A newer version of this document is available. Customers should click here to go to the newest version.
STREAM Example
For a given kernel:
OpenMP:
int *a = (int *)omp_target_alloc(sizeof(int) * N, device_id);
#pragma omp target teams distribute parallel for simd
for (int i = 0; i < N; ++i)
{
a[i] = i;
}
SYCL:
int *a = sycl::malloc_device<int>(N, q);
q.parallel_for(N, [=](auto i) {
a[i] = i;
});
Implicit scaling guarantees 100% local memory accesses. The behavior of static partitioning and memory coloring is visualized below:
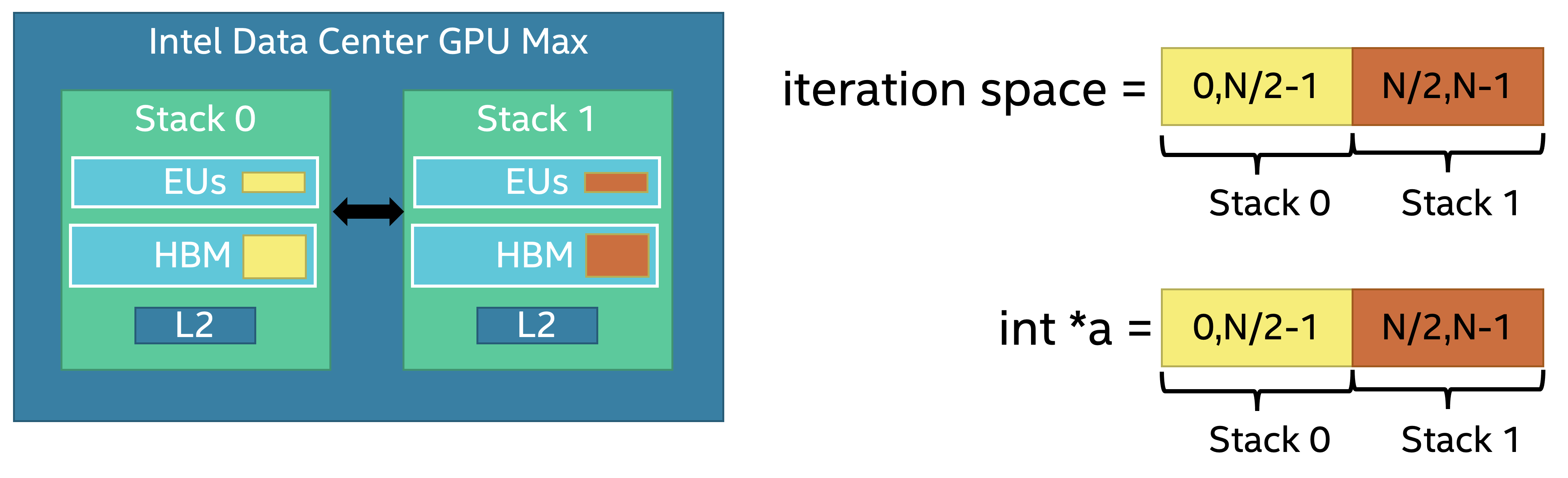
In this section, we demonstrate implicit scaling performance for STREAM benchmark using 1D and 3D kernel launches on Intel® Data Center GPU Max.
STREAM
Consider the STREAM benchmark written in OpenMP. The main kernel is on line 44-48:
// Code for STREAM:
#include <iostream>
#include <omp.h>
#include <cstdint>
// compile via:
// icpx -O2 -fiopenmp -fopenmp-targets=spir64 ./stream.cpp
int main()
{
constexpr int64_t N = 256 * 1e6;
constexpr int64_t bytes = N * sizeof(int64_t);
int64_t *a = static_cast<int64_t *>(malloc(bytes));
int64_t *b = static_cast<int64_t *>(malloc(bytes));
int64_t *c = static_cast<int64_t *>(malloc(bytes));
#pragma omp target enter data map(alloc:a[0:N])
#pragma omp target enter data map(alloc:b[0:N])
#pragma omp target enter data map(alloc:c[0:N])
for (int i = 0; i < N; ++i)
{
a[i] = i + 1;
b[i] = i - 1;
}
#pragma omp target update to(a[0:N])
#pragma omp target update to(b[0:N])
const int no_max_rep = 100;
double time;
for (int irep = 0; irep < no_max_rep + 10; ++irep)
{
if (irep == 10)
time = omp_get_wtime();
#pragma omp target teams distribute parallel for simd
for (int i = 0; i < N; ++i)
{
c[i] = a[i] + b[i];
}
}
time = omp_get_wtime() - time;
time = time / no_max_rep;
#pragma omp target update from(c[0:N])
for (int i = 0; i < N; ++i)
{
if (c[i] != 2 * i)
{
std::cout << "wrong results!" << std::endl;
exit(1);
}
}
const int64_t streamed_bytes = 3 * N * sizeof(int64_t);
std::cout << "bandwidth = " << (streamed_bytes / time) * 1E-9
<< " GB/s" << std::endl;
}
In COMPOSITE mode, the benchmark runs on the entire root-device (GPU card with 2 stacks) by implicit scaling. No code changes are required. The heuristics of static partitioning and memory coloring guarantee that each stack accesses local memory only. On a 2-stack Intel® Data Center GPU Max system we measure 2x speed-up for STREAM compared to a single stack. Measured bandwidth is reported in table below.
Array Size [MB] |
1-stack Bandwidth [GB/s] |
Implicit Scaling (2-stack) Bandwidth [GB/s] |
Implicit Scaling Speed-up over 1-stack |
|---|---|---|---|
512 |
1056 |
2074 |
1.96x |
1024 |
1059 |
2127 |
2x |
2048 |
1063 |
2113 |
1.99x |
3D STREAM
The STREAM benchmark can be modified to use 3D kernel launch via the collapse clause in OpenMP. The intent here is to show performance in case driver heuristics are used to partition the 3D kernel launches between the stacks. The kernel is on line 59-70:
// Code for 3D STREAM
#include <iostream>
#include <omp.h>
#include <cassert>
// compile via:
// icpx -O2 -fiopenmp -fopenmp-targets=spir64 ./stream_3D.cpp
int main(int argc, char **argv)
{
const int device_id = omp_get_default_device();
const int desired_total_size = 32 * 512 * 16384;
const std::size_t bytes = desired_total_size * sizeof(int64_t);
std::cout << "memory footprint = " << 3 * bytes * 1E-9 << " GB"
<< std::endl;
int64_t *a = static_cast<int64_t*>(omp_target_alloc_device(bytes, device_id));
int64_t *b = static_cast<int64_t*>(omp_target_alloc_device(bytes, device_id));
int64_t *c = static_cast<int64_t*>(omp_target_alloc_device(bytes, device_id));
const int min = 64;
const int max = 32768;
for (int lx = min; lx < max; lx *= 2)
{
for (int ly = min; ly < max; ly *= 2)
{
for (int lz = min; lz < max; lz *= 2)
{
const int total_size = lx * ly * lz;
if (total_size != desired_total_size)
continue;
std::cout << "lx=" << lx << " ly=" << ly << " lz="
<< lz << ", ";
#pragma omp target teams distribute parallel for simd
for (int i = 0; i < total_size; ++i)
{
a[i] = i + 1;
b[i] = i - 1;
c[i] = 0;
}
const int no_max_rep = 40;
const int warmup = 10;
double time;
for (int irep = 0; irep < no_max_rep + warmup; ++irep)
{
if (irep == warmup) time = omp_get_wtime();
#pragma omp target teams distribute parallel for simd collapse(3)
for (int iz = 0; iz < lz; ++iz)
{
for (int iy = 0; iy < ly; ++iy)
{
for (int ix = 0; ix < lx; ++ix)
{
const int index = ix + iy * lx + iz * lx * ly;
c[index] = a[index] + b[index];
}
}
}
}
time = omp_get_wtime() - time;
time = time / no_max_rep;
const int64_t streamed_bytes = 3 * total_size * sizeof(int64_t);
std::cout << "bandwidth = " << (streamed_bytes / time) * 1E-9
<< " GB/s" << std::endl;
#pragma omp target teams distribute parallel for simd
for (int i = 0; i < total_size; ++i)
{
assert(c[i] == 2 * i);
}
}
}
}
omp_target_free(a, device_id);
omp_target_free(b, device_id);
omp_target_free(c, device_id);
}
Note that the inner-most loop has stride-1 memory access pattern. If the z- or y-loop were the innermost loop, performance would decrease due to the generation of scatter loads and stores leading to poor cache line utilization. On a 2-stack Intel® Data Center GPU Max with 2 Gigabytes array size, we measure the performance shown below.
nx |
ny |
nz |
1-stack Bandwidth [GB/s] |
Implicit Scaling Bandwidth [GB/s] |
Implicit Scaling Speed-up over 1-stack |
|---|---|---|---|---|---|
64 |
256 |
16834 |
1040 |
2100 |
2.01x |
16834 |
64 |
256 |
1040 |
2077 |
1.99x |
256 |
16834 |
64 |
1037 |
2079 |
2x |
As described in Static Partitioning, for these loop bounds the driver partitions the slowest moving dimension, i.e. the z-dimension, between both stacks. This guarantees that each stack accesses local memory only, leading to close to 2x speed-up with implicit scaling compared to using a single stack.