A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-95DBF9A7-D77A-49D7-B139-3F74677B1A11
Visible to Intel only — GUID: GUID-95DBF9A7-D77A-49D7-B139-3F74677B1A11
View Performance Inefficiencies of Data-parallel Constructs
The Statistics Tab also contains the efficiency information for each parallel construct if they are employed by the algorithm. This data will show up under the Parallel Efficiency tab in the Statistics group.
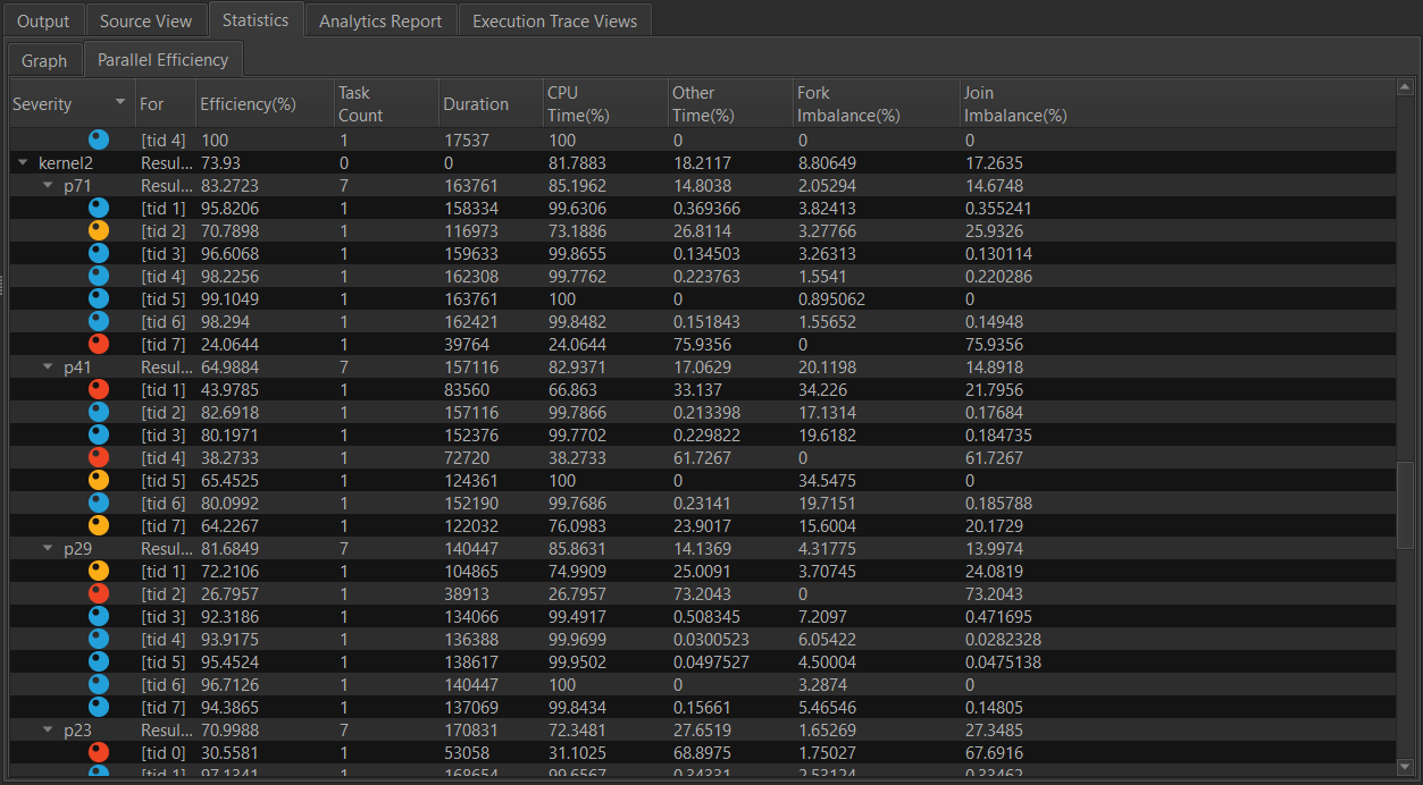
The data parallel construct efficiency for each instance of a kernel. The column provides information that is useful for understanding the execution, and makes inferences to improve performance.
- The parallel algorithms are nested under the kernel name when the kernel name can be demangled correctly.
- The Efficiency column indicates the efficiency of the algorithm, when associated with the algorithm name. For the participating worker threads, the efficiency column indicates the efficiency of the thread while participating in the execution. This data is typically derived from the total time spent on the parallel construct and the time the thread spent participating in other parallel constructs.
- Task Count column indicates the number of tasks executed by the participating thread.
- Duration indicates the time the participating thread spends executing tasks from the parallel construct.
- CPU time is the Duration column data expressed as a percentage of the wall clock time of the parallel construct.
- Other Time will be 0 if the thread fully participates in the execution of tasks from the parallel construct. However, in runtimes such as Intel® oneAPI Threading Building Blocks, the participating threads may steal tasks from other parallel constructs submitted to the device to provide better dynamic load balancing and throughput. In such cases, the Other Time column will indicate the percentage of the total wall clock time the participating thread spends executing tasks from other parallel constructs.
- Fork Imbalance indicates the penalty for waking up threads to participate in the execution of tasks from the parallel construct. For more information, see Startup Penalty.
- Join Imbalance indicates the degree of imbalanced execution of tasks from the parallel constructs by the participating worker threads. For more information, see Data Parallel Efficiency.