A newer version of this document is available. Customers should click here to go to the newest version.
Asynchronous and Overlapping Data Transfers Between Host and Device
An accelerator is a separate device from the host CPU and is attached with some form of bus, like PCIe* or CXL*. This bus, depending on its type, has a certain bandwidth through which the host and devices can transfer data. An accelerator needs some data from host to do computation, and overall performance of the system is dependent on how quickly this transfer can happen.
Bandwidth Between Host and Device
Most current accelerators are connected to the host system through PCIe. Different generations of PCIe have increased the bandwidth over time, as shown in the table below.
PCIe Version |
Transfer Rate |
Throughput |
|---|---|---|
1.0 |
2.5 GT/s |
0.250 GB/s |
2.0 |
5.0 GT/s |
0.500 GB/s |
3.0 |
8.0 GT/s |
0.985 GB/s |
4.0 |
16.0 GT/s |
1.969 GB/s |
5.0 |
32.0 GT/s |
3.938 GB/s |
The local memory bandwidth of an accelerator is an order of magnitude higher than host-to-device bandwidth over a link like PCIe. For instance, HBM (High Bandwidth Memory) on modern GPUs can reach up to 900 GB/sec of bandwidth compared to an x16 PCIe, which can get 63 GB/s. So it is imperative to keep data in local memory and avoid data transfer from host to device or device to host as much as possible. This means that it is better to execute all the kernels on the accelerator to avoid data movement between accelerators or between host and accelerator even it means some kernels are not very efficiently executed on these accelerators.
Any intermediate data structures should be created and used on the device, as opposed to creating them on the host and moving them back and forth between host and accelerator. This is illustrated by the kernels shown here for reduction operations, where the intermediate results are created only on the device and never on the host. In kernel ComputeParallel1, a temporary accumulator is created on the host and all work-items put their intermediate results in it. This accumulator is brought back to the host and then further reduced (at line 37).
float ComputeParallel1(sycl::queue &q, std::vector<float> &data) {
const size_t data_size = data.size();
float sum = 0;
static float *accum = 0;
if (data_size > 0) {
const sycl::property_list props = {sycl::property::buffer::use_host_ptr()};
int num_EUs =
q.get_device().get_info<sycl::info::device::max_compute_units>();
int vec_size =
q.get_device()
.get_info<sycl::info::device::native_vector_width_float>();
int num_processing_elements = num_EUs * vec_size;
int BATCH = (N + num_processing_elements - 1) / num_processing_elements;
sycl::buffer<float> buf(data.data(), data.size(), props);
sycl::buffer<float> accum_buf(accum, num_processing_elements, props);
if (!accum)
accum = new float[num_processing_elements];
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor accum_acc(accum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(num_processing_elements, [=](auto index) {
size_t glob_id = index[0];
size_t start = glob_id * BATCH;
size_t end = (glob_id + 1) * BATCH;
if (end > N)
end = N;
float sum = 0.0;
for (size_t i = start; i < end; i++)
sum += buf_acc[i];
accum_acc[glob_id] = sum;
});
});
q.wait();
sycl::host_accessor h_acc(accum_buf);
for (int i = 0; i < num_processing_elements; i++)
sum += h_acc[i];
}
return sum;
} // end ComputeParallel1
An alternative approach is to keep this temporary accumulator on the accelerator and launch another kernel with only one work-item, which will perform this final reduction operation on the device as shown in the following ComputeParallel2 kernel on line 36. Note that this kernel does not have much parallelism and so it is executed by just one work-item. On some platforms this might be better than transferring the data back to the host and doing the reduction there.
float ComputeParallel2(sycl::queue &q, std::vector<float> &data) {
const size_t data_size = data.size();
float sum = 0;
static float *accum = 0;
if (data_size > 0) {
const sycl::property_list props = {sycl::property::buffer::use_host_ptr()};
int num_EUs =
q.get_device().get_info<sycl::info::device::max_compute_units>();
int vec_size =
q.get_device()
.get_info<sycl::info::device::native_vector_width_float>();
int num_processing_elements = num_EUs * vec_size;
int BATCH = (N + num_processing_elements - 1) / num_processing_elements;
sycl::buffer<float> buf(data.data(), data.size(), props);
sycl::buffer<float> accum_buf(accum, num_processing_elements, props);
sycl::buffer<float> res_buf(&sum, 1, props);
if (!accum)
accum = new float[num_processing_elements];
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor accum_acc(accum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(num_processing_elements, [=](auto index) {
size_t glob_id = index[0];
size_t start = glob_id * BATCH;
size_t end = (glob_id + 1) * BATCH;
if (end > N)
end = N;
float sum = 0.0;
for (size_t i = start; i < end; i++)
sum += buf_acc[i];
accum_acc[glob_id] = sum;
});
});
q.submit([&](auto &h) {
sycl::accessor accum_acc(accum, h, sycl::read_only);
sycl::accessor res_acc(res_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(1, [=](auto index) {
res_acc[index] = 0;
for (size_t i = 0; i < num_processing_elements; i++)
res_acc[index] += accum_acc[i];
});
});
}
// Buffers go out of scope and data gets transferred from device to host
return sum;
} // end ComputeParallel2
Overlapping Data Transfer from Host to Device with Computation on Device
Some GPUs provide specialized engines for copying data from host to device. Effective utilization of them will ensure that the host-to-device data transfer can be overlapped with execution on the device. In the following example, a block of memory is divided into chunks and each chunk is transferred to the accelerator (line 57), processed (line 60), and the result (line 63) is brought back to the host. These chunks of three tasks are independent, so they can be processed in parallel depending on availability of hardware resources. In systems where there are copy engines that can be used to transfer data between host and device, we can see that the operations from different loop iterations can execute in parallel. The parallel execution can manifest in two ways:
Between two memory copies, where one is executed by the GPU Vector Engines and one by a copy engine, or both are executed by copy engines.
Between a memory copy and a compute kernel, where the memory copy is executed by the copy engine and the compute kernel by the GPU Vector Engines.
#include <CL/sycl.hpp>
#define NITERS 10
#define KERNEL_ITERS 10000
#define NUM_CHUNKS 10
#define CHUNK_SIZE 10000000
class Timer {
public:
Timer() : start_(std::chrono::steady_clock::now()) {}
double Elapsed() {
auto now = std::chrono::steady_clock::now();
return std::chrono::duration_cast<Duration>(now - start_).count();
}
private:
using Duration = std::chrono::duration<double>;
std::chrono::steady_clock::time_point start_;
};
int main() {
const int num_chunks = NUM_CHUNKS;
const int chunk_size = CHUNK_SIZE;
const int iter = NITERS;
sycl::queue q;
// Allocate and initialize host data
float *host_data[num_chunks];
for (int c = 0; c < num_chunks; c++) {
host_data[c] = sycl::malloc_host<float>(chunk_size, q);
float val = c;
for (int i = 0; i < chunk_size; i++)
host_data[c][i] = val;
}
std::cout << "Allocated host data\n";
// Allocate and initialize device memory
float *device_data[num_chunks];
for (int c = 0; c < num_chunks; c++) {
device_data[c] = sycl::malloc_device<float>(chunk_size, q);
float val = 1000.0;
q.fill<float>(device_data[c], val, chunk_size);
}
q.wait();
std::cout << "Allocated device data\n";
Timer timer;
for (int it = 0; it < iter; it++) {
for (int c = 0; c < num_chunks; c++) {
auto add_one = [=](auto id) {
for (int i = 0; i < KERNEL_ITERS; i++)
device_data[c][id] += 1.0;
};
// Copy-in not dependent on previous event
auto copy_in =
q.memcpy(device_data[c], host_data[c], sizeof(float) * chunk_size);
// Compute waits for copy_in
auto compute = q.parallel_for(chunk_size, copy_in, add_one);
auto cg = [=](auto &h) {
h.depends_on(compute);
h.memcpy(host_data[c], device_data[c], sizeof(float) * chunk_size);
};
// Copy out waits for compute
auto copy_out = q.submit(cg);
}
q.wait();
}
auto elapsed = timer.Elapsed() / iter;
for (int c = 0; c < num_chunks; c++) {
for (int i = 0; i < chunk_size; i++) {
if (host_data[c][i] != (float)((c + KERNEL_ITERS * iter))) {
std::cout << "Mismatch for chunk: " << c << " position: " << i
<< " expected: " << c + 10000 << " got: " << host_data[c][i]
<< "\n";
break;
}
}
}
std::cout << "Time = " << elapsed << " usecs\n";
}
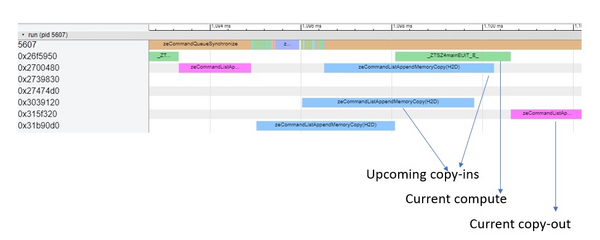
In the timeline picture below, which is collected using onetrace, we can see that copy-ins from upcoming iterations overlap with the execution of compute kernel. Also, we see multiple copy-ins executing in parallel on multiple copy engines.
In the example above, we cannot have two kernels (even though they are independent) executing concurrently because we only have one GPU. (It is possible to partition the GPU into smaller chunks and execute different kernels concurrently on them.)