A newer version of this document is available. Customers should click here to go to the newest version.
oneapi::mkl::sparse::omatadd
Computes general sparse matrix-sparse matrix addition with sparse matrix output.
Description
The oneapi::mkl::sparse::omatadd set of routines perform general sparse matrix-sparse matrix addition, defined as
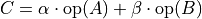
where  ,
, 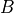 , and
, and 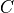 are sparse matrices with mathematically consistent sizes and
are sparse matrices with mathematically consistent sizes and 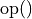 is a matrix modifier:
is a matrix modifier:
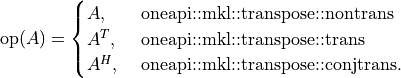
The sparse matrices are stored in sparse::matrix_handle_t objects.
The output matrix is not guaranteed to be sorted on exit from sparse::omatadd(), but a helper function sparse::sort_matrix() is provided if that is a necessary property for subsequent usage.
The input matrices, and , need not be sorted for use with these APIs. However, if users guarantee that both the input matrices are sorted either by calling sparse::sort_matrix() on the matrices beforehand, or by using the sparse::set_matrix_property() API to set the sparse::property::sorted property on the matrices, then that may significantly improve the performance of the omatadd APIs.
As the sparsity pattern of and the size of its data arrays is generally not known beforehand, the omatadd routine is broken into several stages with different API names to enable querying the size of the temporary workspace and size of the resulting data arrays, allocating them, and passing them back into the routine to be filled. This enables users to control and own all the matrix data allocations. Unlike the sparse::matmat() API, however, the omatadd routines currently do not support addition involving only the sparsity patterns without any floating point values. The sparse::omatadd() set of APIs is broken into four APIs involving two lightweight and two computationally expensive stages given below:
Stage |
Description |
|---|---|
omatadd_buffer_size |
Return size of temporary workspace. |
omatadd_analyze |
Count the number of non-zero values (nnzC) in the output sparse matrix. |
omatadd_get_nnz |
Return the calculated nnzC count of the output sparse matrix. |
omatadd |
Perform union of sparsity pattern and floating point accumulations into into user-provided arrays of the output sparse matrix. |
Stages
-
- Before omatadd stages
-
Use the sparse::set_<xyz>_data API with dummy arguments for row, column, and data arrays to set the sparse matrix format and the output 0-/1-based indexing. The number of rows and columns of the matrix may either be set to zero, or be mathematically consistent with the input matrix sizes at this stage.
Create the omatadd_descr_t object using the init_omatadd_descr API and decide on an algorithm to use through the enum, omatadd_alg. Do not change this enum between calls to the different omatadd APIs with a given set of input arguments and descriptor.
-
- omatadd_buffer_size stage
-
This is a non-blocking host-side API that does not access the input matrix arrays.
Use the omatadd_buffer_size API to get the temporary workspace size.
Allocate the temporary workspace to be used in subsequent stages.
-
- omatadd_analyze stage
-
This is a non-blocking asynchronous API that accesses and analyzes the sparsity patterns of the input matrices.
Use the omatadd_analyze API with the temporary workspace allocated in the previous stage.
The temporary workspace array is internally stored in the omatadd_descr_t object. Do not modify or free the workspace for the duration of its use for sparse matrix addition or for the lifetime of the omatadd_descr_t object.
-
- omatadd_get_nnz stage
-
Use this blocking API to get the number of non-zeros in the
matrix.Allocate the row, column, and data arrays of the
matrix.Call the sparse::set_<xyz>_data API again, this time with the valid, newly allocated arrays of
. At this point, the output 0-/1-based indexing must not be changed, and the number of rows and columns of the matrix must be mathematically consistent with the input matrix sizes for the operation.
-
- omatadd stage
-
Call the non-blocking, asynchronous omatadd API to perform the union of the sparsity pattern and floating point accumulations to fill in the user-provided output
matrix arrays.
-
- After omatadd stages
-
Release the omatadd_descr_t object using the release_omatadd_descr API. Reusing the descriptor for another addition operation is currently undefined behavior, but may be enabled in a future oneMKL release.
Release the temporary workspace array, or if the omatadd_descr_t object has been released, then reuse the workspace for any other purpose.
Release or use
matrix handle for subsequent operations.If sorted output is needed for subsequent calls to other oneMKL APIs, then call the sparse::sort_matrix() API for sorting the output matrix arrays.
An example of this workflow for sparse matrix addition is demonstrated in the oneMKL SYCL examples listed later below.
API
Syntax
enum omatadd_alg
The omatadd_algenum provides users a choice of using specifc algorithms implemented in oneMKL. Currently, only one algorithm is available to users. This enum is defined as:
namespace oneapi::mkl::sparse {
enum class omatadd_alg : std::int32_t {
default_alg = 0
};
}omatadd_descr_t object
omatadd_descr_t is an operation-specific opaque descriptor object used to store the internal state between calls to the omatadd set of APIs. Once a given descriptor object is used in any of the APIs, it must not be changed or free’d until all calls to omatadd APIs are completed. A pointer to the user-provided temporary workspace is stored in this descriptor object through one of the omatadd set of APIs, viz., omatadd_analyze, described below. There are initialization and release functions associated with this descriptor object.
namespace oneapi::mkl::sparse {
struct omatadd_descr; /* Forward declaration of opaque omatadd operation descriptor */
typedef omatadd_descr *omatadd_descr_t; /* User-facing type for use in omatadd APIs */
/* Host-side/non-blocking */
void init_omatadd_descr(sycl::queue &queue,
omatadd_descr_t *p_descr);
/* Asynchronous/non-blocking */
sycl::event release_omatadd_descr(sycl::queue &queue,
omatadd_descr_t descr,
const std::vector<sycl::event> &dependencies = {});
}omatadd APIs
namespace oneapi::mkl::sparse {
/* Combined USM/sycl::buffer API, host-side/non-blocking */
void omatadd_buffer_size(sycl::queue &queue,
transpose opA,
transpose opB,
matrix_handle_t A, /* oneMKL Input sparse matrix handle */
matrix_handle_t B, /* oneMKL Input sparse matrix handle */
matrix_handle_t C, /* oneMKL Output sparse matrix handle */
omatadd_alg alg,
omatadd_descr_t descr, /* omatadd operation descriptor */
std::int64_t &sizeTempWorkspace); /* Size of temporary workspace */
/* sycl::buffer API, asynchronous/non-blocking */
void omatadd_analyze(sycl::queue &queue,
transpose opA,
transpose opB,
matrix_handle_t A,
matrix_handle_t B,
matrix_handle_t C,
omatadd_alg alg,
omatadd_descr_t descr,
sycl::buffer<std::uint8_t, 1> *tempWorkspace); /* Temporary workspace */
/* USM API, asynchronous/non-blocking */
sycl::event omatadd_analyze(sycl::queue &queue,
transpose opA,
transpose opB,
matrix_handle_t A,
matrix_handle_t B,
matrix_handle_t C,
omatadd_alg alg,
omatadd_descr_t descr,
void *tempWorkspace, /* Temporary workspace */
const std::vector<sycl::event> &dependencies = {});
/* Combined USM/sycl::buffer API, synchronous/blocking */
void omatadd_get_nnz(sycl::queue &queue,
transpose opA,
transpose opB,
matrix_handle_t A,
matrix_handle_t B,
matrix_handle_t C,
omatadd_alg alg,
omatadd_descr_t descr,
std::int64_t &nnzC, /* Returned non-zero count of C matrix */
const std::vector<sycl::event> &dependencies = {});
/* Combined USM/sycl::buffer API, asynchronous/non-blocking */
sycl::event omatadd(sycl::queue &queue,
transpose opA,
transpose opB,
const DATA_TYPE alpha, /* A-scaling factor */
matrix_handle_t A,
const DATA_TYPE beta, /* B-scaling factor */
matrix_handle_t B,
matrix_handle_t C, /* User arrays filled */
omatadd_alg alg,
omatadd_descr_t descr,
const std::vector<sycl::event> &dependencies = {});
}Include Files
oneapi/mkl/spblas.hpp
API Parameters
Input Parameters
- queue
-
Specifies the SYCL command queue to be used for execution of SYCL kernels.
- opA, opB
-
Specifies operation op() on input matrices,
and , as one of the oneapi::mkl::transpose enums. All combinations of opA and opB are supported. - alpha, beta
-
Specifies the scalars,
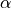 and
and 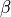 , to scale
, to scale 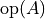 and
and 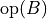 matrices, respectively.
matrices, respectively. - A, B
-
The matrix handles of the input sparse matrices being added.
and need not be in a sorted state as input to omatadd APIs, but performance may significantly benefit from it if the sparse::sort_matrix() API has been called on both the matrices, or if the sparse::set_matrix_property() API has been called on both the matrices to set the sorted property to guarantee sorted user input. The order of and must not be changed across API calls.NOTE:Only the CSR matrix format is currently supported for and
.
- alg
-
The omatadd_alg enum specifying choice of algorithm to use for the operation. For a given set of inputs and descriptor, alg must not be changed across API calls.
- descr
-
The omatadd_descr_t descriptor object storing input data, operation-specific information, and user-provided temporary workspace. It is created and destroyed using the sparse::init_omatadd_descr, sparse::release_omatadd_descr routines.
- p_descr
-
Pointer to the omatadd_descr_t descriptor object, descr, used for allocating it.
- tempWorkspace
-
A SYCL-aware container (sycl::buffer or device-accessible USM pointer) of size sizeTempWorkspace bytes used as a temporary workspace for the matrix addition operation. The workspace must remain valid through the full omatadd multi-stage calls and must not be modified between matrix addition API calls or for the lifetime of descr.
For sycl::buffer inputs, tempWorkspace is of type sycl::buffer<std::uint8_t> *.
For USM inputs, tempWorkspace is a void * pointer that must be device-accessible. The recommended USM memory type for this is USM device for best performance, but USM shared and USM host allocations are also supported as they are device accessible.
- dependencies
-
A vector of type const std::vector<sycl::event> & containing the list of events that the routine being called depends on to complete first, if any.
Input/Output Parameters
- C
-
The input/output matrix handle for the omatadd operation. The 0- or 1-based indexing parameter set in the
matrix handle is an input to the omatadd operation. The sparse matrix arrays are user-allocated and user-owned, and are stored in the matrix handle using one of the sparse::set_<xyz>_data routines. The library fills the data as part of the omatadd operation. The output matrix arrays are not guaranteed to be sorted.NOTE:Only the CSR matrix format is currently supported for.
NOTE:If sorted output data is needed, then separately call the sparse::sort_matrix() API after the final sparse::omatadd API call.NOTE:Aliasing the matrix handle or arrays with either of the input
and
handles or their arrays (therefore attempting an “in-place” addition operation) is undefined behavior.
Output Parameters
- sizeTempWorkspace
-
An integer of type std::int64_t containing the size in bytes of the temporary workspace, tempWorkspace, that the user must allocate for omatadd calls. This parameter is obtained from the omatadd_buffer_size API.
- nnzC
-
An integer of type std::int64_t containing the format specific number of non-zeros in the output
matrix, to be used by users to allocate and own the output matrix arrays. This parameter is obtained from the omatadd_get_nnz API.
Return types where applicable
- sycl::event
-
SYCL event that can be waited upon, and in case of USM APIs, must be carried over and added as a dependency for the completion of subsequent stages of the omatadd routines.
Examples
Some examples of how to use oneapi::mkl::sparse::omatadd with SYCL buffers or USM can be found in the oneMKL installation directory, under:
share/doc/mkl/examples/sycl/sparse_blas/source/csr_omatadd.cppshare/doc/mkl/examples/sycl/sparse_blas/source/csr_omatadd_usm.cpp