Visible to Intel only — GUID: GUID-98CDFF0B-8B8C-423F-AE6B-4CCDAA76C979
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-98CDFF0B-8B8C-423F-AE6B-4CCDAA76C979
Supported Fusion Patterns
Fusion Patterns
The following fusion patterns are subgraphs that the oneDNN Graph API recognizes as candidate for fusion. The patterns are described using oneDNN Graph operation (op) names with the following convention.
NOTE:
oneDNN Graph performs limited input validation to minimize the performance overheads. The application is responsible for sanitizing inputs passed to the library. For large u8 or s8 inputs may lead to accumulator overflow, you can use floating point patterns instead of quantized patterns.
"+" describes a chain of two ops. The preceding op produces an output tensor, which is consumed by the following op as its first operand.
"[]" describes a component of the overall pattern description. For example, it could include a subgraph or all the op choices within the bracket.
"|" describes choices of multiple operations, say A+[B|C] means the graph partition contains A followed by B or C.
"," describes a graph composed of multiple subgraphs, each subgraph marks its output tensor explicitly, which is consumed by other subgraphs.
Superscript denotes the numbers of repetition pattern. For example, A+[B|C]  means the graph partition contains A followed by three ops, each of them is either B or C. The superscript could be a range of number meaning allowing a range of repetition. If the range is between 0 and 1, we use superscript "?".
means the graph partition contains A followed by three ops, each of them is either B or C. The superscript could be a range of number meaning allowing a range of repetition. If the range is between 0 and 1, we use superscript "?".
Subscript denotes the input and output tensors which need to explicitly mark the producer and consumer relation within one graph partition. For example, A 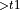 +B+C
+B+C  refers to the pattern started with A followed by B and C, and C takes an implicit input tensor from B and an extra tensor t1 output from A. ">" refers to the output tensor, and "<" for input tensor. Input and output tensor between neighbor ops are not explicitly marked, for example, B consumes t1 implicitly in the example above.
refers to the pattern started with A followed by B and C, and C takes an implicit input tensor from B and an extra tensor t1 output from A. ">" refers to the output tensor, and "<" for input tensor. Input and output tensor between neighbor ops are not explicitly marked, for example, B consumes t1 implicitly in the example above.
Subscript "out" marks the output tensor of a certain op to be the output of a graph partition. For example, in A +B 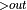 +C
+C  , B’s output and C’s output are marked as output tensors.
, B’s output and C’s output are marked as output tensors.
Subscript "in" marks the input tensor of a certain op to be the input of a graph partition. For example, in A  +B A’s input and B’s second input are graph partition input, and they share the same input tensor in1. Most input tensors of a graph partition are not explicitly marked. For example, the input tensors of the first op are implicitly regarded as graph partition inputs. Besides, for input tensors of other ops, if they are not produced by any proceeding ops, they are regarded as implicit graph partition inputs. In the example A +B+C , A’s inputs are regarded as implicit graph partition inputs, and if B is a binary operation, the second input tensor is an implicit graph partition input.
+B A’s input and B’s second input are graph partition input, and they share the same input tensor in1. Most input tensors of a graph partition are not explicitly marked. For example, the input tensors of the first op are implicitly regarded as graph partition inputs. Besides, for input tensors of other ops, if they are not produced by any proceeding ops, they are regarded as implicit graph partition inputs. In the example A +B+C , A’s inputs are regarded as implicit graph partition inputs, and if B is a binary operation, the second input tensor is an implicit graph partition input.
The following categories will be used in describing fusion pattern.
Unary = [Abs | Clamp | Elu | Exp | GELU | HardSwish | LeakyReLU | Log | Sigmoid | SoftPlus | Pow | ReLU | Round | Sqrt | Square | Tanh]
Binary = [Add | Divide | Maximum | Minimum | Multiply | Subtract]
Reduction = [ReduceL1 | ReduceL2 | ReduceMax | ReduceMean | ReduceMin | ReduceProd | ReduceSum]
Inference
Floating Point Patterns
Pattern |
Description |
|---|---|
Convolution + BiasAdd |
This pattern is widely used in Convolution Neural Networks, for example ResNet, ResNext, SSD, etc. |
ConvTranspose + BiasAdd |
This pattern is widely used in Generative Adversarial Networks. |
Interpolate + [Unary | Binary] |
This pattern is widely used for image processing. |
MatMul + BiasAdd |
This pattern is widely used in language models and recommendation models, for example BERT, DLRM, etc. |
Reduction + [Unary | Binary] |
This pattern is widely used for data processing, for example loss reduction. |
Unary + Binary |
This pattern is widely used in Convolution Neural Networks. |
Binary + [Unary | Binary] |
This pattern is widely used in Generative Adversarial Networks, for example ParallelWaveGAN. |
[AvgPool | MaxPool] + Binary |
This pattern is widely used in Convolution Neural Networks. |
BatchNormInference + ReLU |
This pattern is widely used in Convolution Neural Networks, for example DenseNet. |
Reciprocal + Multiply |
N/A |
Reorder + Add |
N/A |
 + BatchNormInference
+ BatchNormInference 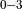
Quantized Patterns
Pattern |
Description |
|---|---|
Quantize |
N/A |
Quantize |
N/A |
Quantize |
N/A |
Dequantize + [AvgPool | MaxPool] + Quantize |
N/A |
Dequantize |
N/A |
Dequantize + Reorder + Quantize |
N/A |
Dequantize |
N/A |

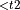 ]
] Training
Pattern |
Description |
|---|---|
ConvolutionBackwardWeights + BiasAddBackward |
N/A |
ReLUBackward + BatchNormTrainingBackward |
N/A |
All the above fusion patterns are supported by default.
Aggressive Fusion Patterns
Aggressive fusion patterns also follow the pattern description convention defined in the Fusion Patterns section.
NOTE:
Aggressive fusion patterns are only supported when Graph Compiler is enabled.
The following categories will also be used to describe aggressive fusion patterns.
ReshapeTranspose = [StaticReshape + StaticTranspose
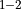 ]
]Activation = [ReLU | Sigmoid | GELU]
ActivationBackward = [ReLUBackward | SigmoidBackward | GELUBackward]
Inference
Floating Point Patterns
Pattern |
Description |
|---|---|
MatMul + [Multiply | Divide] + Add + Softmax + MatMul + StaticTranspose + Reorder |
Multi-head Attention. This pattern is widely used in models containing encoder-decoder structures, for example BERT. |
ReshapeTranspose |
Multi-head Attention. |
MatMul + Activation |
Multi-layer Perceptron. This pattern is widely used in recommendation models, for example DLRM. |
[Convolution + BiasAdd |
Identical Bottleneck. Enabled only in single thread runtime scenario. This pattern is widely used in Convolution Neural Networks, for example ResNet. |
Convolution + BiasAdd |
Convolutional Bottleneck. Enabled only in single thread runtime scenario. This pattern is widely used in Convolution Neural Networks, for example ResNet. |
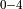 , MatMul
, MatMul  + ReLU]
+ ReLU] 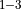 + Convolution + BiasAdd
+ Convolution + BiasAdd Quantized Patterns
Pattern |
Description |
|---|---|
Dequantize |
Quantized Multi-head Attention. |
Dequantize + ReshapeTranspose |
Quantized Multi-head Attention. |
Dequantize |
Quantized Multi-layer Perceptron. |
Dequantize |
Quantized Identical Bottleneck. Enabled only in single thread runtime scenario. |
[Dequantize |
Quantized Convolutional Bottleneck. Enabled only in single thread runtime scenario. |
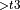 , Dequantize
, Dequantize 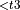 + Activation + Quantize
+ Activation + Quantize  , Dequantize
, Dequantize 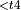 + Activation + Quantize
+ Activation + Quantize Training
Pattern |
Description |
|---|---|
Dequantize |
Multi-head Attention Training Forward Pattern. |
StaticReshape + StaticTranspose |
Multi-head Attention Training Backward Pattern. |
MatMul |
Multi-layer Perceptron Training Forward Pattern. |
StaticTranspose |
Multi-layer Perceptron Training Backward Pattern. |
Convolution |
Identical Bottleneck Training Forward Pattern. |
Convolution |
Convolutional Bottleneck Training Forward Pattern. |
ReLUBackward |
Identical Bottleneck Training Backward Pattern. |
ReLUBackward |
Convolutional Bottleneck Training Backward Pattern. |
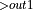 , Multiply
, Multiply 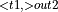 , MatMul
, MatMul 
 , [MatMul
, [MatMul  + Activation
+ Activation 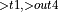 ]
] 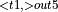 + Activation
+ Activation 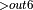
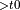 , ActivationBackward
, ActivationBackward  , ReduceSum
, ReduceSum 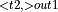 , StaticTranspose
, StaticTranspose  , [StaticTranspose
, [StaticTranspose 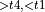 + MatMul
+ MatMul 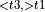 , ReduceSum
, ReduceSum 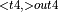 ]
] 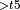 , ActivationBackward
, ActivationBackward  + MatMul
+ MatMul 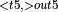 , ReduceSum
, ReduceSum  , StaticTranspose
, StaticTranspose 
 + ReLU
+ ReLU  + Convolution
+ Convolution  + BatchNormForwardTraining
+ BatchNormForwardTraining  + ReLU
+ ReLU  + BatchNormForwardTraining
+ BatchNormForwardTraining 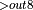 + Add + ReLU
+ Add + ReLU 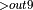
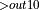 + Add
+ Add 
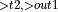 + ConvolutionBackwardData + ReLUBackward + BatchNormTrainingBackward
+ ConvolutionBackwardData + ReLUBackward + BatchNormTrainingBackward  + ConvolutionBackwardData + ReLUBackward + BatchNormTrainingBackward
+ ConvolutionBackwardData + ReLUBackward + BatchNormTrainingBackward 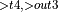 + ConvolutionBackwardData + Add
+ ConvolutionBackwardData + Add  , ConvolutionBackwardWeights
, ConvolutionBackwardWeights 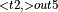 , ConvolutionBackwardWeights
, ConvolutionBackwardWeights 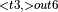 , ConvolutionBackwardWeights
, ConvolutionBackwardWeights 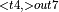
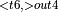 , BatchNormTrainingBackward
, BatchNormTrainingBackward 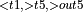 + ConvolutionBackwardData
+ ConvolutionBackwardData 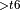 , ConvolutionBackwardWeights
, ConvolutionBackwardWeights 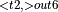 , ConvolutionBackwardWeights
, ConvolutionBackwardWeights 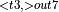 , ConvolutionBackwardWeights
, ConvolutionBackwardWeights 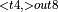 , ConvolutionBackwardWeights
, ConvolutionBackwardWeights 