A newer version of this document is available. Customers should click here to go to the newest version.
oneapi::mkl::sparse::matmat
Computes a sparse matrix-sparse matrix product.
Description
The oneapi::mkl::sparse::matmat routine computes a sparse matrix-sparse matrix product defined as
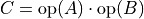
where 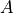 ,
, 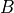 , and
, and 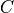 are appropriately-sized sparse matrices and
are appropriately-sized sparse matrices and 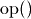 is a matrix modifier:
is a matrix modifier:
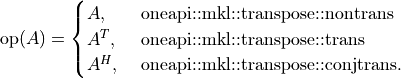
The sparse matrices are stored in the matrix_handle_t and currently only support the compressed sparse row (CSR) matrix format.
The output matrix is not guaranteed to be sorted on exit from sparse::matmat(), but a helper function sparse::sort_matrix() is provided if that is a necessary property for subsequent usage.
The matrix needs to be in sorted state prior to the call to sparse::matmat().
The matrix does not require a sorted state, but performance can benefit from it.
As the size of and its data is generally not known beforehand, the matmat routine is broken into several stages which allow you to query the size of the data arrays, allocate them and then pass them back into the routine to be filled. This enables you to control all the matrix data allocations themselves. Additionally, there are cases where only the sparsity pattern of is desired, and this routine enables you to compute without the values array. Generally the sparse::matmat() algorithm is broken into three computational stages:
Stage |
Description |
|---|---|
work_estimation |
do initial estimation of work and load balancing (make upper bound estimate on size of C matrix data). |
compute/compute_structure |
do internal products for computing the C matrix including the calculation of size of C matrix data and filling the row pointer array for C. |
finalize/finalize_structure |
do any remaining internal products and accumulation and transfer into final C matrix arrays. |
Some additional helper stages are provided to allow you to query sizes of temporary workspace arrays or the size of the matrix data (nnz(C)) to be allocated. They are set and passed to the sparse::matmat routine as matmat_request enum values:
namespace oneapi::mkl::sparse {
enum class matmat_request : std::int32_t {
get_work_estimation_buf_size,
work_estimation,
get_compute_structure_buf_size,
compute_structure,
finalize_structure,
get_compute_buf_size,
compute,
get_nnz,
finalize
};
}A common workflow involves calling sparse::matmat() several times with different matmat_request’s:
-
- Before matmat stages
-
-
-
Allocate
matrix row pointer array and input into
matrix
-
handle with dummy arguments for column and data arrays (as their sizes are not known yet).
-
Allocate
-
-
- work_estimation stage
-
Call matmat with matmat_request::get_work_estimation_buf_size.
Allocate the work estimation temporary workspace array.
Call matmat with matmat_request::work_estimation.
-
- Compute stage
-
Call matmat with matmat_request::get_compute_buf_size.
Allocate the compute temporary workspace array.
Call matmat with matmat_request::compute.
-
- Finalize stage
-
Call matmat with matmat_request::get_nnz.
Allocate the
matrix column and data arrays and input into C matrix handle.Call matmat with matmat_request::finalize.
-
- After matmat stages
-
Release or reuse the matmat descriptor for another appropriate sparse matrix product.
-
- Release any temporary workspace arrays allocated through the stages for this
-
particular sparse matrix product.
Release or use
matrix handle for subsequent operations.
Note that the compute_structure and finalize_structure and their helpers can be used if the final result desired is purely the sparsity pattern of .
If you do not wish to handle the allocation and memory management of the temporary workspace arrays, there is a simplifying option to skip the get_xxx_buf_size queries for the work_estimation and compute/compute_structure stages and pass in null pointers for the sizeTempBuffer and tempBuffer arguments in the API for those stages. In this case, the library handles the allocation and memory management of the temporary arrays themselves. The internally allocated temporary arrays will live until the matrix handle is destroyed. However, you are always expected to query the size of matrix data and allocate the matrix arrays themselves.
This simplified workflow is reflected here:
-
- Before matmat stages
-
-
-
Allocate
matrix row_pointer array and input into
matrix handle with
-
dummy arguments for column and data arrays (as their sizes are not known yet).
-
Allocate
-
-
- work_estimation stage
-
-
- Call matmat with the matmat_request::work_estimation and nullptr for
-
sizeTempBuffer and tempBuffer arguments.
-
-
- Compute stage
-
-
- Call matmat with matmat_request::compute and nullptr for the sizeTempBuffer
-
and tempBuffer arguments.
-
-
- Finalize stage
-
Call matmat with matmat_request::get_nnz.
-
-
Allocate the
matrix column and data arrays and input into
-
matrix handle.
-
Allocate the
Call matmat with matmat_request::finalize.
-
- After matmat stages
-
Release or reuse the matmat descriptor for another appropriate sparse matrix product.
Release or use the
matrix handle for subsequent operations.
These two workflows, and additionally, an example of computing only the sparsity pattern for are demonstrated in the oneMKL DPC++ examples listed below.
API
Syntax
Using SYCL buffers:
namespace oneapi::mkl::sparse {
void matmat(sycl::queue &queue,
sparse::matrix_handle_t A,
sparse::matrix_handle_t B,
sparse::matrix_handle_t C,
sparse::matmat_request req,
sparse::matmat_descr_t descr,
sycl::buffer<std::int64_t, 1> *sizeTempBuffer,
sycl::buffer<std::uint8_t, 1> *tempBuffer);
}Using USM pointers:
namespace oneapi::mkl::sparse {
sycl::event matmat(sycl::queue &queue,
sparse::matrix_handle_t A,
sparse::matrix_handle_t B,
sparse::matrix_handle_t C,
sparse::matmat_request req,
sparse::matmat_descr_t descr,
std::int64_t *sizeTempBuffer,
void *tempBuffer,
const std::vector<sycl::event> &dependencies);
}Include Files
oneapi/mkl/spblas.hpp
Input Parameters
- queue
-
Specifies the SYCL command queue which will be used for SYCL kernels execution.
- A
-
The matrix handle for the first matrix in the sparse matrix - sparse matrix product. Matrix
Does not need to be be in a sorted state as input to sparse::matmt() but performance may benefit from it. - B
-
The matrix handle for the second matrix in the sparse matrix - sparse matrix product. Matrix
currently must be in a sorted state as input to sparse::matmat(). To ensure the sorted property, use sparse::sort_matrix().NOTE:We plan to remove this sorted restriction in a future release. - C
-
The output matrix handle from the matmat operation. The sparse matrix format arrays will be allocated by the user and put into the matrix handle using a sparse::set_<xyz>_data routine. The data will be filled by the library as part of the matmat operation. Note that the output matrix may not be sorted, so for user convenience, we provide the api sparse::sort_matrix().
- request
-
The matmat_request stage in the multi-stage algorithm. See descriptions of common workflows above.
- descr
-
The matmat_descr_t object describing the sparse matrix-sparse matrix operation to be executed. It is manipulated using the sparse::init_matmat_descr, sparse::set_matmat_data and sparse::release_matmat_descr routines.
- sizeTempBuffer
-
A SYCL aware container (sycl::buffer or host-accessible USM pointer) of the length of one std::int64_t to represent the size in bytes of the tempBuffer. For the matmat_request stages with the get_xyz naming convention the value is set by the library to inform the user how much memory to allocate in the temporary buffer. In the other work_estimation and compute/comute_structure stages, it is passed in along with the temporary buffer, tempBuffer, informing the library how much space was provided in bytes.
For sycl::buffer inputs, sizeTempBuffer is of type sycl::buffer<std::int64_t>.
For USM inputs, sizeTempBuffer must be host-accessible and of std::int64_t * type. The recommended USM memory type is described in the following table. In general, using USM host memory will provide better performance than USM shared, but both are supported as they are both host accessible.
sizeTempBuffer
filled in stage
size (in bytes) of which array(s)
USM Memory Type
size_temp_buffer1
get_work_estimation_buf_size
temp_buffer1 in work_estimation
host accessible (USM host or USM shared)
size_temp_buffer2
get_compute_buf_size or get_compute_structure_buf_size
temp_buffer2 in compute or compute_structure
host accessible (USM host or USM shared)
nnz_buffer
get_nnz
C colind/values arrays for finalize|finalize_structure
host accessible (USM host or USM shared)
- tempBuffer
-
A SYCL-aware container (sycl::buffer or device-accessible USM pointer) of sizeTempBuffer bytes used as a temporary workspace in the algorithm. There are two stages where separate workspaces must be passed into the matmat api (work_estimation and compute/compute_structure). They must remain valid through the full matmat multi-stage algorithm as both may be used until the last finalize/finalize_structure request is completed.
For sycl::buffer inputs, tempBuffers is of type sycl::buffer<std::uint8_t>.
For USM inputs, tempBuffers must be device-accessible and is passed in as a void * type. The recommended USM memory type is described in the following table. In general, using USM device memory will provide a better performance than USM shared which will give better performance than USM host in sparse::matmat(), but all are supported as they are all device accessible.
tempBuffer
array provided in stage
size of array set in stage
USM Memory Type
temp_buffer1
work_estimation
get_work_estimation_buf_size
device accessible (USM device or USM shared or USM host)
temp_buffer2
compute or compute_structure
get_compute_buf_size or get_compute_structure_buf_size
device accessible (USM device or USM shared or USM host)
- dependencies (for USM APIs only)
-
A vector of type std::vector<sycl::event> containing the list of events that the current stage of oneapi::mkl::sparse::matmat routine depends on.
Output Parameters
- C
-
Data arrays for
will be allocated by the user and filled by the library as part of the matmat algorithm.The output sparse matrix data arrays for
are not guaranteed to be sorted, and sparse::sort_matrix() is provided in case the sorted property is desired for subsequent operations with the output sparse matrix.
Return Values (USM Only)
- sycl::event
-
SYCL event which can be waited upon or added as a dependency for the completion of the stages of the matmat routine.
Examples
Some examples of how to use oneapi::mkl::sparse::matmat with SYCL buffers or USM can be found in the oneMKL installation directory, under:
share/doc/mkl/examples/sycl/sparse_blas/source/csr_matmat.cpp
share/doc/mkl/examples/sycl/sparse_blas/source/csr_matmat_simplified.cpp
share/doc/mkl/examples/sycl/sparse_blas/source/csr_matmat_structure_only.cppshare/doc/mkl/examples/sycl/sparse_blas/source/csr_matmat_usm.cpp
share/doc/mkl/examples/sycl/sparse_blas/source/csr_matmat_simplified_usm.cpp
share/doc/mkl/examples/sycl/sparse_blas/source/csr_matmat_structure_only_usm.cpp