A newer version of this document is available. Customers should click here to go to the newest version.
gemm_batch
Computes groups of matrix-matrix product with general matrices.
Description
The gemm_batch routines are batched versions of gemm, performing multiple gemm operations in a single call. Each gemm operation performs a matrix-matrix product with general matrices.
gemm_batch supports the following precisions:
Ta |
Tb |
Tc |
Ts |
|---|---|---|---|
sycl::half |
sycl::half |
sycl::half |
sycl::half |
sycl::half |
sycl::half |
float |
float |
oneapi::mkl::bfloat16 |
oneapi::mkl::bfloat16 |
oneapi::mkl::bfloat16 |
float |
oneapi::mkl::bfloat16 |
oneapi::mkl::bfloat16 |
float |
float |
std::int8_t |
std::int8_t |
std::int32_t |
float |
std::int8_t |
std::int8_t |
float |
float |
float |
float |
float |
float |
double |
double |
double |
double |
std::complex<float> |
std::complex<float> |
std::complex<float> |
std::complex<float> |
std::complex<double> |
std::complex<double> |
std::complex<double> |
std::complex<double> |
gemm_batch (Buffer Version)
Buffer version of gemm_batch supports only strided API.
Strided API
Strided API operation is defined as:
for i = 0 … batch_size – 1
A, B and C are matrices at offset i * stridea, i * strideb, i * stridec in a, b and c.
C = alpha * op(A) * op(B) + beta * C
end forwhere:
op(X) is one of op(X) = X, or op(X) = XT, or op(X) = XH
alpha and beta are scalars
A, B, and C are matrices
op(A) is m x k, op(B) is k x n, and C is m x n
For strided API, a, b and c buffers contains all the input matrices. The stride between matrices is given by the stride parameters. Total number of matrices in a, b and c buffers is given by batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major {
void gemm_batch(sycl::queue &queue,
oneapi::mkl::transpose transa,
oneapi::mkl::transpose transb,
std::int64_t m,
std::int64_t n,
std::int64_t k,
Ts alpha,
sycl::buffer<Ta,1> &a,
std::int64_t lda,
std::int64_t stridea,
sycl::buffer<Tb,1> &b,
std::int64_t ldb,
std::int64_t strideb,
Ts beta,
sycl::buffer<Tc,1> &c,
std::int64_t ldc,
std::int64_t stridec,
std::int64_t batch_size,
compute_mode mode = compute_mode::unset)
}namespace oneapi::mkl::blas::row_major {
void gemm_batch(sycl::queue &queue,
oneapi::mkl::transpose transa,
oneapi::mkl::transpose transb,
std::int64_t m,
std::int64_t n,
std::int64_t k,
Ts alpha,
sycl::buffer<Ta,1> &a,
std::int64_t lda,
std::int64_t stridea,
sycl::buffer<Tb,1> &b,
std::int64_t ldb,
std::int64_t strideb,
Ts beta,
sycl::buffer<Tc,1> &c,
std::int64_t ldc,
std::int64_t stridec,
std::int64_t batch_size,
compute_mode mode = compute_mode::unset)
}Input Parameters
- queue
-
The queue where the routine should be executed.
- transa
-
Specifies op(A), transposition operation applied to matrices A. See Data Types for more details.
- transb
-
Specifies op(B), transposition operation applied to matrices B. See Data Types for more details.
- m
-
Number of rows of matrices op(A) and matrices C. Must be at least zero.
- n
-
Number of columns of matrices op(B) and matrices C. Must be at least zero.
- k
-
Number of columns of matrices op(A) and rows of matrices op(B). Must be at least zero.
- alpha
-
Scaling factor for matrix-matrix products.
- a
-
Buffer holding input matrices A. Size of the buffer must be at least stridea * batch_size.
- lda
-
Leading dimension of matrices A. Must be positive.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least m
Must be at least k
Row major
Must be at least k
Must be at least m
- stridea
-
Stride between two consecutive A matrices.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least lda * k
Must be at least lda * m
Row major
Must be at least lda * m
Must be at least lda * k
- b
-
Buffer holding input matrices B. Size of the buffer must be at least strideb * batch_size.
- ldb
-
Leading dimension of matrices B. Must be positive.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least k
Must be at least n
Row major
Must be at least n
Must be at least k
- strideb
-
Stride between two consecutive B matrices.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least ldb * n
Must be at least ldb * k
Row major
Must be at least ldb * k
Must be at least ldb * n
- beta
-
Scaling factor for matrices C.
- c
-
Buffer holding input/output matrices C. Size of the buffer must be at least stridec * batch_size.
- ldc
-
Leading dimension of matrices C. Must be positive.
Column major
Must be at least m
Row major
Must be at least n
- stridec
-
Stride between two consecutive C matrices.
Column major
Must be at least ldc * n
Row major
Must be at least ldc * m
- batch_size
-
Specifies the number of matrix multiply operations to perform. Must be at least zero.
- mode
-
Optional. Compute mode settings. See Compute Modes for more details.
Output Parameters
- c
-
Output buffer overwritten by batch_sizegemm operations of the form alpha * op(A) * op(B) + beta * C.
gemm_batch (USM Version)
USM version of gemm_batch supports group API and strided API.
Group API
The type Ti of integer pointers in the group API may be either std::int64_t or std::int32_t.
Group API operation is defined as:
idx = 0
for i = 0 … group_count – 1
for j = 0 … group_size – 1
A, B, and C are matrices in a[idx], b[idx] and c[idx]
C = alpha[i] * op(A) * op(B) + beta[i] * C
idx = idx + 1
end for
end forwhere:
op(X) is one of op(X) = X, or op(X) = XT, or op(X) = XH
alpha and beta are scalars
A, B, and C are matrices
op(A) is m x k, op(B) is k x n, and C is m x n
For group API, a, b and c arrays contain the pointers for all the input matrices. The total number of matrices in a, b and c are given by:
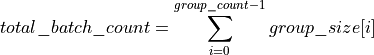
Group API supports both pointer and span inputs.
The advantage of using span instead of pointer is that the sizes of the array can vary and the size of the span can be queried at runtime. For each gemm parameter, except the output matrices, span can be of size 1, the number of groups or the total batch size. For output matrices, to ensure all computation are independent, size of the span must be the total batch size.
Depending on the size of spans, each parameter for the gemm computation is used as follows:
span size = 1 |
Parameter is reused for all gemm computations |
span size = group_count |
Parameter is reused for all gemm within a group. Each group will have a different value for this parameter. This is same as gemm_batch group API with pointers. |
span size = total_batch_count |
Each gemm computation use a different value for this parameter. |
Syntax
namespace oneapi::mkl::blas::column_major {
sycl::event gemm_batch(sycl::queue &queue,
const oneapi::mkl::transpose *transa,
const oneapi::mkl::transpose *transb,
const Ti *m,
const Ti *n,
const Ti *k,
const Ts *alpha,
const Ta **a,
const Ti *lda,
const Tb **b,
const Ti *ldb,
const Ts *beta,
Tc **c,
const Ti *ldc,
std::int64_t group_count,
const Ti *group_size,
compute_mode mode = compute_mode::unset,
const std::vector<sycl::event> &dependencies = {})
sycl::event gemm_batch(sycl::queue &queue,
const sycl::span<oneapi::mkl::transpose> &transa,
const sycl::span<oneapi::mkl::transpose> &transb,
const sycl::span<std::int64_t> &m,
const sycl::span<std::int64_t> &n,
const sycl::span<std::int64_t> &k,
const sycl::span<Ts> &alpha,
const sycl::span<const Ta*> &a,
const sycl::span<std::int64_t> &lda,
const sycl::span<const Tb*> &b,
const sycl::span<std::int64_t> &ldb,
const sycl::span<Ts> &beta,
sycl::span<Tc*> &c,
const sycl::span<std::int64_t> &ldc,
size_t group_count,
const sycl::span<size_t> &group_sizes,
compute_mode mode = compute_mode::unset,
const std::vector<sycl::event> &dependencies = {})
}namespace oneapi::mkl::blas::row_major {
sycl::event gemm_batch(sycl::queue &queue,
const oneapi::mkl::transpose *transa,
const oneapi::mkl::transpose *transb,
const Ti *m,
const Ti *n,
const Ti *k,
const Ts *alpha,
const Ta **a,
const Ti *lda,
const Tb **b,
const Ti *ldb,
const Ts *beta,
Tc **c,
const Ti *ldc,
std::int64_t group_count,
const Ti *group_size,
compute_mode mode = compute_mode::unset,
const std::vector<sycl::event> &dependencies = {})
sycl::event gemm_batch(sycl::queue &queue,
const sycl::span<oneapi::mkl::transpose> &transa,
const sycl::span<oneapi::mkl::transpose> &transb,
const sycl::span<std::int64_t> &m,
const sycl::span<std::int64_t> &n,
const sycl::span<std::int64_t> &k,
const sycl::span<Ts> &alpha,
const sycl::span<const Ta*> &a,
const sycl::span<std::int64_t> &lda,
const sycl::span<const Tb*> &b,
const sycl::span<std::int64_t> &ldb,
const sycl::span<Ts> &beta,
sycl::span<Tc*> &c,
const sycl::span<std::int64_t> &ldc,
size_t group_count,
const sycl::span<size_t> &group_sizes,
compute_mode mode = compute_mode::unset,
const std::vector<sycl::event> &dependencies = {})
}Input Parameters
- queue
-
The queue where the routine should be executed.
- transa
-
Array or span of group_countoneapi::mkl::transpose values. transa[i] specifies op(A), the transposition operation applied to matrices A in group i. See Data Types for more details.
- transb
-
Array or span of group_countoneapi::mkl::transpose values. transb[i] specifies op(B), the transposition operation applied to matrices B in group i. See Data Types for more details.
- m
-
Array or span of group_count integers. m[i] specifies number of rows of matrices op(A) and matrices C in group i. All entries must be at least zero.
- n
-
Array or span of group_count integers. n[i] specifies number of columns of matrices op(B) and matrices C in group i. All entries must be at least zero.
- k
-
Array or span of group_count integers. k[i] specifies number of columns of matrices op(A) and rows of matrices op(B) in group i. All entries must be at least zero.
- alpha
-
Array or span of group_count scalar elements. alpha[i] specifies scaling factor for matrix-matrix products in group i.
- a
-
Array of total_batch_count pointers for input matrices A or span of total_batch_count input matrices A. See Matrix Storage for more details.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Size of array A[i] must be at least lda[i] * k[i]
Size of array A[i] must be at least lda[i] * m[i]
Row major
Size of array A[i] must be at least lda[i] * m[i]
Size of array A[i] must be at least lda[i] * k[i]
- lda
-
Array or span of group_count integers. lda[i] specifies leading dimension of matrices A in group i. Must be positive.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least m[i]
Must be at least k[i]
Row major
Must be at least k[i]
Must be at least m[i]
- b
-
Array of total_batch_count pointers for input matrices B or span of total_batch_count input matrices B. See Matrix Storage for more details.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Size of array B[i] must be at least ldb[i] * n[i]
Size of array B[i] must be at least ldb[i] * k[i]
Row major
Size of array B[i] must be at least ldb[i] * k[i]
Size of array B[i] must be at least ldb[i] * n[i]
- ldb
-
Array or span of group_count integers. ldb[i] specifies leading dimension of matrices B in group i. Must be positive.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least k[i]
Must be at least n[i]
Row major
Must be at least n[i]
Must be at least k[i]
- beta
-
Array or span of group_count scalar elements. beta[i] specifies scaling factor for matrices C in group i.
- c
-
Array of total_batch_count pointers for input/output matrices C or span of total_batch_count input/output matrices C. See Matrix Storage for more details.
Column major
Size of array C[i] must be at least ldc[i] * n[i]
Row major
Size of array C[i] must be at least ldc[i] * m[i]
- ldc
-
Array or span of group_count integers. ldc[i] specifies leading dimension of matrices C in group i. Must be positive.
Column major
Must be at least m[i]
Row major
Must be at least n[i]
- group_count
-
Number of groups. Must be at least zero.
- group_size
-
Array or span of group_count integers. group_size[i] specifies the number of gemm operations in group i. Each element in group_size must be at least zero.
- mode
-
Optional. Compute mode settings. See Compute Modes for more details.
- dependencies
-
Optional. List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
mode and dependencies may be omitted independently; it is not necessary to specify mode in order to provide dependencies.
Output Parameters
- c
-
Array of pointers to output matrices C overwritten by total_batch_countgemm operations of the form alpha * op(A) * op(B) + beta * C.
Return Values
Output event to wait on to ensure computation is complete.
Examples
An example of how to use USM version of gemm_batch can be found in oneMKL installation directory, under:
share/doc/mkl/examples/sycl/blas/source/gemm_batch.cppStrided API
Strided API operation is defined as:
for i = 0 … batch_size – 1
A, B and C are matrices at offset i * stridea, i * strideb, i * stridec in a, b and c.
C = alpha * op(A) * op(B) + beta * C
end forwhere:
op(X) is one of op(X) = X, or op(X) = XT, or op(X) = XH
alpha and beta are scalars
A, B, and C are matrices
op(A) is m x k, op(B) is k x n, and C is m x n
For strided API, a, b and c arrays contains all the input matrices. The stride between matrices is either given by the stride parameters. Total number of matrices in a, b and c arrays is given by batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major {
sycl::event gemm_batch(sycl::queue &queue,
oneapi::mkl::transpose transa,
oneapi::mkl::transpose transb,
std::int64_t m,
std::int64_t n,
std::int64_t k,
oneapi::mkl::value_or_pointer<Ts> alpha,
const Ta *a,
std::int64_t lda,
std::int64_t stridea,
const Tb *b,
std::int64_t ldb,
std::int64_t strideb,
oneapi::mkl::value_or_pointer<Ts> beta,
Tc *c,
std::int64_t ldc,
std::int64_t stridec,
std::int64_t batch_size,
compute_mode mode = compute_mode::unset,
const std::vector<sycl::event> &dependencies = {})
}namespace oneapi::mkl::blas::row_major {
sycl::event gemm_batch(sycl::queue &queue,
oneapi::mkl::transpose transa,
oneapi::mkl::transpose transb,
std::int64_t m,
std::int64_t n,
std::int64_t k,
oneapi::mkl::value_or_pointer<Ts> alpha,
const Ta *a,
std::int64_t lda,
std::int64_t stridea,
const Tb *b,
std::int64_t ldb,
std::int64_t strideb,
oneapi::mkl::value_or_pointer<Ts> beta,
Tc *c,
std::int64_t ldc,
std::int64_t stridec,
std::int64_t batch_size,
compute_mode mode = compute_mode::unset,
const std::vector<sycl::event> &dependencies = {})
}Input Parameters
- queue
-
The queue where the routine should be executed.
- transa
-
Specifies op(A), transposition operation applied to matrices A. See Data Types for more details.
- transb
-
Specifies op(B), transposition operation applied to matrices B. See Data Types for more details.
- m
-
Number of rows of matrices op(A) and matrices C. Must be at least zero.
- n
-
Number of columns of matrices op(B) and matrices C. Must be at least zero.
- k
-
Number of columns of matrices op(A) and rows of matrices op(B). Must be at least zero.
- alpha
-
Scaling factor for matrix-matrix products. See Scalar Arguments for more information on the value_or_pointer data type.
- a
-
Pointer to input matrices A. Size of the array must be at least stridea * batch_size.
- lda
-
Leading dimension of matrices A. Must be positive.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least m
Must be at least k
Row major
Must be at least k
Must be at least m
- stridea
-
Stride between two consecutive A matrices.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least lda * k
Must be at least lda * m
Row major
Must be at least lda * m
Must be at least lda * k
- b
-
Pointer to input matrices B. Size of the array must be at least strideb * batch_size.
- ldb
-
Leading dimension of matrices B. Must be positive.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least k
Must be at least n
Row major
Must be at least n
Must be at least k
- strideb
-
Stride between two consecutive B matrices.
transa = transpose::nontrans
transa = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least ldb * n
Must be at least ldb * k
Row major
Must be at least ldb * k
Must be at least ldb * n
- beta
-
Scaling factor for matrices C. See Scalar Arguments for more information on the value_or_pointer data type.
- c
-
Pointer to input/output matrices C. Size of the array must be at least stridec * batch_size.
- ldc
-
Leading dimension of matrices C. Must be positive.
Column major
Must be at least m
Row major
Must be at least n
- stridec
-
Stride between two consecutive C matrices.
Column major
Must be at least ldc * n
Row major
Must be at least ldc * m
- batch_size
-
Specifies the number of matrix multiply operations to perform. Must be at least zero.
- mode
-
Optional. Compute mode settings. See Compute Modes for more details.
- dependencies
-
Optional. List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
mode and dependencies may be omitted independently; it is not necessary to specify mode in order to provide dependencies.
Output Parameters
- c
-
Pointer to output matrices C overwritten by batch_sizegemm operations of the form alpha * op(A) * op(B) + beta * C.
Return Values
Output event to wait on to ensure computation is complete.