A newer version of this document is available. Customers should click here to go to the newest version.
Instruction Cache Misses
Profile an application bound on the front-end and reduce ICache misses using the Microarchitecture Exploration analysis with the PGO option.
Content Expert: Jeffrey Reinemann
Ingredients
This section lists the hardware and software tools used for the performance analysis scenario.
Application: A test sample based on the sqlite database. The application is used as a demo and not available for download.
Tools:
Intel® VTune™ Profiler version 2018 or newer - Microarchitecture Exploration analysis
Intel® DPC++/C++ Compiler
CPU: Intel® microarchitecture code named Skylake
Run Microarchitecture Exploration Analysis
Get an overall assessment of potential performance bottlenecks in the application. Run the Microarchitecture Exploration analysis:
In the Intel® VTune™ Profiler UI, click the
 New Project button on the toolbar. Specify a name for the new project, for example: sqlite.
New Project button on the toolbar. Specify a name for the new project, for example: sqlite. In the Analysis Target window, select the local host target system type for the host-based analysis.
Select the Launch Application target type and specify an application for analysis.
In the Analysis Tree, select Microarchitecture > Microarchitecture Exploration.
Click Start.
Intel® VTune™ Profiler launches the application and collects data. When the collection completes, Intel® VTune™ Profiler finalizes the result and resolves symbol information. This is necessary for proper source analysis.
Identify Hardware Hotspots
The Microarchitecture Exploration analysis helps you identify dominant performance bottlenecks in your code. Start your analysis with the Summary view. Here, you see application-level statistics for each hardware metric. Focus on the performance issues that have been flagged:
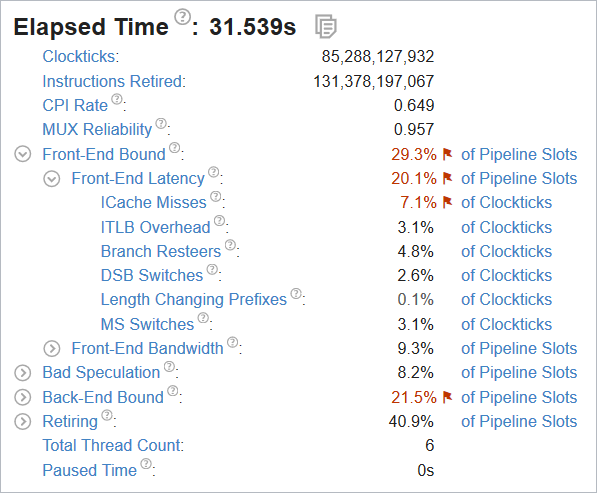
In this example, the sample application is front-end bound (29.3% of Pipeline Slots) with the instruction cache misses as a dominant bottleneck (7.1% of Clockticks).
Next, locate the issue in the code by switching to the Bottom-up window. Click the  Customize Grouping button, next to the Grouping toolbar. Create a new custom grouping called Module/Source File:
Customize Grouping button, next to the Grouping toolbar. Create a new custom grouping called Module/Source File:
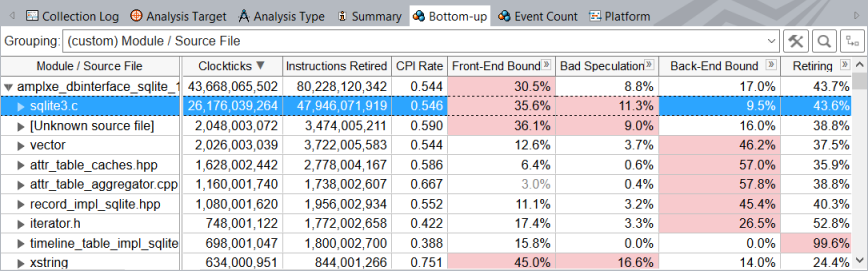
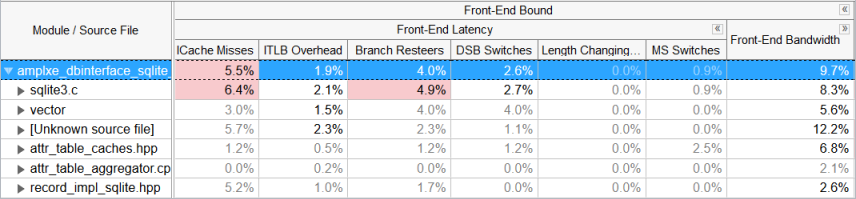
When we apply the new grouping to the collected results, we see that sqlite3.c file is the main hotspot which takes the most CPU cycles to execute:
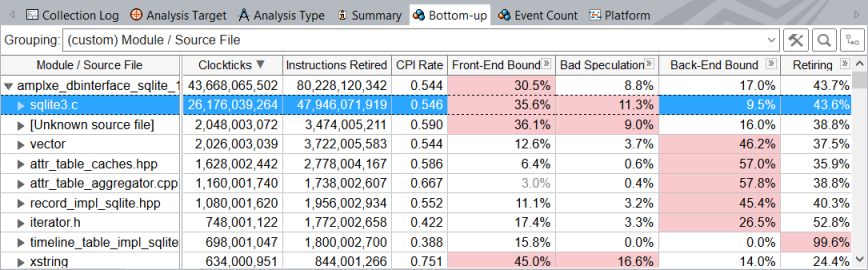
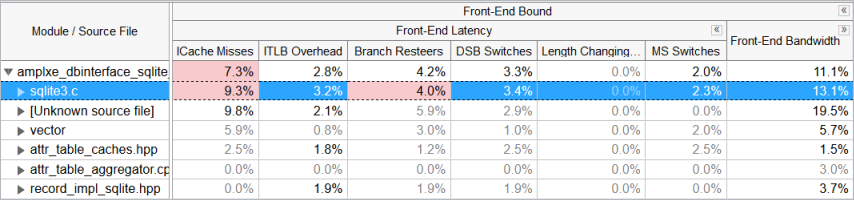
The ICache Misses metric displays the highest value for the sqlite3.c file:
Compile Your Code Again with Profile Guided Optimization
Use the Intel® DPC++/C++ Compiler to apply Profile Guided Optimization (PGO) to the sqlite library:
Compile your code once again with the /Qprof-gen option.
Run the benchmark.
Again, compile your code with the /Qprof-use option.
For more information on PGO, see the Profile-Guided Optimizations overview.
Verify Optimization
Repeat the Microarchitecture Exploration analysis on the optimized code. The new result shows 30.3 seconds of Elapsed time, which is almost 4% better than the original 31.5 seconds:

The number of clockticks stalled due to ICache Misses for the sqlite library has also reduced to 6.4% from 9.3%: