A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-F651F4D6-34EF-4B78-AA46-3330BBCC33E1
Visible to Intel only — GUID: GUID-F651F4D6-34EF-4B78-AA46-3330BBCC33E1
gemv_batch
Computes a group of gemv operations.
Description
The gemv_batch routines are batched versions of gemv, performing multiple gemv operations in a single call. Each gemv operations perform a scalar-matrix-vector product and add the result to a scalar-vector product.
gemv_batch supports the following precisions:
T |
|---|
float |
double |
std::complex<float> |
std::complex<double> |
gemv_batch (Buffer Version)
Buffer version of gemv_batch supports only strided API.
Strided API
Strided API operation is defined as:
for i = 0 … batch_size – 1 A is a matrix at offset i * stridea in a. X and Y are vctors at offset i * stridex, i * stridey, in x and y. Y = alpha * op(A) * X + beta * Y end for
where:
op(A) is one of op(A) = A, or op(A) = AT, or op(A) = AH
alpha and beta are scalars
A is matrix and X and Y are vectors
For strided API, x and y buffers contain all the input vectors. The stride between vectors is either given by the stride parameters. Total number of vectors in x and y buffers is given by batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major { void gemv_batch(sycl::queue &queue, oneapi::mkl::transpose trans, std::int64_t m, std::int64_t n, T alpha, sycl::buffer<T,1> &a, std::int64_t lda, std::int64_t stridea, sycl::buffer<T,1> &x, std::int64_t incx, std::int64_t stridex, T beta, sycl::buffer<T,1> &y, std::int64_t incy, std::int64_t stridey, std::int64_t batch_size) }
namespace oneapi::mkl::blas::row_major { void gemv_batch(sycl::queue &queue, oneapi::mkl::transpose trans, std::int64_t m, std::int64_t n, T alpha, sycl::buffer<T,1> &a, std::int64_t lda, std::int64_t stridea, sycl::buffer<T,1> &x, std::int64_t incx, std::int64_t stridex, T beta, sycl::buffer<T,1> &y, std::int64_t incy, std::int64_t stridey, std::int64_t batch_size) }
Input Parameters
- queue
-
The queue where the routine should be executed.
- trans
-
Specifies op(A), the transposition operation applied to matrices A. See Data Types for more details.
- m
-
Number of rows of matrices op(A). Must be at least zero.
- n
-
Number of columns of matrices op(A). Must be at least zero.
- alpha
-
Scaling factor for matrix-vector product.
- a
-
The buffer holding input matrices A. Size of the buffer must be at least stridea * batch_size.
- lda
-
Leading dimension of matrices A. Must be positive and at least m if column major layout or at least n if row major layout is used.
- stridea
-
Stride between two consecutive A matrices. Must be at least zero.
- x
-
Buffer holding input vectors X. Size of the buffer must be at least stridex * batch_size.
- incx
-
Stride between two consecutive elements of X vectors. Must not be zero.
- stridex
-
Stride between two consecutive X vectors. Must be at least zero.
- beta
-
Scaling factor for vectors Y.
- y
-
Buffer holding input/output vectors Y. Size of the buffer must be at least stridey * batch_size.
- incy
-
Stride between two consecutive elements of Y vectors. Must not be zero.
- stridey
-
Stride between two consecutive Y vectors. Must be at least (1 + (m - 1)*abs(incy)) if layout is column major or (1 + (n - 1)*abs(incy)) if row major layout is used.
- batch_size
-
Number of gemv computations to perform. Must be at least zero.
Output Parameters
- y
-
Output buffer overwritten by batch_sizegemv operations of the form alpha * op(A) * X + beta * Y.
gemv_batch (USM Version)
USM version of gemv_batch supports the group API and the strided API.
Group API
The type Ti of integer pointers in the group API may be either std::int64_t or std::int32_t.
Group API operation is defined as:
idx = 0 for i = 0 … group_count – 1 for j = 0 … group_size – 1 A is an m x n matrix in a[idx] X and Y are vectors in x[idx] and y[idx] Y = alpha[i] * op(A) * X + beta[i] * Y idx = idx + 1 end for end for
where:
op(A) is one of op(A) = A, or op(A) = AT, or op(A) = AH
alpha and beta are scalars
A is matrix and X and Y are vectors
For group API, x and y arrays contain the pointers for all the input vectors. a array contains the pointers to all input matrices. The total number of vectors in x and y and matrices in a is given by:
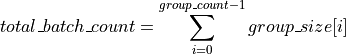
Syntax
namespace oneapi::mkl::blas::column_major { sycl::event gemv_batch(sycl::queue &queue, const oneapi::mkl::transpose *trans, const Ti *m, const Ti *n, const T *alpha, const T **a, const Ti *lda, const T **x, const Ti *incx, const T *beta, T **y, const Ti *incy, std::int64_t group_count, const Ti *group_size, const std::vector<sycl::event> &dependencies = {}) }
namespace oneapi::mkl::blas::row_major { sycl::event gemv_batch(sycl::queue &queue, const oneapi::mkl::transpose *trans, const Ti *m, const Ti *n, const T *alpha, const T **a, const Ti *lda, const T **x, const Ti *incx, const T *beta, T **y, const Ti *incy, std::int64_t group_count, const Ti *group_size, const std::vector<sycl::event> &dependencies = {}) }
Input Parameters
- queue
-
The queue where the routine should be executed.
- trans
-
Array of group_countoneapi::mkl::transpose values. transa[i] specifies op(A), the transposition operation applied to matrices A in group i. See Data Types for more details.
- m
-
Array of group_count integers. m[i] specifies number of rows of matrices op(A) in group i. All entries must be at least zero.
- n
-
Array of group_count integers. n[i] specifies number of columns of matrices op(A) in group i. All entries must be at least zero.
- alpha
-
Array of group_count scalar elements. alpha[i] specifies scaling factor for matrix-vector products in group i.
- a
-
Array of total_batch_count pointers for input matrices A. See Matrix Storage for more details.
- lda
-
Array of group_count integers. lda[i] specifies leading dimension of matrices A in group i. Must be positive and at least m[i] if column major layout or at least n[i] if row major layout is used.
- x
-
Array of total_batch_count pointers for input vectors X. See Matrix Storage for more details.
- incx
-
Array of group_count integers. incx[i] specifies stride of vectors X in group i. Must not be zero.
- beta
-
Array of group_count scalar elements. beta[i] specifies scaling factor for vectors Y in group i.
- y
-
Array of total_batch_count pointers for input/output vectors Y. See Matrix Storage for more details.
- incy
-
Array of group_count integers. incy[i] specifies stride of vectors Y in group i. Must not be zero.
- group_count
-
Number of groups. Must be at least zero.
- group_size
-
Array of group_count integers. group_size[i] specifies the number of gemv operations in group i. Each element in group_size must be at least zero.
- dependencies
-
List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
Output Parameters
- y
-
Array of pointers to output vectors Y overwritten by total_batch_countgemv operations of the form alpha * op(A) * X + beta * Y.
Return Values
Output event to wait on to ensure computation is complete.
Examples
An example of how to use USM version of gemv_batch can be found in oneMKL installation directory, under:
share/doc/mkl/examples/sycl/blas/source/gemv_batch_usm.cpp
Strided API
Strided API operation is defined as:
for i = 0 … batch_size – 1 A is a matrix at offset i * stridea in a. X and Y are vctors at offset i * stridex, i * stridey, in x and y. Y = alpha * op(A) * X + beta * Y end for
where:
op(A) is one of op(A) = A, or op(A) = AT, or op(A) = AH
alpha and beta are scalars
A is matrix and X and Y are vectors
For strided API, x and y arrays contain all the input vectors. The stride between vectors is given by the stride parameters. Total number of vectors in x and y arrays is given by batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major { sycl::event gemv_batch(sycl::queue &queue, oneapi::mkl::transpose trans, std::int64_t m, std::int64_t n, oneapi::mkl::value_or_pointer<T> alpha, const T *a, std::int64_t lda, std::int64_t stridea, const T *x, std::int64_t incx, std::int64_t stridex, oneapi::mkl::value_or_pointer<T> beta, T *y, std::int64_t incy, std::int64_t stridey, std::int64_t batch_size) }
namespace oneapi::mkl::blas::row_major { sycl::event gemv_batch(sycl::queue &queue, oneapi::mkl::transpose trans, std::int64_t m, std::int64_t n, oneapi::mkl::value_or_pointer<T> alpha, const T *a, std::int64_t lda, std::int64_t stridea, const T *x, std::int64_t incx, std::int64_t stridex, oneapi::mkl::value_or_pointer<T> beta, T *y, std::int64_t incy, std::int64_t stridey, std::int64_t batch_size) }
Input Parameters
- queue
-
The queue where the routine should be executed.
- trans
-
Specifies op(A), the transposition operation applied to matrices A. See Data Types for more details.
- m
-
Number of rows of matrices op(A). Must be at least zero.
- n
-
Number of columns of matrices op(A). Must be at least zero.
- alpha
-
Scaling factor for matrix-vector product. See Scalar Arguments for more information on the value_or_pointer data type.
- a
-
Pointer to input matrices A. Size of the array must be at least stridea * batch_size.
- lda
-
Leading dimension of matrices A. Must be positive and at least m if column major layout or at least n if row major layout is used.
- stridea
-
Stride between two consecutive A matrices. Must be at least zero.
- x
-
Pointer to input vectors X. Size of the array must be at least stridex * batch_size.
- incx
-
Stride between two consecutive elements of X vectors. Must not be zero.
- stridex
-
Stride between two consecutive X vectors. Must be at least zero.
- beta
-
Scaling factor for vectors Y. See Scalar Arguments for more information on the value_or_pointer data type.
- y
-
Pointer to input/output vectors Y. Size of the array must be at least stridey * batch_size.
- incy
-
Stride between two consecutive elements of Y vectors. Must not be zero.
- stridey
-
Stride between two consecutive Y vectors. Must be at least (1 + (m - 1)*abs(incy)) if layout is column major or (1 + (n - 1)*abs(incy)) if row major layout is used.
- batch_size
-
Number of gemv computations to perform. Must be at least zero.
- dependencies
-
List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
Output Parameters
- y
-
Pointer to output vectors Y overwritten by batch_sizegemv operations of the form alpha * op(A) * X + beta * Y.
Return Values
Output event to wait on to ensure computation is complete.