Compile a Portable Optimized Binary with the Latest Instruction Set
Learn how to compile a binary with the latest instruction set while maintaining portability.
Content expert: Jeffrey Reinemann
Modern Intel® processors support instruction set extensions like the different versions of Intel® Advanced Vector Extensions (Intel® AVX):
- AVX
- AVX2
- AVX-512
When you compile your application, consider these options based on the purpose of your application:
- Generic binary: Compile an application for the generic x86 instruction set. The application runs on all x86 processors, but may not utilize a newer processor to its full potential.
- Native binary: Compile an application for the specific processor. The application utilizes all features of the target processor but does run on older processors.
- Portable binary: Compile a portable optimized binary with multiple versions of functions. Each version is targeted for different processors using compiler options and function attributes. The resulting binary has the performance characteristics of an application compiled for a specific processor (native binary) and can run on older processors.
This recipe demonstrates how you can compile a portable binary with the performance characteristics of a native binary, while still maintaining portability of a generic binary. In this recipe, you compile both the generic and native binaries first to determine if the resulting performance improvement is large enough to justify the increase in binary size.
This recipe covers the Intel® C++ Compiler Classic and the GNU* Compiler Collection (GCC).
This recipe does not cover:
- Manual dispatching using the CPUID processor instruction
- Processor Targeting compiler options
- The target function attribute
Ingredients
This section lists the systems and tools used in the creation of this recipe:
- Processor: Intel® Core™ code named Skylake i7-6700 CPU @ 3.40GHz
- Operating System: Linux OS (Ubuntu 22.04.3 LTS with kernel version 6.2.0-35-generic)
- Compilers:
- Intel® C++ Compiler Classic 2024.0
- GCC version 11.4.0
- Analysis Tool :Intel® VTune™ Profiler version 2024.0 or newer
Sample Application
Save this code to a source file named fma.c:
Compile Generic Optimized Binary
Compile the binary following the recommendations from VTune Profiler User Guide (recommendations for Windows).
Intel® DPC++/C++ Compiler
Compile the binary with debug information and -O3 optimization level:
GNU Compiler Collection
Compile the binary with debug information and -O2 optimization level:
To check if the code was vectorized, use the HPC Performance Characterization analysis in VTune Profiler:
The output of this command includes information about vectorization:
Vectorization: 0.0% of Packed FP Operations Instruction Mix SP FLOPs: 16.4% of uOps Packed: 0.0% from SP FP 128-bit: 0.0% from SP FP 256-bit: 0.0% from SP FP Scalar: 100.0% from SP FP
Open the result in the VTune Profiler GUI:
Once you open the analysis result, in the Summary tab, see the Top Loops/Functions with FPU Usage by CPU Time section :
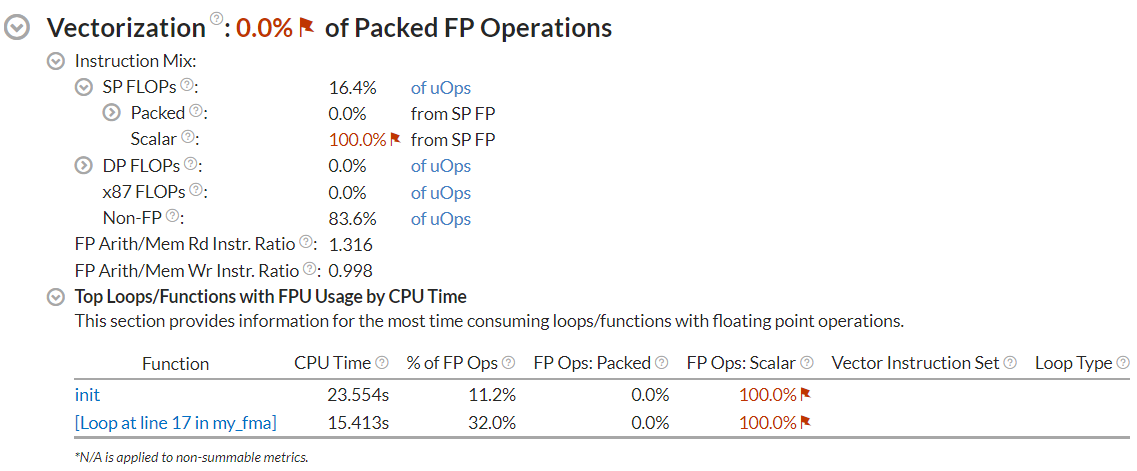
The fact that FP Ops: Scalar value equals 100% and that the Vector Instruction Set column is empty indicates that GCC does not vectorize the code at -O2 optimization level.
Use -O2 -ftree-vectorize or -O3 options to enable vectorization.
Compile the fma_generic binary with -O3 optimization level:
Collect the HPC Performance Characterization analysis data for the generic binary:
The output of this analysis includes the following information:
Vectorization: 100.0% of Packed FP Operations Instruction Mix SP FLOPs: 8.3% of uOps Packed: 100.0% from SP FP 128-bit: 100.0% from SP FP 256-bit: 0.0% from SP FP Scalar: 0.0% from SP FP
When you open the analysis result in the VTune Profiler GUI, you can find information about vectorization:
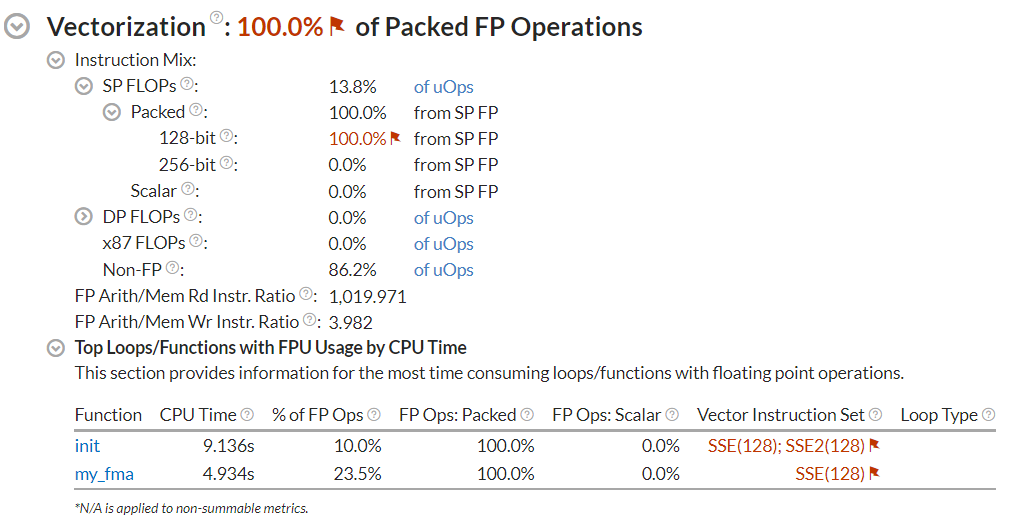
Compile Native Binary
Compile native binary with the Intel® DPC++/C++ Compiler
The -xHost option instructs the compiler to generate instructions for the highest instruction set available on the processor performing the compilation. Alternatively, the -x{Arch} option, where {Arch} is the architecture codename, instructs the compiler to target processor features of a specific architecture.
Compile the fma_native binary with -xHost flag:
Compile native binary with the GNU Compiler Collection
Compile the fma_native binary with -march=native flag:
If your processor supports the AVX-512 instruction set extension, consider experimenting with the mprefer-vector-width=512 option.
Next, collect HPC data for the native binary:
The output of this analysis includes the following information:
Vectorization: 100.0% of Packed FP Operations
Instruction Mix
SP FLOPs: 14.2% of uOps
Packed: 100.0% from SP FP
128-bit: 0.0% from SP FP
256-bit: 100.0% from SP FP
Scalar: 0.0% from SP FP
When you open the analysis result in the VTune Profiler GUI, you can find information about vectorization:
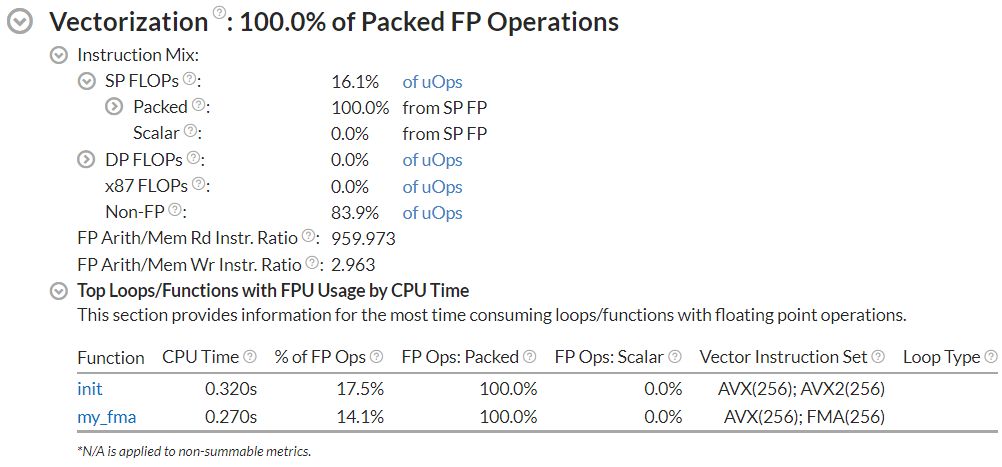
Compare Generic and Native Binaries
To compare the HPC data collected for the generic and native binaries, run this command:
In the VTune Profiler GUI, switch to the Bottom-Up tab. Set Loop Mode to Functions only.
Switch to the Summary tab and scroll down to the Top Loops/Functions with FPU Usage by CPU Time section:
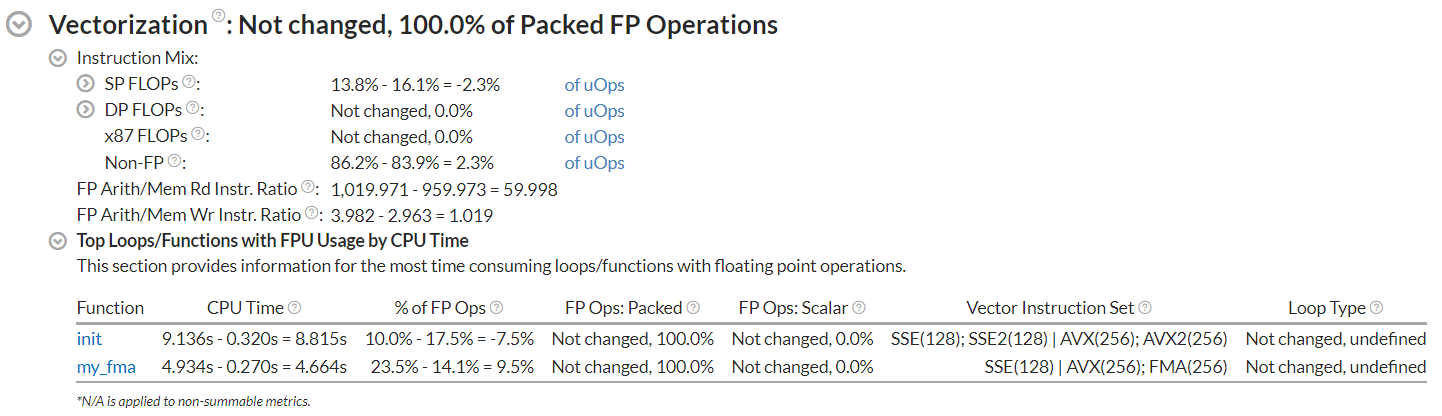
Observe the CPU Time and Vector Instruction Set columns.
Consider the performance difference between the generic and the native binary. Decide whether it makes sense to compile a portable binary with multiple code paths.
NOTE:
This sample application was auto-vectorized by the compiler. To investigate vectorization opportunities in your application in depth, use Intel® Advisor.
Compile Portable Binary
If the comparison between the generic and native binary shows a performance improvement, for example, if the CPU Time was improved, consider compiling a portable binary.
Compile the portable binary with the Intel® DPC++/C++ Compiler
Use the -ax (/Qax for Windows) option to instruct the compiler to generate multiple feature-specific auto-dispatch code paths for Intel processors.
Compile the fma_portable binary with the -ax option:
Refer to the -ax option help page for the list of supported architectures.
Compile the portable binary with the GNU Compiler Collection
Compare the results for generic and native binaries. If the CPU Time was improved and an additional Vector Instruction Set was utilized for a specific function in the native binary result, then add the target_clones attribute to this function.
If the function calls other functions, consider adding the flatten attribute to force inlining, since the target_clones attribute is not recursive.
Copy the contents of the fma.c source file to a new file, fma_portable.c, and add the TARGET_CLONE preprocessor macro:
Refer to the x86 Options page of the GCC manual for the list of supported architectures.
Multiple versions of a function will increase the binary size. Consider the trade-off between performance improvement for each target and code size. Collecting and comparing VTune Profiler results enables you to make data-driven decisions to apply the TARGET_CLONES macro only to the functions that will run faster with new instructions.
Add the TARGET_CLONES macro before the my_fma function definition and init functions and save the changes to fma_portable.c:
Compile the fma_portable binary:
Compare Portable and Native Binaries
To compare the performance of portable and optimized binaries, collect the HPC Performance Characterization data for the fma_portable binary:
The output of this analysis includes the following data:
Vectorization: 100.0% of Packed FP Operations
Instruction Mix
SP FLOPs: 6.9% of uOps
Packed: 100.0% from SP FP
128-bit: 66.7% from SP FP
256-bit: 33.3% from SP FP
Scalar: 0.0% from SP FP
Open the comparison in VTune Profiler GUI:

As a result, the portable binary uses the highest instruction set extension available and demonstrates optimal performance on the target system.
Parent topic: Methodologies