Visible to Intel only — GUID: GUID-1CB19E10-05B5-4DF2-BCD2-B69017D8879A
Getting Help and Support
What's New
Notational Conventions
Overview
OpenMP* Offload
BLAS and Sparse BLAS Routines
LAPACK Routines
ScaLAPACK Routines
Sparse Solver Routines
Extended Eigensolver Routines
Vector Mathematical Functions
Statistical Functions
Fourier Transform Functions
PBLAS Routines
Partial Differential Equations Support
Nonlinear Optimization Problem Solvers
Support Functions
BLACS Routines
Data Fitting Functions
Appendix A: Linear Solvers Basics
Appendix B: Routine and Function Arguments
Appendix C: Specific Features of Fortran 95 Interfaces for LAPACK Routines
Appendix D: FFTW Interface to Intel® Math Kernel Library
Appendix E: Code Examples
Appendix F: oneMKL Functionality
Bibliography
Glossary
Notices and Disclaimers
mkl_?csrgemv
mkl_?bsrgemv
mkl_?coogemv
mkl_?diagemv
mkl_?csrsymv
mkl_?bsrsymv
mkl_?coosymv
mkl_?diasymv
mkl_?csrtrsv
mkl_?bsrtrsv
mkl_?cootrsv
mkl_?diatrsv
mkl_cspblas_?csrgemv
mkl_cspblas_?bsrgemv
mkl_cspblas_?coogemv
mkl_cspblas_?csrsymv
mkl_cspblas_?bsrsymv
mkl_cspblas_?coosymv
mkl_cspblas_?csrtrsv
mkl_cspblas_?bsrtrsv
mkl_cspblas_?cootrsv
mkl_?csrmv
mkl_?bsrmv
mkl_?cscmv
mkl_?coomv
mkl_?csrsv
mkl_?bsrsv
mkl_?cscsv
mkl_?coosv
mkl_?csrmm
mkl_?bsrmm
mkl_?cscmm
mkl_?coomm
mkl_?csrsm
mkl_?cscsm
mkl_?coosm
mkl_?bsrsm
mkl_?diamv
mkl_?skymv
mkl_?diasv
mkl_?skysv
mkl_?diamm
mkl_?skymm
mkl_?diasm
mkl_?skysm
mkl_?dnscsr
mkl_?csrcoo
mkl_?csrbsr
mkl_?csrcsc
mkl_?csrdia
mkl_?csrsky
mkl_?csradd
mkl_?csrmultcsr
mkl_?csrmultd
Naming Conventions in Inspector-Executor Sparse BLAS Routines
Sparse Matrix Storage Formats for Inspector-executor Sparse BLAS Routines
Supported Inspector-executor Sparse BLAS Operations
Two-stage Algorithm in Inspector-Executor Sparse BLAS Routines
Matrix Manipulation Routines
Inspector-Executor Sparse BLAS Analysis Routines
Inspector-Executor Sparse BLAS Execution Routines
mkl_sparse_?_create_csr
mkl_sparse_?_create_csc
mkl_sparse_?_create_coo
mkl_sparse_?_create_bsr
mkl_sparse_copy
mkl_sparse_destroy
mkl_sparse_convert_csr
mkl_sparse_convert_bsr
mkl_sparse_?_export_csr
mkl_sparse_?_export_csc
mkl_sparse_?_export_bsr
mkl_sparse_?_set_value
mkl_sparse_?_update_values
mkl_sparse_order
mkl_sparse_?_lu_smoother
mkl_sparse_?_mv
mkl_sparse_?_trsv
mkl_sparse_?_mm
mkl_sparse_?_trsm
mkl_sparse_?_add
mkl_sparse_spmm
mkl_sparse_?_spmmd
mkl_sparse_sp2m
mkl_sparse_?_sp2md
mkl_sparse_sypr
mkl_sparse_?_syprd
mkl_sparse_?_symgs
mkl_sparse_?_symgs_mv
mkl_sparse_syrk
mkl_sparse_?_syrkd
mkl_sparse_?_dotmv
mkl_sparse_?_sorv
?axpy_batch
?axpy_batch_strided
?axpby
?gem2vu
?gem2vc
?gemmt
?gemm3m
?gemm_batch
?gemm_batch_strided
?gemm3m_batch_strided
?gemm3m_batch
?trsm_batch
?trsm_batch_strided
mkl_?imatcopy
mkl_?imatcopy_batch
mkl_?imatcopy_batch_strided
mkl_?omatadd_batch_strided
mkl_?omatcopy
mkl_?omatcopy_batch
mkl_?omatcopy_batch_strided
mkl_?omatcopy2
mkl_?omatadd
?gemm_pack_get_size, gemm_*_pack_get_size
?gemm_pack
gemm_*_pack
?gemm_compute
gemm_*_compute
?gemm_free
gemm_*
?gemv_batch_strided
?gemv_batch
?dgmm_batch_strided
?dgmm_batch
mkl_jit_create_?gemm
mkl_jit_get_?gemm_ptr
mkl_jit_destroy
Naming Conventions for LAPACK Routines
Fortran 95 Interface Conventions for LAPACK Routines
Matrix Storage Schemes for LAPACK Routines
Mathematical Notation for LAPACK Routines
Error Analysis
LAPACK Linear Equation Routines
LAPACK Least Squares and Eigenvalue Problem Routines
LAPACK Auxiliary Routines
LAPACK Utility Functions and Routines
LAPACK Test Functions and Routines
Additional LAPACK Routines (Included for Compatibility with Netlib LAPACK)
Matrix Factorization: LAPACK Computational Routines
Solving Systems of Linear Equations: LAPACK Computational Routines
Estimating the Condition Number: LAPACK Computational Routines
Refining the Solution and Estimating Its Error: LAPACK Computational Routines
Matrix Inversion: LAPACK Computational Routines
Matrix Equilibration: LAPACK Computational Routines
?getrf
?getrf_batch
?getrf_batch_strided
Syntax
Include Files
Description
Input Parameters
Output Parameters
Related Information
mkl_?getrfnp
?getrfnp_batch_strided
mkl_?getrfnpi
?getrf2
?getri_oop_batch
?getri_oop_batch_strided
?gbtrf
?gttrf
?dttrfb
?potrf
?potrf2
?pstrf
?pftrf
?pptrf
?pbtrf
?pttrf
?sytrf
?sytrf_aa
?sytrf_rook
?sytrf_rk
?hetrf
?hetrf_aa
?hetrf_rook
?hetrf_rk
?sptrf
?hptrf
mkl_?spffrt2, mkl_?spffrtx
Orthogonal Factorizations: LAPACK Computational Routines
Singular Value Decomposition: LAPACK Computational Routines
Symmetric Eigenvalue Problems: LAPACK Computational Routines
Generalized Symmetric-Definite Eigenvalue Problems: LAPACK Computational Routines
Nonsymmetric Eigenvalue Problems: LAPACK Computational Routines
Generalized Nonsymmetric Eigenvalue Problems: LAPACK Computational Routines
Generalized Singular Value Decomposition: LAPACK Computational Routines
Cosine-Sine Decomposition: LAPACK Computational Routines
Linear Least Squares (LLS) Problems: LAPACK Driver Routines
Generalized Linear Least Squares (LLS) Problems: LAPACK Driver Routines
Symmetric Eigenvalue Problems: LAPACK Driver Routines
Nonsymmetric Eigenvalue Problems: LAPACK Driver Routines
Singular Value Decomposition: LAPACK Driver Routines
Cosine-Sine Decomposition: LAPACK Driver Routines
Generalized Symmetric Definite Eigenvalue Problems: LAPACK Driver Routines
Generalized Nonsymmetric Eigenvalue Problems: LAPACK Driver Routines
?lacgv
?lacrm
?lacrt
?laesy
?rot
?spmv
?spr
?syconv
?symv
?syr
i?max1
?sum1
?gbtf2
?gebd2
?gehd2
?gelq2
?gelqt3
?geql2
?geqr2
?geqr2p
?geqrt2
?geqrt3
?gerq2
?gesc2
?getc2
?getf2
?gtts2
?isnan
?laisnan
?labrd
?lacn2
?lacon
?lacpy
?ladiv
?lae2
?laebz
?laed0
?laed1
?laed2
?laed3
?laed4
?laed5
?laed6
?laed7
?laed8
?laed9
?laeda
?laein
?laev2
?laexc
?lag2
?lags2
?lagtf
?lagtm
?lagts
?lagv2
?lahqr
?lahrd
?lahr2
?laic1
?lakf2
?laln2
?lals0
?lalsa
?lalsd
?lamrg
?lamswlq
?lamtsqr
?laneg
?langb
?lange
?langt
?lanhs
?lansb
?lanhb
?lansp
?lanhp
?lanst/?lanht
?lansy
?lanhe
?lantb
?lantp
?lantr
?lanv2
?lapll
?lapmr
?lapmt
?lapy2
?lapy3
?laqgb
?laqge
?laqhb
?laqp2
?laqps
?laqr0
?laqr1
?laqr2
?laqr3
?laqr4
?laqr5
?laqsb
?laqsp
?laqsy
?laqtr
?laqz0
?lar1v
?lar2v
?laran
?larf
?larfb
?larfg
?larfgp
?larft
?larfx
?larfy
?large
?largv
?larnd
?larnv
?laror
?larot
?larra
?larrb
?larrc
?larrd
?larre
?larrf
?larrj
?larrk
?larrr
?larrv
?lartg
?lartgp
?lartgs
?lartv
?laruv
?larz
?larzb
?larzt
?las2
?lascl
?lasd0
?lasd1
?lasd2
?lasd3
?lasd4
?lasd5
?lasd6
?lasd7
?lasd8
?lasd9
?lasda
?lasdq
?lasdt
?laset
?lasq1
?lasq2
?lasq3
?lasq4
?lasq5
?lasq6
?lasr
?lasrt
?lassq
?lasv2
?laswlq
?laswp
?lasy2
?lasyf
?lasyf_aa
?lasyf_rook
?lahef
?lahef_aa
?lahef_rook
?latbs
?latm1
?latm2
?latm3
?latm5
?latm6
?latme
?latmr
?latdf
?latps
?latrd
?latrs
?latrz
?latsqr
?lauu2
?lauum
?orbdb1/?unbdb1
?orbdb2/?unbdb2
?orbdb3/?unbdb3
?orbdb4/?unbdb4
?orbdb5/?unbdb5
?orbdb6/?unbdb6
?org2l/?ung2l
?org2r/?ung2r
?orgl2/?ungl2
?orgr2/?ungr2
?orm2l/?unm2l
?orm2r/?unm2r
?orml2/?unml2
?ormr2/?unmr2
?ormr3/?unmr3
?pbtf2
?potf2
?ptts2
?rscl
?syswapr
?heswapr
?syswapr1
?sygs2/?hegs2
?sytd2/?hetd2
?sytf2
?sytf2_rook
?hetf2
?hetf2_rook
?tgex2
?tgsy2
?trti2
clag2z
dlag2s
slag2d
zlag2c
?larfp
ila?lc
ila?lr
?gsvj0
?gsvj1
?sfrk
?hfrk
?tfsm
?lansf
?lanhf
?tfttp
?tfttr
?tplqt2
?tpqrt2
?tprfb
?tpttf
?tpttr
?trttf
?trttp
?pstf2
dlat2s
zlat2c
?lacp2
?la_gbamv
?la_gbrcond
?la_gbrcond_c
?la_gbrcond_x
?la_gbrfsx_extended
?la_gbrpvgrw
?la_geamv
?la_gercond
?la_gercond_c
?la_gercond_x
?la_gerfsx_extended
?la_heamv
?la_hercond_c
?la_hercond_x
?la_herfsx_extended
?la_herpvgrw
?la_lin_berr
?la_porcond
?la_porcond_c
?la_porcond_x
?la_porfsx_extended
?la_porpvgrw
?laqhe
?laqhp
?larcm
?la_gerpvgrw
?larscl2
?lascl2
?la_syamv
?la_syrcond
?la_syrcond_c
?la_syrcond_x
?la_syrfsx_extended
?la_syrpvgrw
?la_wwaddw
mkl_?tppack
mkl_?tpunpack
Additional LAPACK Routines
Systems of Linear Equations: ScaLAPACK Computational Routines
Matrix Factorization: ScaLAPACK Computational Routines
Solving Systems of Linear Equations: ScaLAPACK Computational Routines
Estimating the Condition Number: ScaLAPACK Computational Routines
Refining the Solution and Estimating Its Error: ScaLAPACK Computational Routines
Matrix Inversion: ScaLAPACK Computational Routines
Matrix Equilibration: ScaLAPACK Computational Routines
Orthogonal Factorizations: ScaLAPACK Computational Routines
Symmetric Eigenvalue Problems: ScaLAPACK Computational Routines
Nonsymmetric Eigenvalue Problems: ScaLAPACK Computational Routines
Singular Value Decomposition: ScaLAPACK Driver Routines
Generalized Symmetric-Definite Eigenvalue Problems: ScaLAPACK Computational Routines
b?laapp
b?laexc
b?trexc
p?lacgv
p?max1
pilaver
pmpcol
pmpim2
?combamax1
p?sum1
p?dbtrsv
p?dttrsv
p?gebal
p?gebd2
p?gehd2
p?gelq2
p?geql2
p?geqr2
p?gerq2
p?getf2
p?labrd
p?lacon
p?laconsb
p?lacp2
p?lacp3
p?lacpy
p?laevswp
p?lahrd
p?laiect
p?lamve
p?lange
p?lanhs
p?lansy, p?lanhe
p?lantr
p?lapiv
p?lapv2
p?laqge
p?laqr0
p?laqr1
p?laqr2
p?laqr3
p?laqr4
p?laqr5
p?laqsy
p?lared1d
p?lared2d
p?larf
p?larfb
p?larfc
p?larfg
p?larft
p?larz
p?larzb
p?larzc
p?larzt
p?lascl
p?lase2
p?laset
p?lasmsub
p?lasrt
p?lassq
p?laswp
p?latra
p?latrd
p?latrs
p?latrz
p?lauu2
p?lauum
p?lawil
p?org2l/p?ung2l
p?org2r/p?ung2r
p?orgl2/p?ungl2
p?orgr2/p?ungr2
p?orm2l/p?unm2l
p?orm2r/p?unm2r
p?orml2/p?unml2
p?ormr2/p?unmr2
p?pbtrsv
p?pttrsv
p?potf2
p?rot
p?rscl
p?sygs2/p?hegs2
p?sytd2/p?hetd2
p?trord
p?trsen
p?trti2
?lahqr2
?lamsh
?lapst
?laqr6
?lar1va
?laref
?larrb2
?larrd2
?larre2
?larre2a
?larrf2
?larrv2
?lasorte
?lasrt2
?stegr2
?stegr2a
?stegr2b
?stein2
?dbtf2
?dbtrf
?dttrf
?dttrsv
?pttrsv
?steqr2
?trmvt
pilaenv
pilaenvx
pjlaenv
Additional ScaLAPACK Routines
oneMKL PARDISO - Parallel Direct Sparse Solver Interface
Parallel Direct Sparse Solver for Clusters Interface
Direct Sparse Solver (DSS) Interface Routines
Iterative Sparse Solvers based on Reverse Communication Interface (RCI ISS)
Preconditioners based on Incomplete LU Factorization Technique
Sparse Matrix Checker Routines
pardiso
pardisoinit
pardiso_64
mkl_pardiso_pivot
pardiso_getdiag
pardiso_export
pardiso_handle_store
pardiso_handle_restore
pardiso_handle_delete
pardiso_handle_store_64
pardiso_handle_restore_64
pardiso_handle_delete_64
oneMKL PARDISO Parameters in Tabular Form
pardiso iparm Parameter
PARDISO_DATA_TYPE
vslNewStream
vslNewStreamEx
vsliNewAbstractStream
vsldNewAbstractStream
vslsNewAbstractStream
vslDeleteStream
vslCopyStream
vslCopyStreamState
vslSaveStreamF
vslLoadStreamF
vslSaveStreamM
vslLoadStreamM
vslGetStreamSize
vslLeapfrogStream
vslSkipAheadStream
vslSkipAheadStreamEx
vslGetStreamStateBrng
vslGetNumRegBrngs
Convolution and Correlation Naming Conventions
Convolution and Correlation Data Types
Convolution and Correlation Parameters
Convolution and Correlation Task Status and Error Reporting
Convolution and Correlation Task Constructors
Convolution and Correlation Task Editors
Task Execution Routines
Convolution and Correlation Task Destructors
Convolution and Correlation Task Copiers
Convolution and Correlation Usage Examples
Convolution and Correlation Mathematical Notation and Definitions
Convolution and Correlation Data Allocation
Summary Statistics Naming Conventions
Summary Statistics Data Types
Summary Statistics Parameters
Summary Statistics Task Status and Error Reporting
Summary Statistics Task Constructors
Summary Statistics Task Editors
Summary Statistics Task Computation Routines
Summary Statistics Task Destructor
Summary Statistics Usage Examples
Summary Statistics Mathematical Notation and Definitions
DFTI_PRECISION
DFTI_FORWARD_DOMAIN
DFTI_DIMENSION, DFTI_LENGTHS
DFTI_PLACEMENT
DFTI_FORWARD_SCALE, DFTI_BACKWARD_SCALE
DFTI_NUMBER_OF_USER_THREADS
DFTI_THREAD_LIMIT
DFTI_INPUT_STRIDES, DFTI_OUTPUT_STRIDES
DFTI_NUMBER_OF_TRANSFORMS
DFTI_INPUT_DISTANCE, DFTI_OUTPUT_DISTANCE
DFTI_COMPLEX_STORAGE, DFTI_REAL_STORAGE, DFTI_CONJUGATE_EVEN_STORAGE
DFTI_PACKED_FORMAT
DFTI_WORKSPACE
DFTI_COMMIT_STATUS
DFTI_ORDERING
Data Fitting Function Naming Conventions
Data Fitting Function Data Types
Mathematical Conventions for Data Fitting Functions
Data Fitting Usage Model
Data Fitting Usage Examples
Data Fitting Function Task Status and Error Reporting
Data Fitting Task Creation and Initialization Routines
Task Configuration Routines
Data Fitting Computational Routines
Data Fitting Task Destructors
DSS Symmetric Matrix Storage
DSS Nonsymmetric Matrix Storage
DSS Structurally Symmetric Matrix Storage
DSS Distributed Symmetric Matrix Storage
Sparse BLAS CSR Matrix Storage Format
Sparse BLAS CSC Matrix Storage Format
Sparse BLAS Coordinate Matrix Storage Format
Sparse BLAS Diagonal Matrix Storage Format
Sparse BLAS Skyline Matrix Storage Format
Sparse BLAS BSR Matrix Storage Format
Visible to Intel only — GUID: GUID-1CB19E10-05B5-4DF2-BCD2-B69017D8879A
?getrf_batch_strided
Computes the LU factorization of a group of general m-by-n matrices that are stored at a constant stride from each other in a contiguous block of memory.
Syntax
call sgetrf_batch_strided(m, n, A, lda, stride_a, ipiv, stride_ipiv, batch_size, info)
call dgetrf_batch_strided(m, n, A, lda, stride_a, ipiv, stride_ipiv, batch_size, info)
call cgetrf_batch_strided(m, n, A, lda, stride_a, ipiv, stride_ipiv, batch_size, info)
call zgetrf_batch_strided(m, n, A, lda, stride_a, ipiv, stride_ipiv, batch_size, info)
Include Files
mkl.fi
Description
The ?getrf_batch_strided routines are similar to the ?getrf counterparts, but instead compute the LU factorization for a group of general m-by-n matrices.
All matrices have the same parameters (matrix size, leading dimension) and are stored at constant stride_a from each other in a contiguous block of memory. Their respective pivot arrays associated with each of the LU-factored Ai matrices are stored at constant stride_ipiv from each other. The operation is defined as
for i = 0 … batch_size-1 Ai is a matrix at offset i * stride_a from A ipivi is an array at offset i * stride_ipiv from ipiv Ai := Pi * Li* Ui end for
where Pi is a permutation matrix, Li is lower triangular with unit diagonal elements (lower trapezoidal if m> n) and Ui is upper triangular (upper trapezoidal if m< n). The routine uses partial pivoting, with row interchanges.
Input Parameters
- m
-
INTEGER. The number of rows in the A matrices: m ≥ 0.
- n
-
INTEGER. The number of columns in the A matrices: n ≥ 0.
- A
-
REAL for sgetrf_batch_strided
DOUBLE PRECISION for dgetrf_batch_strided
COMPLEX for cgetrf_batch_strided
DOUBLE COMPLEX for zgetrf_batch_strided
The A array of size at least stride_a * batch_size holding the Ai matrices.
- lda
-
INTEGER. Specifies the leading dimension of the Ai matrices; lda ≥ max(1,m).
- stride_a
-
INTEGER.
Stride between two consecutive Ai matrices; stride_a ≥ lda * n.
- stride_ipiv
-
INTEGER.
Stride between two consecutive pivot arrays; stride_ipiv ≥ min(m, n).
- batch_size
-
INTEGER.
Number of Ai matrices to be factorized. Must be at least 0.
Output Parameters
- A
-
Array holding the LU-factored Ai matrices. Each matrix is overwritten by their respective Li and Ui factors. The unit diagonal elements of L are not stored.
- ipiv
-
INTEGER
Array of size at least stride_ipiv * batch_size holding the pivot array associated with each of the LU-factored Ai matrices. The pivot array ipivi contains the pivot indices associated with matrix Ai; for 1 ≤ j ≤ min(m,n), row j was interchanged with row ipivi(j).
- info
-
INTEGER.
Array of size at least batch_size, which reports the factorization status for each matrix.
If info(i) = 0, the execution is successful for Ai.
If info(i) = -j, the j-th parameter had an illegal value for Ai.
If info(i) = j, the j-th diagonal element of Ui is 0. The factorization has been completed, but Ui is exactly singular. Division by 0 will occur if you use the factor Ui for solving a system of linear equations.
After calling this routine with m=n, you can call the following:
to solve systems of linear equations of the form 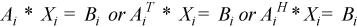 with the group of LU-factored matrices.
with the group of LU-factored matrices.
Related Information
See ?getrf_batch, which computes the LU factorization for a group of general m-by-n matrices that are allocated at a constant stride from each other in the same contiguous block of memory.
Parent topic: Matrix Factorization: LAPACK Computational Routines