << std::endl;
// Initialize signal and correlation arrays
auto sig1 = sycl::malloc_shared<float>(N + 2, sycl_device, sycl_context);
auto sig2 = sycl::malloc_shared<float>(N + 2, sycl_device, sycl_context);
auto corr = sycl::malloc_shared<float>(N + 2, sycl_device, sycl_context);
// Initialize input signals with artificial data
std::uint32_t seed = (unsigned)time(NULL); // Get RNG seed value
oneapi::mkl::rng::mcg31m1 engine(Q, seed); // Initialize RNG engine
// Set RNG distribution
oneapi::mkl::rng::uniform<float, oneapi::mkl::rng::uniform_method::standard>
rng_distribution(-0.00005, 0.00005);
auto evt1 =
oneapi::mkl::rng::generate(rng_distribution, engine, N, sig1); // Noise
auto evt2 = oneapi::mkl::rng::generate(rng_distribution, engine, N, sig2);
evt1.wait();
evt2.wait();
Q.single_task<>([=]() {
sig1[N - N / 4 - 1] = 1.0;
sig1[N - N / 4] = 1.0;
sig1[N - N / 4 + 1] = 1.0; // Signal
sig2[N / 4 - 1] = 1.0;
sig2[N / 4] = 1.0;
sig2[N / 4 + 1] = 1.0;
}).wait();
clock_t start_time = clock(); // Start timer
// Initialize FFT descriptor
oneapi::mkl::dft::descriptor<oneapi::mkl::dft::precision::SINGLE,
oneapi::mkl::dft::domain::REAL>
transform_plan(N);
transform_plan.commit(Q);
// Perform forward transforms on real arrays
evt1 = oneapi::mkl::dft::compute_forward(transform_plan, sig1);
evt2 = oneapi::mkl::dft::compute_forward(transform_plan, sig2);
// Compute: DFT(sig1) * CONJG(DFT(sig2))
oneapi::mkl::vm::mulbyconj(
Q, N / 2, reinterpret_cast<std::complex<float> *>(sig1),
reinterpret_cast<std::complex<float> *>(sig2),
reinterpret_cast<std::complex<float> *>(corr), {evt1, evt2})
.wait();
// Perform backward transform on complex correlation array
oneapi::mkl::dft::compute_backward(transform_plan, corr).wait();
clock_t end_time = clock(); // Stop timer
std::cout << "The 1D correlation (N = " << N << ") took "
<< float(end_time - start_time) / CLOCKS_PER_SEC << " seconds."
<< std::endl;
// Find the shift that gives maximum correlation value
float max_corr = 0.0;
int shift = 0;
for (unsigned int idx = 0; idx < N; idx++) {
if (corr[idx] > max_corr) {
max_corr = corr[idx];
shift = idx;
}
}
int _N = static_cast<int>(N);
shift =
(shift > _N / 2) ? shift - _N : shift; // Treat the signals as circularly
// shifted versions of each other.
std::cout << "Shift the second signal " << shift
<< " elements relative to the first signal to get a maximum, "
"normalized correlation score of "
<< max_corr / N << "." << std::endl;
// Cleanup
sycl::free(sig1, sycl_context);
sycl::free(sig2, sycl_context);
sycl::free(corr, sycl_context);
}
Note that the final step of finding the location of the maximum correlation value is performed on the host. It would be better to do this computation on the device, especially when the input data is large. Fortunately, the maxloc reduction is a common parallel pattern that can be implemented using SYCL. This is left as an exercise for the reader, but Figure 14-11 of Data Parallel C++ provides a suitable example to help you get started.