Visible to Intel only — GUID: GUID-5C0D5537-4B76-48FF-9AF3-192A8B42BFC8
What's New
Introduction to the Intel® oneAPI Math Kernel Library (oneMKL) BLAS and LAPACK with DPC++
Overview of Intel® oneMKL BLAS Routines for Data Parallel C++
Overview of Intel® oneAPI Math Kernel Library (oneMKL) Sparse BLAS for DPC++
Overview of Intel® oneMKL LAPACK Routines for Data Parallel C++
Data Types
Matrix Storage
Error Handling
BLAS Routines
Sparse BLAS Routines
LAPACK Routines
Vector Mathematical Functions
Random Number Generators
Summary Statistics
Fourier Transform Functions
Data Fitting
Bibliography
Appendix A: oneMKL Functionality
Notices and Disclaimers
Sparse BLAS Matrix Handle Contract between User and Library
Sparse BLAS Supported Data and Integer Types
Sparse Storage Formats
oneapi::mkl::sparse::init_matrix_handle
oneapi::mkl::sparse::release_matrix_handle
oneapi::mkl::sparse::set_csr_data
oneapi::mkl::sparse::set_matrix_property
oneapi::mkl::sparse::optimize_gemv
oneapi::mkl::sparse::optimize_trmv
oneapi::mkl::sparse::optimize_trsv
oneapi::mkl::sparse::gemv
oneapi::mkl::sparse::gemvdot
oneapi::mkl::sparse::symv
oneapi::mkl::sparse::trmv
oneapi::mkl::sparse::trsv
oneapi::mkl::sparse::gemm
oneapi::mkl::sparse::init_matmat_descr
oneapi::mkl::sparse::set_matmat_data
oneapi::mkl::sparse::get_matmat_data
oneapi::mkl::sparse::release_matmat_descr
oneapi::mkl::sparse::matmat
oneapi::mkl::sparse::omatcopy
oneapi::mkl::sparse::sort_matrix
gebrd
gebrd (USM Version)
gebrd_scratchpad_size
gels_batch (Buffer Strided Version)
gels_batch (USM Strided Version)
gels_batch_scratchpad_size (Strided Version)
geqrf
geqrf (USM Version)
geqrf_batch (Buffer Strided Version)
geqrf_batch (Group Version)
geqrf_batch (USM Strided Version)
geqrf_batch_scratchpad_size (Group Version)
geqrf_batch_scratchpad_size (Strided Version)
geqrf_scratchpad_size
gerqf
gerqf (USM Version)
gerqf_scratchpad_size
gesvd
gesvd (USM Version)
gesvd_scratchpad_size
getrf
getrf (USM Version)
getrf_batch (Buffer Strided Version)
getrf_batch (Group Version)
getrf_batch (USM Strided Version)
getrf_batch_scratchpad_size (Group Version)
getrf_batch_scratchpad_size (Strided Version)
getrf_scratchpad_size
getrfnp_batch (Buffer Strided Version)
getrfnp_batch (Group Version)
getrfnp_batch (USM Strided Version)
getrfnp_batch_scratchpad_size (Group Version)
getrfnp_batch_scratchpad_size (Strided Version)
getri
getri (USM Version)
getri_batch (Buffer Strided Version)
getri_batch (Group Version)
getri_batch (USM Strided Version)
getri_batch_scratchpad_size (Group Version)
getri_batch_scratchpad_size (Strided Version)
getri_batch (Out-of-place, Buffer Strided Version)
getri_batch (Out-of-place, USM Strided Version)
getri_batch_scratchpad_size (Strided Version)
getri_scratchpad_size
getrs
getrs (USM Version)
getrs_batch (Buffer Strided Version)
getrs_batch (Group Version)
getrs_batch (USM Strided Version)
getrs_batch_scratchpad_size (Group Version)
getrs_batch_scratchpad_size (Strided Version)
getrs_scratchpad_size
getrsnp_batch (Buffer Strided Version)
getrsnp_batch (USM Strided Version)
getrsnp_batch_scratchpad_size (Strided Version)
heevd
heevd (USM Version)
heevd_scratchpad_size
hegvd
hegvd (USM Version)
hegvd_scratchpad_size
hetrd
hetrd (USM Version)
hetrd_scratchpad_size
hetrf
hetrf (USM Version)
hetrf_scratchpad_size
orgbr
orgbr (USM Version)
orgbr_scratchpad_size
orgqr
orgqr (USM Version)
orgqr_batch (Buffer Strided Version)
orgqr_batch (Group Version)
orgqr_batch (USM Strided Version)
orgqr_batch_scratchpad_size (Group Version)
orgqr_batch_scratchpad_size (Strided Version)
orgqr_scratchpad_size
orgtr
orgtr (USM Version)
orgtr_scratchpad_size
ormqr
ormqr (USM Version)
ormqr_scratchpad_size
ormrq
ormrq (USM Version)
ormrq_scratchpad_size
ormtr
ormtr (USM Version)
ormtr_scratchpad_size
potrf
potrf (USM Version)
potrf_batch (Buffer Strided Version)
potrf_batch (Group Version)
potrf_batch (USM Strided Version)
potrf_batch_scratchpad_size (Group Version)
potrf_batch_scratchpad_size (Strided Version)
potrf_scratchpad_size
potri
potri (USM Version)
potri_scratchpad_size
potrs
potrs (USM Version)
potrs_batch (Buffer Strided Version)
potrs_batch (Group Version)
potrs_batch (USM Strided Version)
potrs_batch_scratchpad_size (Group Version)
potrs_batch_scratchpad_size (Strided Version)
potrs_scratchpad_size
syevd
syevd (USM Version)
syevd_scratchpad_size
sygvd
sygvd (USM Version)
sygvd_scratchpad_size
sytrd
sytrd (USM Version)
sytrd_scratchpad_size
sytrf
sytrf (USM Version)
sytrf_scratchpad_size
trtrs
trtrs (USM Version)
trtrs_scratchpad_size
ungbr
ungbr (USM Version)
ungbr_scratchpad_size
ungqr
ungqr (USM Version)
ungqr_batch (Buffer Strided Version)
ungqr_batch (Group Version)
ungqr_batch (USM Strided Version)
ungqr_batch_scratchpad_size (Group Version)
ungqr_batch_scratchpad_size (Strided Version)
ungqr_scratchpad_size
ungtr
ungtr (USM Version)
ungtr_scratchpad_size
unmqr
unmqr (USM Version)
unmqr_scratchpad_size
unmrq
unmrq (USM Version)
unmrq_scratchpad_size
unmtr
unmtr (USM Version)
unmtr_scratchpad_size
oneapi::mkl::rng::mrg32k3a
oneapi::mkl::rng::philox4x32x10
oneapi::mkl::rng::mcg31m1
oneapi::mkl::rng::mcg59
oneapi::mkl::rng::r250
oneapi::mkl::rng::wichmann_hill
oneapi::mkl::rng::mt19937
oneapi::mkl::rng::sfmt19937
oneapi::mkl::rng::mt2203
oneapi::mkl::rng::ars5
oneapi::mkl::rng::sobol
oneapi::mkl::rng::niederreiter
oneapi::mkl::rng::nondeterministic
Distributions Template Parameter Method
oneapi::mkl::rng::uniform (Continuous)
oneapi::mkl::rng::gaussian
oneapi::mkl::rng::exponential
oneapi::mkl::rng::laplace
oneapi::mkl::rng::weibull
oneapi::mkl::rng::cauchy
oneapi::mkl::rng::rayleigh
oneapi::mkl::rng::lognormal
oneapi::mkl::rng::gumbel
oneapi::mkl::rng::gamma
oneapi::mkl::rng::beta
oneapi::mkl::rng::chi_square
oneapi::mkl::rng::gaussian_mv
oneapi::mkl::rng::uniform (Discrete)
oneapi::mkl::rng::uniform_bits
oneapi::mkl::rng::bits
oneapi::mkl::rng::bernoulli
oneapi::mkl::rng::geometric
oneapi::mkl::rng::binomial
oneapi::mkl::rng::hypergeometric
oneapi::mkl::rng::poisson
oneapi::mkl::rng::poisson_v
oneapi::mkl::rng::negative_binomial
oneapi::mkl::rng::multinomial
oneapi::mkl::rng::device::uniform (Continuous)
oneapi::mkl::rng::device::gaussian
oneapi::mkl::rng::device::lognormal
oneapi::mkl::rng::device::exponential
oneapi::mkl::rng::device::uniform (Discrete)
oneapi::mkl::rng::device::bits
oneapi::mkl::rng::device::uniform_bits
oneapi::mkl::rng::device::poisson
oneapi::mkl::rng::device::bernoulli
oneapi::mkl::stats::raw_sum
oneapi::mkl::stats::central_sum
oneapi::mkl::stats::central_sum with User-provided Mean
oneapi::mkl::stats::raw_moment
oneapi::mkl::stats::central_moment
oneapi::mkl::stats::central_moment with User-provided Mean
oneapi::mkl::stats::mean
oneapi::mkl::stats::variation
oneapi::mkl::stats::variation with User-provided Mean
oneapi::mkl::stats::skewness
oneapi::mkl::stats::skewness with User-provided Mean
oneapi::mkl::stats::kurtosis
oneapi::mkl::stats::kurtosis with User-provided Mean
oneapi::mkl::stats::min
oneapi::mkl::stats::max
oneapi::mkl::stats::min_max
descriptor<precision, domain>
descriptor<precision, domain>::set_value
descriptor<precision, domain>::get_value
descriptor<precision, domain>::commit
compute_forward<typename descriptor_type, typename data_type>
compute_backward<typename descriptor_type, typename data_type>
User-Allocated Workspaces
Visible to Intel only — GUID: GUID-5C0D5537-4B76-48FF-9AF3-192A8B42BFC8
axpy_batch
Computes a group of axpy operations.
Description
The axpy_batch routines are batched versions of axpy, performing multiple axpy operations in a single call. Each axpy operation adds a scalar-vector product to a vector.
axpy_batch supports the following precisions:
T |
|---|
float |
double |
std::complex<float> |
std::complex<double> |
axpy_batch (Buffer Version)
Buffer version of axpy_batch supports only strided API.
Strided API
Strided API operation is defined as:
for i = 0 … batch_size – 1
X and Y are vectors at offset i * stridex and i * stridey in x and y
Y = alpha * X + Y
end for
where:
alpha is scalar
X and Y are vectors
For strided API, all vectors X and Y have same parameters (size, increments) and are stored at constant stride given by stridex and stridey from each other. The x and y arrays contain all the input vectors. Total number of vectors in x and y are given by batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major {
void axpy_batch(sycl::queue &queue,
std::int64_t n,
T alpha,
sycl::buffer<T, 1> &x,
std::int64_t incx,
std::int64_t stridex,
sycl::buffer<T, 1> &y,
std::int64_t incy,
std::int64_t stridey,
std::int64_t batch_size)
}
namespace oneapi::mkl::blas::row_major {
void axpy_batch(sycl::queue &queue,
std::int64_t n,
T alpha,
sycl::buffer<T, 1> &x,
std::int64_t incx,
std::int64_t stridex,
sycl::buffer<T, 1> &y,
std::int64_t incy,
std::int64_t stridey,
std::int64_t batch_size)
}
Input Parameters
- queue
-
The queue where the routine should be executed.
- n
-
Number of elements in vectors X and Y.
- alpha
-
Specifies the scalar alpha.
- x
-
Buffer holding input vectors X. Size of the buffer must be at least batch_size * stridex.
- incx
-
Stride between two consecutive elements of X vectors. Must not be zero.
- stridex
-
Stride between two consecutive X vectors. Must be at least zero.
- y
-
Buffer holding input/output vectors Y. Size of the buffer must be at least batch_size * stridey.
- incy
-
Stride between two consecutive elements of Y vectors. Must not be zero.
- stridey
-
Stride between two consecutive Y vectors. Must be at least (1 + (n-1)*abs(incy)). See Matrix Storage for more details.
- batch_size
-
Number of axpy computations to perform. Must be at least zero.
Output Parameters
- y
-
Output buffer overwritten by batch_sizeaxpy operations of the form alpha * X + Y.
axpy_batch (USM Version)
USM version of axpy_batch supports group API and strided API.
Group API
Group API operation is defined as:
idx = 0
for i = 0 … group_count – 1
for j = 0 … group_size – 1
X and Y are vectors at x[idx] and y[idx]
Y = alpha[i] * X + Y
idx = idx + 1
end for
end for
where:
alpha is scalar
X and Y are vectors
For group API, each group contains vectors with the same parameters (size and increment). The x and y arrays contain the pointers for all the input vectors. Total number of vectors in x and y are given by:
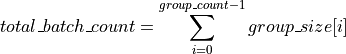
Syntax
namespace oneapi::mkl::blas::column_major {
sycl::event axpy_batch(sycl::queue &queue,
const std::int64_t *n,
const T *alpha,
const T **x,
const std::int64_t *incx,
T **y,
const std::int64_t *incy,
std::int64_t group_count,
const std::int64_t *group_size,
const std::vector<sycl::event> &dependencies = {})
}
namespace oneapi::mkl::blas::row_major {
sycl::event axpy_batch(sycl::queue &queue,
const std::int64_t *n,
const T *alpha,
const T **x,
const std::int64_t *incx,
T **y,
const std::int64_t *incy,
std::int64_t group_count,
const std::int64_t *group_size,
const std::vector<sycl::event> &dependencies = {})
}
Input Parameters
- queue
-
The queue where the routine should be executed.
- n
-
Array of group_count integers. n[i] specifies number of elements in vectors X and Y for every vector in group i.
- alpha
-
Array of group_count scalar elements. alpha[i] specifies scaling factor for vector X in group i.
- x
-
Array of pointers to input vectors X with size total_batch_count. Size of the array allocated for the X vector of the group i must be at least (1 + (n[i] – 1)*abs(incx[i])). See Matrix Storage for more details.
- incx
-
Array of group_count integers. incx[i] specifies stride of vector X in group i. Must not be zero.
- y
-
Array of pointers to input/output vectors Y with size total_batch_count. Size of the array allocated for the Y vector of the group i must be at least (1 + (n[i] – 1)*abs(incy[i])). See Matrix Storage for more details.
- incy
-
Array of group_count integers. incy[i] specifies the stride of vector Y in group i. Must not be zero.
- group_count
-
Number of groups. Must be at least zero.
- group_size
-
Array of group_count integers. group_size[i] specifies the number of axpy operations in group i. Each element in group_size must be at least zero.
- dependencies
-
List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
Output Parameters
- y
-
Array of pointers holding Y vectors, overwritten by total_batch_countaxpy operations of the form alpha * X + Y.
Return Values
Output event to wait on to ensure computation is complete.
Strided API
Strided API operation is defined as:
for i = 0 … batch_size – 1
X and Y are vectors at offset i * stridex and i * stridey in x and y
Y = alpha * X + Y
end for
where:
alpha is scalar
X and Y are vectors
For strided API, all vectors X and Y have same parameters (size, increments) and are stored at constant stride given by stridex and stridey from each other. The x and y arrays contain all the input vectors. Total number of vectors in x and y are given by batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major {
sycl::event axpy_batch(sycl::queue &queue,
std::int64_t n,
T alpha,
const T *x,
std::int64_t incx,
std::int64_t stridex,
T *y,
std::int64_t incy,
std::int64_t stridey,
std::int64_t batch_size,
const std::vector<sycl::event> &dependencies = {})
}
namespace oneapi::mkl::blas::row_major {
sycl::event axpy_batch(sycl::queue &queue,
std::int64_t n,
T alpha,
const T *x,
std::int64_t incx,
std::int64_t stridex,
T *y,
std::int64_t incy,
std::int64_t stridey,
std::int64_t batch_size,
const std::vector<sycl::event> &dependencies = {})
}
Input Parameters
- queue
-
The queue where the routine should be executed.
- n
-
Number of elements in vectors X and Y.
- alpha
-
Specifies the scalar alpha.
- x
-
Pointer to input vectors X. Size of the array must be at least batch_size * stridex.
- incx
-
Stride between two consecutive elements of X vectors. Must not be zero.
- stridex
-
Stride between two consecutive X vectors. Must be at least zero.
- y
-
Pointer to input/output vectors Y. Size of the array must be at least batch_size * stridey.
- incy
-
Stride between two consecutive elements of Y vectors. Must not be zero.
- stridey
-
Stride between two consecutive Y vectors. Must be at least (1 + (n-1)*abs(incy)). See Matrix Storage for more details.
- batch_size
-
Number of axpy computations to perform. Must be at least zero.
- dependencies
-
List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
Output Parameters
- y
-
Pointer to output vectors Y overwritten by batch_sizeaxpy operations of the form alpha * X + Y.
Return Values
Output event to wait on to ensure computation is complete.