Visible to Intel only — GUID: GUID-BFDCC5B4-68A1-4B4B-A5BC-642113F1BCA2
Convolution
Inner Product
Matrix Multiplication
General
Execution Arguments
Implementation Details
Implementation Limitations
Performance Tips
Examples
RNN
Batch Normalization
Binary
Concat
Eltwise
Group Normalization
Layer Normalization
Local Response Normalization (LRN)
Pooling
PReLU
Resampling
Shuffle
Softmax
Sum
Reorder
Reduction
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-BFDCC5B4-68A1-4B4B-A5BC-642113F1BCA2
Matrix Multiplication
General
The matrix multiplication (MatMul) primitive computes the product of two 2D tensors with optional bias addition (the variable names follow the standard Naming Conventions):
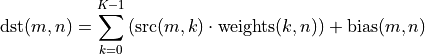
The MatMul primitive also supports batching multiple independent matrix multiplication operations, in which case the tensors can be up to 12D:
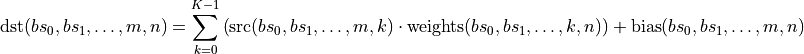
MatMul also supports implicit broadcast semantics i.e., 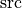 can be broadcasted into
can be broadcasted into 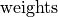 if the corresponding dimension in is 1 (and vice versa). However, all tensors (including
if the corresponding dimension in is 1 (and vice versa). However, all tensors (including 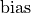 , if it exists) must have the same number of dimensions.
, if it exists) must have the same number of dimensions.
The shape of 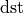 only depends on and tensors. The cannot change the dimensions of by broadcasting. In other words, for every dimension, the following constraint must hold true: dimension(bias) == dimension(dst) || dimension(bias) == 1.
only depends on and tensors. The cannot change the dimensions of by broadcasting. In other words, for every dimension, the following constraint must hold true: dimension(bias) == dimension(dst) || dimension(bias) == 1.
Execution Arguments
When executed, the inputs and outputs should be mapped to an execution argument index as specified by the following table.
Primitive input/output |
Execution argument index |
|---|---|
|
DNNL_ARG_SRC |
|
DNNL_ARG_WEIGHTS |
|
DNNL_ARG_BIAS |
|
DNNL_ARG_DST |
|
DNNL_ARG_ATTR_MULTIPLE_POST_OP(binary_post_op_position) | DNNL_ARG_SRC_1 |
|
DNNL_ARG_ATTR_MULTIPLE_POST_OP(prelu_post_op_position) | DNNL_ARG_WEIGHTS |
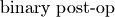
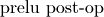
Implementation Details
General Notes
The MatMul primitive supports input and output tensors with run-time specified shapes and memory formats. The run-time specified dimensions or strides are specified using the DNNL_RUNTIME_DIM_VAL wildcard value during the primitive initialization and creation stage. At the execution stage, the user must pass fully specified memory objects so that the primitive is able to perform the computations. Note that the less information about shapes or format is available at the creation stage, the less performant execution will be. In particular, if the shape is not known at creation stage, one cannot use the special format tag dnnl::memory::format_tag::any to enable an implementation to choose the most appropriate memory format for the corresponding input or output shapes. On the other hand, run-time specified shapes enable users to create a primitive once and use it in different situations.
Inconsistency with dimensions being “primitive-creation-time-defined” vs “runtime-defined” is invalid. For example,
and with dimensions set to {3, 4, 4} and {DNNL_RUNTIME_DIM_VAL, 4, 4} respectively is invalid.The broadcasting shape consistency check is not done for the dimensions with DNNL_RUNTIME_DIM_VAL. It is user responsibility to make sure the dimensions for the tensors are valid.
Multiple batch dimensions and broadcasting of batch dimensions of src and weights are supported for both CPU and GPU engines.
Please check tutorials below to see DNNL_RUNTIME_DIM_VAL support in use.
Data Types
The MatMul primitive supports the following combinations of data types for source, destination, weights, and bias tensors:
Source |
Weights |
Destination |
Bias |
|---|---|---|---|
f32 |
f32 |
f32 |
f32 |
f16 |
f16 |
f16, u8, s8 |
f16, f32 |
bf16 |
bf16 |
f32, bf16 |
bf16, f32 |
u8, s8 |
s8 |
u8, s8, s32, f32, f16, bf16 |
u8, s8, s32, f32, f16, bf16 |
Data Representation
The MatMul primitive expects the following tensors:
Dims |
Source |
Weights |
Destination |
Bias |
|---|---|---|---|---|
2D |
M |
K |
M |
None or |
ND |
S |
W |
D |
None or B |
 K
K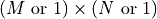
where for the sake of notational convenience, we have
The MatMul primitive is generally optimized for the case in which memory objects use plain memory formats. Additionally, the and must have at least one of the axes m or k and n or k contiguous (i.e., stride=1) respectively. However, it is recommended to use the placeholder memory format dnnl::memory::format_tag::any if an input tensor is reused across multiple executions. In this case, the primitive will set the most appropriate memory format for the corresponding input tensor.
The memory format of the destination tensor should always be plain with n axis contiguous. For example, dnnl::memory::format_tag::ab for the 2D case and dnnl::memory::format_tag::abc or dnnl::memory::format_tag::bac for the 3D one.
Attributes and Post-ops
Attributes and post-ops enable modifying the behavior of the MatMul primitive. The following attributes and post-ops are supported:
Type |
Operation |
Description |
Restrictions |
|---|---|---|---|
Attribute |
Scales the result by given scale factor(s) |
||
Attribute |
Sets zero point(s) for the corresponding tensors |
Int8 computations only |
|
Post-op |
Applies an Eltwise operation to the result |
||
Post-op |
Adds the operation result to the destination tensor instead of overwriting it |
||
Post-op |
Applies a Binary operation to the result |
General binary post-op restrictions |
|
Post-op |
Applies an PReLU operation to the result |
The following masks are supported by the primitive:
0, which applies one scale / zero point value to an entire tensor, and
2, which applies a scale value per column along the n dimension for DNNL_ARG_WEIGHTS.
When scales and/or zero-points masks are specified, the user must provide the corresponding scales and/or zero-points as additional input memory objects with argument DNNL_ARG_ATTR_SCALES | DNNL_ARG_${MEMORY_INDEX} or DNNL_ARG_ATTR_ZERO_POINTS | DNNL_ARG_${MEMORY_INDEX} during the execution stage. For instance, a source tensor zero points memory argument would be passed with index (DNNL_ARG_ATTR_ZERO_POINTS | DNNL_ARG_SRC).
NOTE:
Please check tutorials below to see run-time attributes in use.
Implementation Limitations
Check Data Types.
GPU
Supports up to 6 dimensions.
Source zero point mask of 0 is only supported.
Sum post-op doesn’t support data type other than destination data type.
Bias of bf16 data type is supported for configuration with bf16 source data type and weights bf16 data type, and up to three dimensional matrices.
Configuration with int8 source data type, s8 weight data type and bf16 destination data type don’t support:
Destination zero point.
Runtime dimensions.
Three and higher dimensional matrices.
CPU
Configuration with int8 source data type, s8 weight data type and f16 destination data type isn’t supported.
Performance Tips
Use dnnl::memory::format_tag::any for either of the input tensors if and only if the shape of the corresponding tensor is fully known at creation time and it is possible to cache reordered tensors across multiple primitive executions. For instance, a good candidate for reuse are the weights tensors during inference: their shapes and data types are known in advance; thus they can be reordered during the first inference pass and can be reused during the subsequent passes. However, if any of the input tensors cannot be reused, it is best to force the primitive to use the same format as that used by the tensors.
Examples
The following examples are available:
Matrix Multiplication Primitive Examples
MatMul Primitive Example
This C++ API example demonstrates how to create and execute a MatMul primitive.
Key optimizations included in this example:
Primitive attributes with fused post-ops.
MatMul Tutorial: Comparison with SGEMM (CPU only)
C++ API example demonstrating MatMul as a replacement for SGEMM functions.
Concepts:
Create primitive once, use multiple times
Run-time tensor shapes: DNNL_RUNTIME_DIM_VAL
MatMul Tutorial: INT8 Inference
C++ API example demonstrating how one can use MatMul fused with ReLU in INT8 inference.
Concepts:
Asymmetric quantization
Zero points: dnnl::primitive_attr::set_zero_points_mask()
Create primitive once, use multiple times
Run-time tensor shapes: DNNL_RUNTIME_DIM_VAL
Weights pre-packing: use dnnl::memory::format_tag::any
MatMul Tutorial: Quantization (CPU only)
C++ API example demonstrating how one can perform reduced precision matrix-matrix multiplication using MatMul and the accuracy of the result compared to the floating point computations.
Concepts:
Static and dynamic quantization
Asymmetric quantization
Zero points: dnnl::primitive_attr::set_zero_points_mask()