Intel® oneAPI Deep Neural Network Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-04A1D9A9-56D1-405B-A6DE-B12DCDA19E02
Visible to Intel only — GUID: GUID-04A1D9A9-56D1-405B-A6DE-B12DCDA19E02
Primitive Attributes: Post-ops
oneDNN implements some basic capabilities of operation fusion using the post-ops attributes API. The operation fusion typically reduces the memory bandwidth pressure hence leading to higher performance.
Post-ops are operations that are appended after a primitive. They are implemented using the Primitive Attributes mechanism. If there are multiple post-ops, they are executed in the order they have been appended.
Currently the following post-ops are supported by the library:
Just like Primitive Attributes, the post-ops are represented by an opaque structure (dnnl_post_ops_t in C API and dnnl::post_ops in C++ API) which is copied once it is attached to the attributes using the C++ dnnl::primitive_attr::set_post_ops or C dnnl_primitive_attr_set_post_ops functions. The attributes then must be passed to a primitive descriptor creation function to take effect. Below is a simple skeleton for the C++ API:
dnnl::post_ops po; // default empty post-ops assert(po.len() == 0); // no post-ops attached po.append_SOMETHING(params); // append some particular post-op po.append_SOMETHING_ELSE(other_params); // append one more post-op // (!) Note that the order in which post-ops are appended matters! assert(po.len() == 2); dnnl::primitive_attr attr; // default attributes attr.set_post_ops(po); // attach the post-ops to the attr // further po changes would not affect attr primitive::primitive_desc op_pd(engine, params, attr); // create a pd with the attr
The post-op object can be inspected using the dnnl::post_ops::kind() function that takes an index of the post-op (which must be less than the value returned by dnnl::post_ops::len()), and returns its kind.
Supported Post-ops
Eltwise Post-op
The eltwise post-op enables fusing a primitive with an Eltwise primitive. This is probably one of the most popular kinds of fusion: an eltwise (typically an activation function) with preceding convolution or inner product.
The dnnl::primitive::kind of this post-op is dnnl::primitive::kind::eltwise.
API:
The parameters (C++ API for simplicity):
void dnnl::post_ops::append_eltwise( algorithm alg, float alpha, float beta // same as in eltwise primitive );
The alg, alpha, and beta parameters are the same as in Eltwise.
The eltwise post-op replaces:
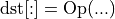
with
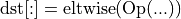
The intermediate result of 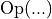 is not preserved. Hence, in most cases this kind of fusion cannot be used during training.
is not preserved. Hence, in most cases this kind of fusion cannot be used during training.
Sum Post-op
The sum post-op accumulates the result of a primitive with the existing data. Prior to accumulating the result, the existing value would be shifted by the zero point and multiplied by scale.
The kind of this post-op is dnnl::primitive::kind::sum.
This feature might improve performance for cases like residual learning blocks, where the result of a convolution is accumulated to the previously computed activations. The scale and zero point parameters can be used in the following scenarios:
INT8 inference when the result and previous activations have different magnitudes. The data_type of the sum operand should be one of s32, s8 or u8
Beta parameter using scale (for example, GEMM beta parameter). In this scenario zero point must be 0.
The sum post-op replaces
with
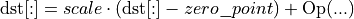
If the data type parameter is specified, the original destination tensor will be reinterpreted as a tensor with the provided data type. Because it is a reinterpretation, data_type and the destination data type must have the same size. As a result, the computation will be:
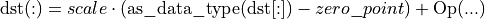
- GPU
Currently only a u8/s8 data type parameter is supported.
Zero point is not supported.
Depthwise Post-op
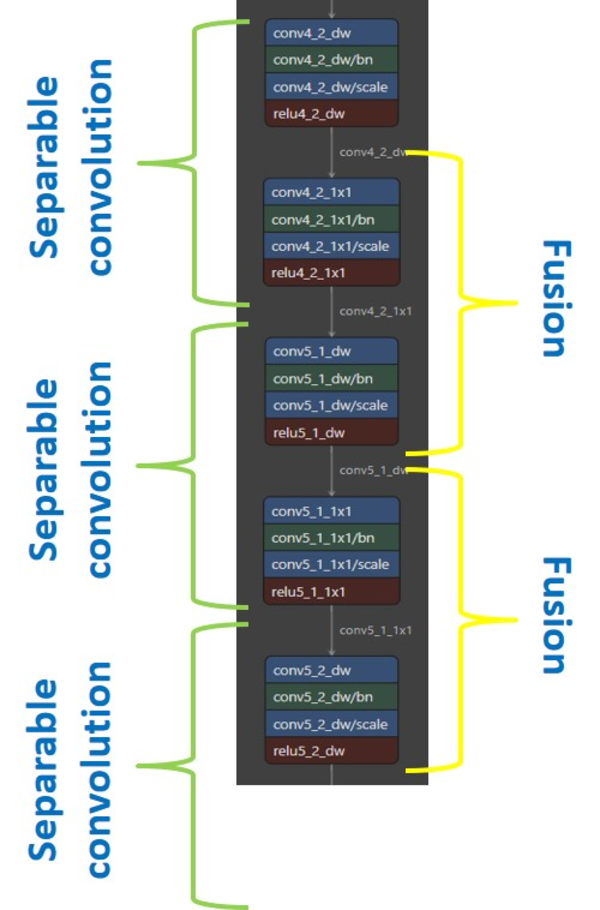
Appends a Depthwise convolution as a post-op. This post-op can only be fused with 1x1 convolution as generally seen in models (like MobileNet_v1) that use a stack of Separable convolutions: Depthwise convolution followed by 1x1 convolution. The stack of these Separable convolutions (like in MobileNet_v1) provide an opportunity to fuse 1x1-Convolution with bandwidth-limited Depthwise convolution.
The dnnl::primitive::kind of this post-op is dnnl::primitive::kind::convolution.
API:
For better readability, below we assume a 2D convolution and use the following notations:
conv_1x1 Convolution with weights spatial=1 i.e., kh = kw = 1.
conv_dw Depthwise convolution with weights spatial=3 i.e., kh = kw = 3, g = oc = ic and pad_l = pad_r = {1, 1}.
The Depthwise post-op replaces
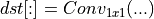
with
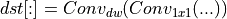
The final output dimensions of the after post-op is defined as
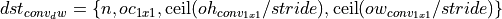
where oh_conv_1x1, ow_conv_1x1 are height and width of conv_1x1 destination.
Supported data types
conv 1x1 output data type |
depthwise post-op output data type |
depthwise post-op weights data type |
depthwise post-op bias data type |
|---|---|---|---|
u8, s8 |
u8, s8, s32, f32 |
s8 |
f32, s32 |
f32 |
f32 |
f32 |
f32 |
bf16 |
bf16, f32 |
bf16 |
f32, bf16 |
f16 |
f16, f32 |
f16 |
f32, f16 |
- Though it is called a post-operation type, it does not follow the post-operation convention which implies an application of operation in f32 data type.
Currently only supported for 2D 1x1 convolution.
Sum or another depthwise post-ops cannot be a part of post-op chain.
The dst_1x1, wei_dw and dst_dw are assumed to be dnnl_format_tag_any.
Operation descriptor for base 1x1 convolution requires spatial dimensions of destination memory descriptor to coincide with source spatial dimensions. It is important for cases when depthwise post-op stride is not equal to 1. In this case, the queried destination descriptor after fusion will not coincide with the one passed to base convolution. It means that if intermediate object is utilized in other places in user application, its lifetime has to be handled by user separately since the library does not provide a mechanism to query an intermediate output of base convolution.
Currently, f16 support for depthwise fusion is only through reference fusion implementation. Thus, performance gain is not expected for this data type.
Binary Post-op
The binary post-op enables fusing a primitive with a Binary primitive.
The dnnl::primitive::kind of this post-op is dnnl::primitive::kind::binary.
API:
The parameters (C++ API for simplicity):
void dnnl::post_ops::append_binary( algorithm alg, // binary algorithm to apply const memory::desc &src1 // memory descriptor for a second memory operand );
The alg and src1 parameters are the same as in Binary.
The binary post-op replaces:
with
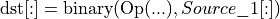
The intermediate result of is not preserved. Hence, in most cases this kind of fusion cannot be used during training.
Currently the following scenarios are optimized:
Per tensor broadcast, when
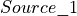 is represented as a one-element tensor, i.e. {1, 1, 1, 1} for 2D spatial .
is represented as a one-element tensor, i.e. {1, 1, 1, 1} for 2D spatial .Per channels (i.e. dimension 1) broadcast, when a dim[1] value of
coincides with a dim[1] value of , i.e. {1, C, 1, 1} for 2D spatial .Per element broadcast, when
coincides with . In this case user may create src1 memory descriptor with format_tag::any or set a specific tag. However, in later case if tags mismatch with , it would result in suboptimal performance. In case of using format_tag::any, a primitive descriptor of the operation will initialize a memory descriptor for binary post-operation which format may be queried from attributes using dnnl::post_ops::get_params_binary(...) function call.
Prelu Post-op
The prelu post-op enables fusing a primitive with a PReLU primitive.
The dnnl::primitive::kind of this post-op is dnnl::primitive::kind::prelu.
API:
The parameters (C++ API for simplicity):
void dnnl::post_ops::append_prelu( int mask /*mask describing prelu weights broadcast.*/);
The prelu post-op replaces:
with
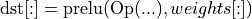
Assumptions:
the weights tensor is passed in runtime using DNNL_ARG_ATTR_MULTIPLE_POST_OP(index) | DNNL_ARG_WEIGHTS mechanism, where index is the sequence number of the prelu in post-operations chain;
only fp32 weights tensor data type is supported;
only plain layout (a, ab, acb, acdb, acdeb) is supported for weights tensor;
mask defines the correspondence between the output tensor dimensions and the prelu weights tensor. The set i-th bit indicates that a dedicated weights value is used for each index along that dimension. Mask 0 value means common (scalar) weights value for the whole output tensor.
the order of dimensions does not depend on how elements are laid out in memory. For example:
for a 2D CNN activations tensor the order is always (n, c)
for a 4D CNN activations tensor the order is always (n, c, h, w)
Examples of Chained Post-ops
Different post-ops can be chained together by appending one after another. Note that the order matters: the post-ops are executed in the order they have been appended.
Let’s consider some examples.
Sum -> ReLU
This pattern is pretty common for the CNN topologies of the ResNet family.
dnnl::post_ops po; po.append_sum(); po.append_eltwise( /* alg kind = */ dnnl::algorithm::eltwise_relu, /* neg slope = */ 0.f, /* unused for relu */ 0.f); dnnl::primitive_attr attr; attr.set_post_ops(po); convolution_forward::primitive_desc(conv_d, attr, engine);
This will lead to the following primitive behavior:
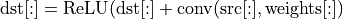
Tanh -> Sum -> ScaleShift
This is a hypothetical example that illustrates the sequence of operations applied. We also set all the scales to values other than 1.0 and use dnnl::primitive_attr::set_scales_mask which will be covered in Primitive Attributes: Quantization.
dnnl::post_ops po; po.append_eltwise( /* alg kind = */ dnnl::algorithm::eltwise_tanh, /* unused for tanh */ 0.f, /* unused for tanh */ 0.f); po.append_sum(); po.append_eltwise( /* alg kind = */ dnnl::algorithm::eltwise_linear, /* linear scale = */ alpha, /* linear shift = */ beta); dnnl::primitive_attr attr; attr.set_scales_mask(DNNL_ARG_SRC, 0); attr.set_scales_mask(DNNL_ARG_WEIGHTS, 0); attr.set_scales_mask(DNNL_ARG_DST, 0); attr.set_post_ops(po); convolution_forward::primitive_desc(conv_d, attr, engine);
This will lead to the following primitive behavior (for better readability the tensors are designated by their names only; i.e., [:] is omitted):
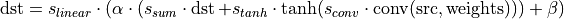
Relu -> Depthwise -> Relu
An example of fusing depthwise convolution with 1x1 convolution in MobileNet.
dnnl::post_ops po; po.append_eltwise( /* alg kind = */ dnnl::algorithm::eltwise_relu, /* neg slope = */ 0.f, /* unused for relu */ 0.f); po.append_dw( /* depthwise weights data type = */ dnnl::memory::data_type::s8, /* depthwise bias data type (undef implies no bias) = */ dnnl::memory::data_type::undef, /* depthwise destination data type = */ dnnl::memory::data_type::u8, /* kernel size of fused depthwise convolution = */ kernel, /* stride size of fused depthwise convolution = */ stride, /* padding size of fused depthwise convolution = */ padding) po.append_eltwise( /* alg kind = */ dnnl::algorithm::eltwise_relu, /* neg slope = */ 0.f, /* unused for relu */ 0.f); dnnl::primitive_attr attr; attr.set_scales_mask(DNNL_ARG_DST, 0); attr.set_scales_mask(DNNL_ARG_ATTR_POST_OP_DW | DNNL_ARG_DST, 0); attr.set_post_ops(po); auto cpd = convolution_forward::primitive_desc(conv_1x1, attr, engine); auto dw_weight_md = cpd.query(query::exec_arg_md, DNNL_ARG_ATTR_POST_OP_DW | DNNL_ARG_WEIGHTS); auto dw_bias_md = cpd.query(query::exec_arg_md, DNNL_ARG_ATTR_POST_OP_DW | DNNL_ARG_BIAS);
This will lead to the following primitive behaviour:
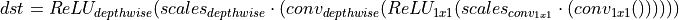
Binary
An example of fusing convolution with binary post-op with per channel addition.
dnnl::memory::desc conv_dst_md {MB, C, H, W}; /* 2D conv destination memory desc */ dnnl::post_ops po; /* Append eltwise post-op prior the binary post-op */ po.append_eltwise( /* alg kind = */ dnnl::algorithm::eltwise_relu, /* neg slope = */ 0.f, /* unused for relu */ 0.f); /* Note that `C` coincides with the one from `conv_dst_md`. Also note that only * supported memory format for src1 memory is `nchw` (or `abcd`) format. */ po.append_binary( /* alg kind = */ dnnl::algorithm::binary_add, /* src1_md = */ dnnl::memory::desc( {1, C, 1, 1}, dnnl::memory::data_type::f32, dnnl::memory::format_tag::abcd)); dnnl::primitive_attr attr; attr.set_post_ops(po); auto cpd = convolution_forward::primitive_desc(conv, attr, engine); /* To set memory argument for binary post-op, the following should take place: */ std::unordered_map<int, memory> args; args.insert(DNNL_ARG_SRC, conv_src_memory); ... int binary_post_op_position = 1; /* hard coded here, but may be queried */ args.insert( DNNL_ARG_ATTR_MULTIPLE_POST_OP(binary_post_op_position) | DNNL_ARG_SRC_1, /* note parentheses around index */ binary_post_op_src1_memory);